
Stop pretending your associates enjoy redlining indemnification clauses at 11 PM. They don’t. Manual contract review is a slow, error-prone bottleneck that exposes the firm to risk and burns out your junior talent. The fix isn’t another subscription to a feel-good AI platform. The fix is a disciplined, engineering-first approach to gutting the process and replacing it with verifiable automation. Forget the sales pitches. This is the ground truth on how you build a system that works.
Decontaminating Your Source Material
Before you write a single line of code or demo a single vendor, you must confront your data hygiene. Most firms have a contract repository that looks like a digital landfill. It is a chaotic mix of scanned PDFs, .doc files from 2007, and email threads. An AI model fed this garbage will produce garbage outputs. The first, non-negotiable step is to force a single source of truth.
This means getting all contracts into a structured system, whether it’s a dedicated CLM, a DMS like iManage, or even a strictly governed SharePoint site. Each document needs to be text-searchable. For older scanned agreements, this requires running them through an Optical Character Recognition engine. Be prepared for disappointment. OCR is not magic. It will bungle complex tables, misread faded text, and introduce artifacts. You need a human validation step to clean the OCR output before it ever touches an analysis model. Building a sophisticated automation stack on a foundation of messy, unreliable source documents is like trying to build a skyscraper on a swamp. The whole structure will eventually sink.
Your goal is a clean, queryable dataset of contracts. Without this, all further effort is a waste of time and money.
Choosing the Analysis Engine
The market is flooded with contract AI tools, most wrapped in layers of marketing nonsense. To cut through it, you need to understand the two fundamental architectures: rule-based systems and machine learning models. A rule-based engine is essentially a very powerful find-and-replace script. You define specific keywords or phrases, and the system flags them. It’s predictable, fast, and completely blind to any variation it hasn’t been explicitly programmed to find. It will find “Limitation of Liability” but miss “Liability will be limited to”.
Machine learning models are trained on massive datasets of existing contracts to recognize patterns and concepts. They can identify a limitation of liability clause even if it uses novel wording. The power comes at a cost. ML models can be opaque “black boxes,” making it hard to debug why a certain classification was made. They are also computationally expensive, which translates to a higher price tag and potentially sluggish API response times. They are also prone to “hallucinations,” confidently misidentifying clauses in a way a human never would.
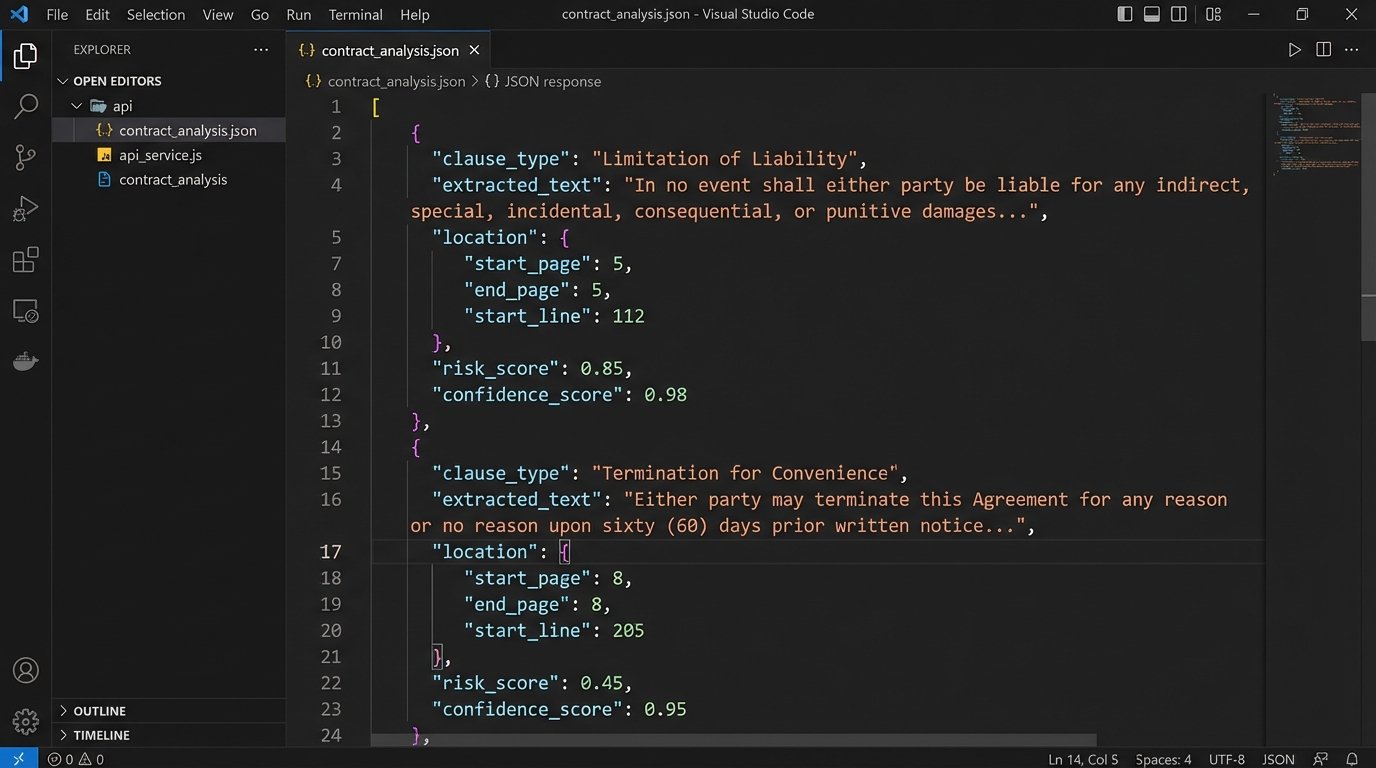
The critical factor in your decision is the API. If a vendor does not provide a well-documented, stable REST API for submitting documents and retrieving structured data, walk away. A pretty user interface is useless for real automation. You need to be able to programmatically inject a contract and get back a machine-readable JSON object detailing the findings. Anything less is a toy, not a tool. A closed system you can’t integrate is just another information silo waiting to become obsolete.
The Integration Points
A standalone analysis tool is an island. Its value is only realized when it is bridged into your core legal workflows. This integration work is where most projects fail. The goal is to create a seamless pipeline: a new contract is saved to the DMS, a webhook fires, the document is sent to the analysis API, and the results are injected back as metadata or pushed into a matter management system as a task for an attorney.
This requires scripting. You are the plumber connecting mismatched pipes between legacy systems and modern cloud services. Your primary tools will be Python scripts, PowerShell, or a dedicated integration platform like Workato or MuleSoft. For example, a Python script to send a document from a local folder to a hypothetical “ClauseGuard” API would be the first building block.
Here is a simplified example of what that initial API call looks like using Python’s `requests` library. This is the absolute minimum you need to get working.
import requests
import json
API_ENDPOINT = "https://api.clauseguard.com/v2/analyze"
API_KEY = "YOUR_API_KEY_HERE"
FILE_PATH = "C:/contracts/pending/MSA_AcmeCorp_2023.docx"
headers = {
"Authorization": f"Bearer {API_KEY}",
}
with open(FILE_PATH, "rb") as f:
files = {"document": (FILE_PATH, f, "application/vnd.openxmlformats-officedocument.wordprocessingml.document")}
try:
response = requests.post(API_ENDPOINT, headers=headers, files=files, timeout=120)
response.raise_for_status() # This will raise an exception for HTTP errors
# The API should return structured data, like JSON
analysis_results = response.json()
print("Analysis Successful. Key findings:")
for finding in analysis_results.get("findings", []):
if finding.get("risk_score") > 7:
print(f"- High Risk Clause: {finding.get('clause_type')}")
print(f" Text: {finding.get('extracted_text')[:100]}...")
except requests.exceptions.RequestException as e:
print(f"API call failed: {e}")
The next step is parsing the JSON response. The API doesn’t just say “there’s a problem.” It should return structured data identifying the clause type, the exact text, its location in the document, and a confidence score. Your job is to map this data to actions. A “Governing Law” clause specifying Nevada might be fine, but one specifying North Korea needs to trigger a five-alarm fire. This logic-checking is what separates true automation from a simple notification system.
You have to force the data from one system’s format into another. This is often like shoving a firehose of unstructured text through the needle-sized input of a structured database field. Data will be lost or truncated if you don’t build proper handlers.
Constructing the Review Playbook
The technology is useless without a defined legal strategy. An automation “playbook” is the set of instructions that tells the system what to look for and what to do when it finds it. This is not a technical task. It requires sitting down with senior lawyers and codifying their institutional knowledge into a set of machine-readable rules.
Start with the basics. Don’t try to automate the review of a complex M&A agreement on day one. Pick a high-volume, relatively standardized contract type like a Non-Disclosure Agreement or a simple Master Services Agreement. Identify the top 3-5 “must-check” clauses. These are typically:
- Governing Law & Jurisdiction
- Limitation of Liability
- Indemnification
- Confidentiality Term
- Assignment
For each clause, define the acceptable parameters. For Governing Law, is “State of Delaware” acceptable? Yes. Is “State of California”? Maybe, but flag for review. Is any other jurisdiction? Red flag, high priority. This logic gets built into the post-processing of the API results. The AI finds the clause, and your internal script applies the firm’s playbook to classify it. This two-step process gives you control and prevents total reliance on the vendor’s black-box risk scores.
The Human-in-the-Loop Imperative
No current AI can be trusted to review a contract without human supervision. The goal is augmentation, not replacement. You must build a validation workflow. When the system flags a high-risk clause, it should create a task in your matter management system and assign it to a specific attorney. The task must contain a direct link to the document and the specific text of the problematic clause.
The attorney’s review serves two purposes. First, it’s a critical quality control check to prevent an automated mistake from becoming a legal disaster. Second, it generates feedback data. The attorney should be able to confirm or correct the AI’s finding with a single click. “Yes, this was a high-risk indemnification clause” or “No, this was misidentified.” This feedback is gold. It must be logged and used to either fine-tune your internal playbook rules or, if your vendor’s platform supports it, to retrain the underlying ML model. Without this feedback loop, your model’s accuracy will stagnate or even degrade over time.
You should also architect for ambiguity. If the analysis API returns a confidence score below a certain threshold, say 85%, your system should automatically route the document for full manual review, regardless of what the findings say. It is far cheaper to have a lawyer spend 15 minutes on a document the AI was unsure about than to litigate a bad clause that the automation missed.

Maintenance is Not Optional
Launching the system is not the end of the project. It’s the beginning of a new operational responsibility. AI models drift. As new legal language and contract structures emerge, the model’s performance on them will degrade unless it is continuously retrained on new data. You must monitor this. Track key metrics: What is the average confidence score? What percentage of findings are overridden by attorneys? If that percentage starts creeping up, your model needs attention.
Vendor APIs will also change. They will deprecate v1 for v2, breaking your integration script unless you are paying attention. Your legal playbooks will need updating as laws and firm policies evolve. This is not a static piece of software. It is a living system that requires a dedicated owner. Treating it as a one-off IT project guarantees it will be broken and useless within 18 months. This automation is a garden that must be tended, not a monument that can be built and ignored.
The operational cost of this monitoring and maintenance is real. It demands developer time and lawyer oversight. Firms that bake these ongoing costs into the initial ROI calculation are the ones who succeed. Those who ignore them are setting themselves up for a very expensive failure.