
Most legal tech articles read like marketing brochures. They promise a frictionless future while ignoring the reality of production environments. The truth is that bolting new technology onto a law firm’s existing infrastructure is a messy, expensive process. These are not turnkey solutions. They are complex systems that demand careful architecture and a deep understanding of their limitations. What follows is not a list of shiny objects, but a breakdown of technical shifts that require actual engineering effort.
1. Fine-Tuned LLMs for Contract Review
Generative AI is the current obsession. The standard approach involves piping contract text to a public API from OpenAI or Anthropic. This is fast, lazy, and a massive data security risk. Sending client data to third-party servers without explicit, hardened contractual protections is malpractice waiting to happen. The serious approach involves fine-tuning smaller, open-source models on a firm’s own curated document sets. This creates a domain-specific model that understands your firm’s risk tolerance and clause library.
The process requires significant GPU resources, either on-premise or through a private cloud instance. You must meticulously clean and label your training data, a job that is both tedious and critical. A model trained on a chaotic mix of draft and final agreements will produce unreliable output. The benefit is a proprietary asset that provides a competitive edge in diligence or contract negotiation sprints.
It’s a wallet-drainer upfront, but it pays off in defensible, private AI capabilities.
2. Process Mining for eDiscovery Workflows
Technology Assisted Review (TAR) has been around for years, but it’s often applied like a blunt instrument. Process mining injects a layer of intelligence before the review even begins. By analyzing event logs from platforms like Relativity or Reveal, you can map how documents actually move through the discovery process. This exposes bottlenecks, redundant review loops, and reviewer behaviors that inflate costs.
Instead of just guessing at workflow improvements, you get a data-driven model of your current state. For example, process mining might reveal that documents flagged by a certain junior associate are overturned by senior reviewers 80% of the time. You can then use this data to adjust the workflow, perhaps by routing that associate’s output through a QC step or providing targeted training. This is about instrumenting the entire eDiscovery lifecycle, not just accelerating document classification.
The system only works if your logs are clean. Inconsistent event naming or missing timestamps will break the model.
3. Client Portals as Data Endpoints
Clients are tired of receiving month-end PDF reports. They expect real-time access to case status, billing information, and key documents. Building a client portal isn’t just a front-end design project. It requires a robust API layer that can safely expose data from your core systems, primarily the Case Management System (CMS) and billing platform.
Most legacy legal systems were not built with external APIs in mind. Getting data out of them often involves ugly database queries, brittle screen-scraping jobs, or dealing with poorly documented, SOAP-based endpoints. The architectural challenge is to build a mediating service that can query these legacy systems, transform the data into a clean JSON format, and serve it to the client-facing application. This service acts as a buffer, protecting your internal systems and providing a consistent interface for the front-end developers.
Authentication and authorization are critical. You need granular, role-based access control to ensure a client from one matter cannot see data from another. This is non-negotiable.
4. Governed Low-Code Automation
Platforms like Bryter, Josef, and Neota Logic allow paralegals and junior associates to build simple applications without writing code. These are effective for automating client intake forms, generating standard NDAs, or building expert systems for regulatory questions. They offload simple, repetitive work from the legal engineering team, which is a clear win.
The danger is uncontrolled proliferation. Without a central governance model, you end up with dozens of siloed, unsupported micro-applications. When the paralegal who built a critical intake form leaves the firm, no one knows how it works or how to fix it. A proper governance strategy involves maintaining a central repository of all low-code apps, enforcing naming conventions, and requiring documentation for anything that touches client data or integrates with a core system.
It’s the difference between empowering your staff and creating a shadow IT nightmare.
5. Knowledge Graphs for Legal Research
Boolean search over a document index is a primitive tool. It finds keywords, not concepts. Knowledge graphs represent a fundamental shift. Instead of storing documents, you store entities (like judges, courts, companies, statutes) and the relationships between them. This allows for far more sophisticated queries, such as “Find all cases where Judge Smith cited Section 230 and ruled against a social media company.”
Building a legal knowledge graph is a massive data engineering project. You need to extract these entities and relationships from millions of unstructured documents, a task requiring sophisticated NLP pipelines. Then, you load this structured data into a graph database like Neo4j. The initial effort is immense, like trying to shove a firehose of unstructured text through the needle of a structured data model. Once built, however, it gives your research team a view of the legal landscape that is impossible to achieve with keyword search alone.
Example Cypher Query
A query to find judges who have cited a specific statute in cases involving a particular company might look like this in Cypher, the query language for Neo4j:
MATCH (j:Judge)-[:AUTHORED]->(o:Opinion)-[:CITES]->(s:Statute {citation:"15 U.S.C. § 78j(b)"})
MATCH (o)-[:INVOLVES]->(p:Party {name:"Example Corp"})
WHERE o.date > date("2020-01-01")
RETURN j.name, o.caseName, o.date
ORDER BY o.date DESC
This code block searches for a pattern: a Judge who authored an Opinion that cites a specific Statute and involves a specific Party. It’s a level of semantic query that is out of reach for traditional text search engines.
6. Probabilistic Litigation Modeling
Predictive analytics for case outcomes is moving from academic experiment to practical tool. By training models on years of docket data, firms can generate statistical probabilities for outcomes like a motion to dismiss being granted or the likely range of damages. These are not deterministic predictions. They are statistical models that identify patterns in historical data.
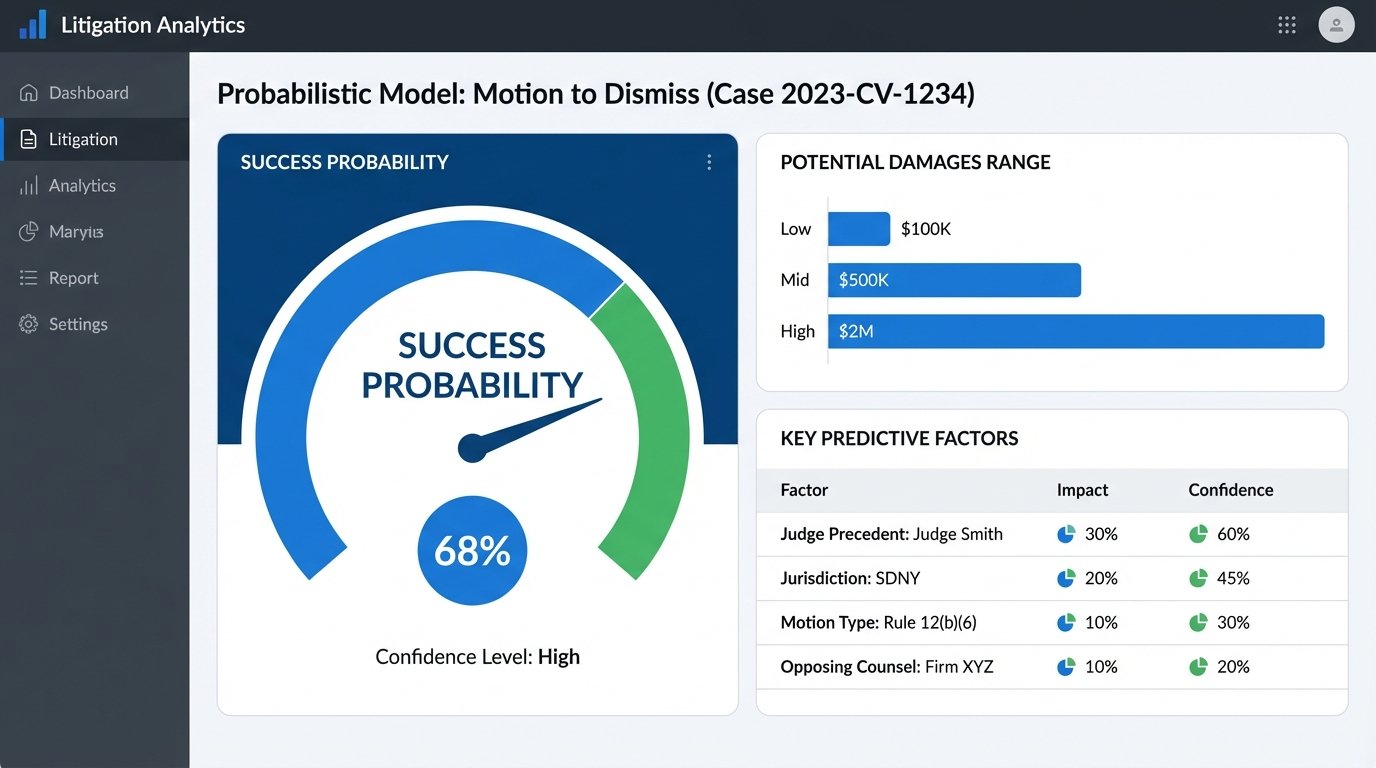
The main technical challenge is data acquisition and cleaning. Court dockets are notoriously messy. You need to parse inconsistent data formats, normalize party names, and correctly categorize motions and outcomes. The second major challenge is bias. If a model is trained on historical data that reflects societal biases, its predictions will replicate and amplify those biases. Auditing models for fairness and ensuring transparency in how they work is an ethical and technical requirement.
This isn’t a replacement for a lawyer’s judgment. It’s a data point to inform strategy.
7. Composable Legal Ops Platforms
The era of the single, monolithic Practice Management System that does everything poorly is ending. The modern approach is a composable architecture. This involves using a central platform, often a CLM or matter management system with a strong API, as a hub. You then connect best-in-class tools for specific functions, like e-billing, document management, or e-signatures, via API integrations.
This gives firms the flexibility to swap out components without having to replace the entire system. If a better e-signature tool comes along, you just write a new integration. The prerequisite is that your core platform must be API-first. If its API is an afterthought, weak, or poorly documented, the entire model falls apart. When evaluating a new core system, the quality of its API documentation is one of the most important criteria.
Migrating off a monolith is painful, but staying on one is a dead end.
8. Blockchain for Chain of Custody
Smart contracts for complex legal agreements remain mostly hype. The real, immediate use case for blockchain technology in law is evidence management. Establishing an unbroken chain of custody for digital evidence is a persistent challenge. By hashing a piece of evidence (a document, video file, or disk image) and recording that hash on a blockchain, you create an immutable, timestamped record of its existence at a particular point in time.
Anyone can later re-hash the file and verify that it matches the hash on the blockchain, proving it hasn’t been altered. This doesn’t require a public, speculative cryptocurrency network. A private, permissioned blockchain is more than sufficient and avoids the performance and cost issues of public chains. The technical implementation is straightforward for an engineering team, but it requires a strict operational protocol to be legally defensible.
It’s a narrow application, but one that solves a genuine problem.
9. Containerized, Cloud-Native DMS
Firms are finally ditching on-premise file servers for cloud Document Management Systems. The first wave of cloud DMS were just virtual machines running legacy software. The new generation is cloud-native, built on services like AWS S3 for storage and using containerization technologies like Docker and Kubernetes for deployment. This architecture provides better scalability, resilience, and security.
The key benefit for the firm’s IT team is that the vendor handles infrastructure management, patching, and backups. The downside is vendor lock-in and data egress costs. Getting terabytes of data out of a cloud DMS can be slow and expensive. Data sovereignty is another major concern. For firms with international offices, you must ensure the DMS provider can guarantee that data from a specific jurisdiction, like the EU, is stored in a data center within that jurisdiction to comply with regulations like GDPR.
You’re trading direct control for managed reliability. For most firms, this is the right move.
10. Specialized AI for M&A Due Diligence
Due diligence in M&A is a classic legal grind. Associates spend thousands of hours reading through a target company’s contracts to identify risks like change-of-control clauses, non-standard indemnity provisions, or problematic intellectual property assignments. AI platforms are now purpose-built to automate the first pass of this review.
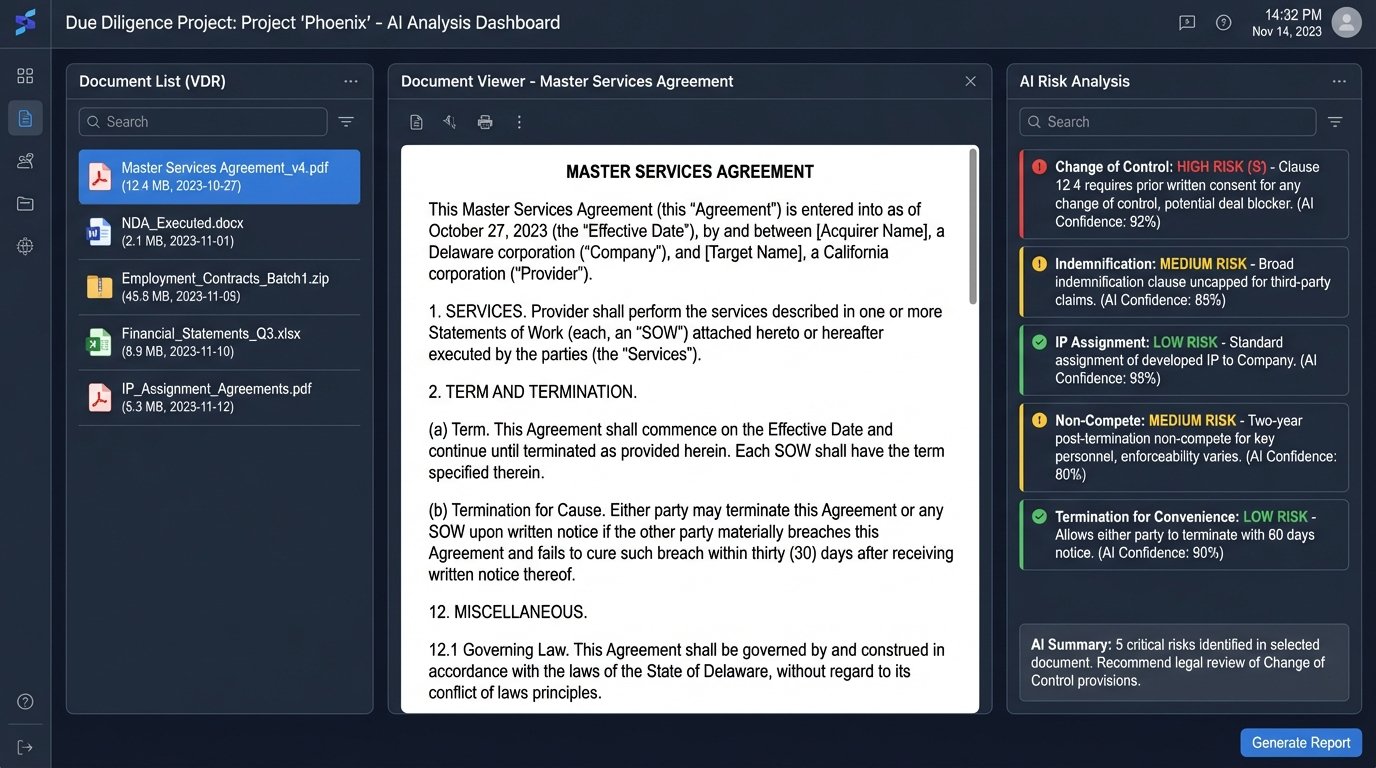
These systems are pre-trained on tens of thousands of commercial agreements. They can ingest an entire data room, classify the documents by type, and then extract and flag dozens of specific risk provisions. This doesn’t eliminate the need for human review. The systems still produce false positives and can miss nuance. What they do is change the job from finding the needle in the haystack to checking a small pile of pre-selected needles.
It allows the legal team to focus their attention on the 50 contracts with potential issues instead of manually sifting through 5,000. The time savings are substantial, and the reduction in human error from fatigue is a significant benefit.
These are not magic boxes. They are force multipliers for skilled attorneys.