
The signal to noise ratio in legal research is fundamentally broken. We are sold platforms that promise precision but deliver an ocean of marginally relevant case law. The core engineering problem isn’t a lack of data. It’s the brute force, keyword-centric architecture that still underpins most of the legal tech stack. The goal of automation is not to find more cases, it’s to find the dispositive few and to do it with verifiable logic.
This is not a feature comparison written by a marketing department. This is a technical breakdown of platforms that attempt to solve the relevance problem, viewed from the perspective of someone who has to integrate their APIs and clean up the data they output. We are looking at the guts of the machine, not the paint job. There is no single “best” tool. The choice is a function of your firm’s specific pain point, budget, and tolerance for vendor lock-in.
Casetext and its CARA A.I. Engine
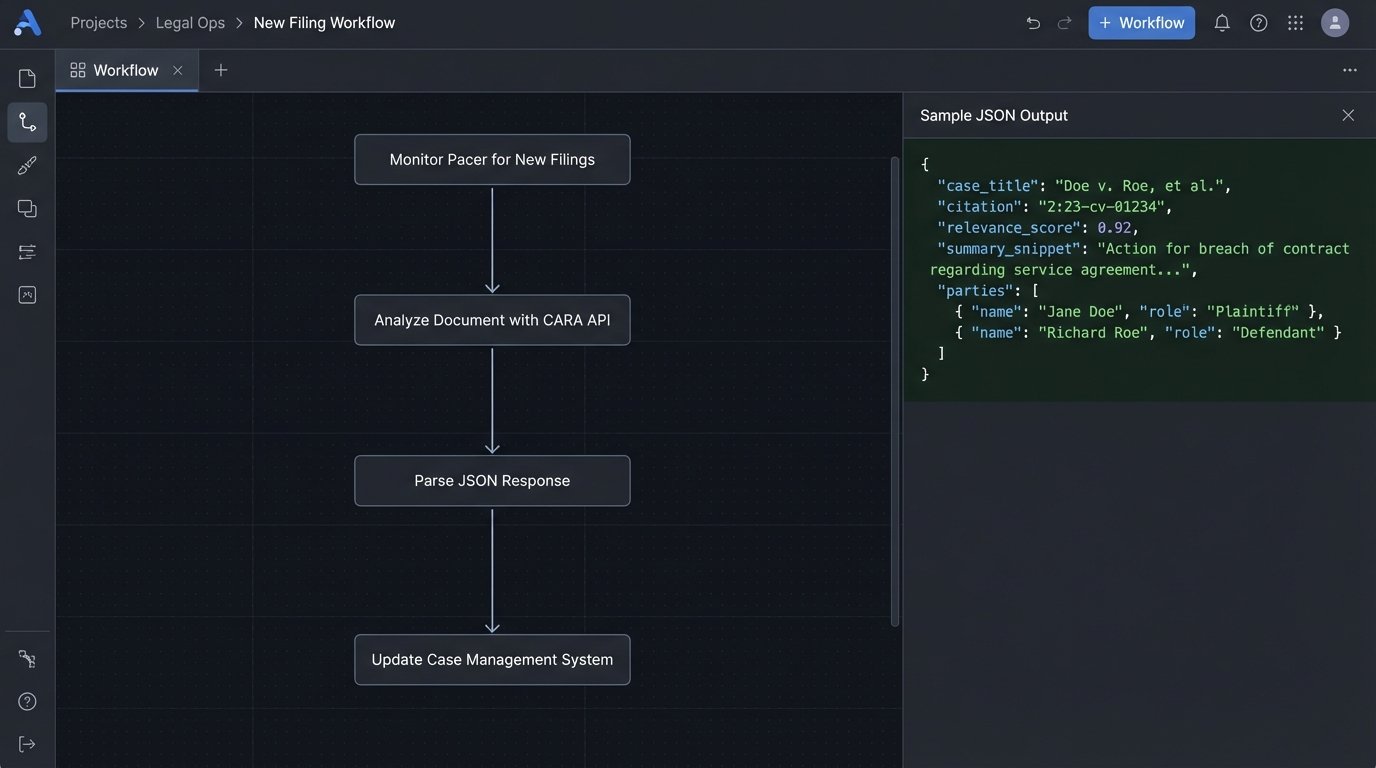
Casetext’s CoCounsel, powered by their CARA engine, is a direct assault on keyword search. Instead of matching strings, it ingests a document, like a motion or a brief, and uses a large language model to create a vector embedding of the core legal and factual concepts. The system then executes a vector search against its indexed case law database to find documents with similar conceptual fingerprints. This allows it to surface cases that use different terminology to discuss the same legal issue.
The entire value proposition is bypassing the need for an associate to spend hours crafting the perfect Boolean query.
Technical Benefits and Use Cases
The primary application is rapid case assessment. An attorney can drop an opposing counsel’s motion to dismiss into the system and get a list of on-point cases to build a response within minutes. We’ve used this to quickly pressure-test novel legal arguments before committing significant resources. It forces the system to find authorities you might have missed because you were anchored to a specific set of search terms. It’s a powerful tool for breaking out of your own cognitive biases during the initial research phase.
Their API, while not the most flexible, allows you to programmatically submit documents for analysis. You could, for instance, build a workflow that automatically analyzes every major pleading filed in your matters to identify key counterarguments and supporting case law. This shifts the process from a reactive, manual task to a proactive, automated one. The output is typically a JSON object containing a list of ranked cases, snippets of relevant text, and metadata. You then have to parse this and inject it into your case management system.
The Catch
The system is a black box. You get the results, but the underlying “reasoning” of the LLM is opaque, which is a hard sell for partners who need to stand behind the research. Data freshness is another persistent issue. While federal and major state appellate courts are updated quickly, there can be a noticeable lag for certain state trial courts or administrative decisions. This makes it risky for matters where the most recent decisions are critical. The enterprise license is also a wallet-drainer, so the ROI calculation has to be ruthless.
Finally, the output requires significant human oversight. The AI is good at finding conceptually similar cases, but it lacks the judgment to distinguish between a binding precedent and a persuasive but ultimately irrelevant opinion from another jurisdiction. It hands you a pile of sharpened sticks, you still have to build the spear.
vLex: The Global Data Aggregator
vLex’s strategy is different. Instead of focusing on a sophisticated search layer, their core strength is the sheer, brute-force aggregation of global legal data. By acquiring platforms like Fastcase and Docket Alarm, they have bolted together a massive repository of US and international case law, dockets, statutes, and secondary sources. Their value is not in search intelligence but in the breadth and granularity of their data access.
They offer a more traditional, RESTful API that lets you pull specific document types and metadata with a high degree of precision.
Technical Benefits and Use Cases
This is the tool for large-scale data analysis and business intelligence projects. If you need to track every lawsuit filed against a specific corporate entity across all 50 states, their Docket Alarm API is the most direct way to do it. We once built an internal expert witness tracking system by setting up a recurring script to hit their API. The script would pull dockets matching certain criteria, strip the expert declarations using regex, and inject the expert’s name, case details, and a link to the document into our internal SQL database.
The control over the data is the key. You are not just getting a list of “relevant” cases. You are pulling structured data that can be used to build your own analytics. For firms doing sophisticated litigation analytics, tracking judicial ruling patterns, or monitoring competitor activity, the vLex API provides the raw material. You can pull thousands of documents and their associated metadata to feed your own models.
Here is a simplified Python snippet showing how you might query an API endpoint like theirs to fetch documents related to a specific keyword and jurisdiction. The actual authentication and endpoint details would be more complex.
import requests
import json
API_KEY = "YOUR_API_KEY_HERE"
API_ENDPOINT = "https://api.vlex.com/v2/search/documents"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
query_payload = {
"query": "\"breach of fiduciary duty\" AND \"summary judgment\"",
"jurisdiction": "us-ny-state",
"page_size": 10
}
response = requests.post(API_ENDPOINT, headers=headers, data=json.dumps(query_payload))
if response.status_code == 200:
results = response.json()
for doc in results.get('data', []):
print(f"Case Title: {doc.get('title')}, Citation: {doc.get('citation')}")
else:
print(f"Error: {response.status_code} - {response.text}")
This kind of direct API access allows you to bypass the user interface entirely and integrate the data pipeline directly into your firm’s applications.
The Catch
The search technology itself is a generation behind Casetext. It is heavily reliant on Boolean operators and keyword matching. You are trading semantic intelligence for raw data volume. Furthermore, the platform feels like the collection of acquired companies that it is. The data schemas can be inconsistent between the Fastcase case law API and the Docket Alarm docket API. Integrating them requires writing custom logic to normalize the data before it can be used. It feels less like a unified platform and more like trying to bridge three separate databases built in different decades with different philosophies. The performance can also be sluggish when running complex, multi-faceted queries across their entire dataset.
Lexis+: The Incumbent with a New Engine
LexisNexis is the entrenched legacy provider. Their platform, Lexis+, is a massive, sprawling ecosystem that has been the backbone of legal research for decades. Their primary technical advantage is not novel search algorithms but their proprietary, human-curated data sets, most notably Shepard’s. The Shepard’s signal, indicating how a case has been treated by subsequent decisions, is still the industry standard for citation validation.
Their API strategy has historically been restrictive, but they have opened up access to key features like Shepard’s, allowing for powerful automation.
Technical Benefits and Use Cases
The number one use case for automating Lexis is the final validation of a legal brief before filing. You can write a script that extracts every single citation from a Word document, hits the Shepard’s API for each one, and generates a report flagging any case that has been overruled, questioned, or otherwise treated negatively. This automates a high-stakes, error-prone manual process. We built a validation service that plugged directly into our document management system. Before a brief could be routed for partner signature, it had to pass the automated Shepard’s check.
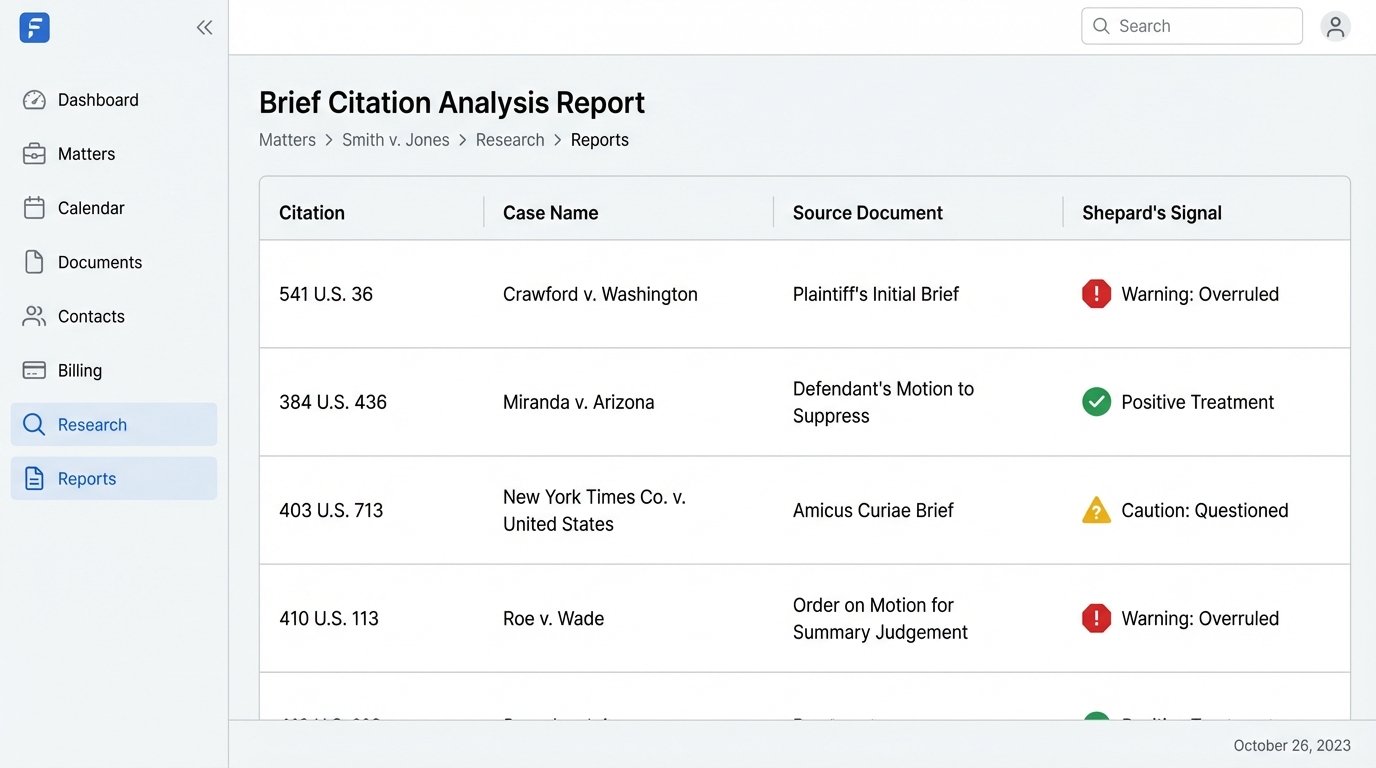
Their “Brief Analysis” tool is their direct competitor to Casetext’s CARA. It performs a similar function of ingesting a document and recommending relevant cases. It also has the added benefit of automatically Shepardizing every citation in the uploaded document, which can be a fast way to find vulnerabilities in an opponent’s arguments. While the recommendations may not be as conceptually broad as CoCounsel’s, the integration with their core citator data is a significant advantage for late-stage research.
The Catch
The platform is a monolith. The user interface can be slow and cluttered with features most users never touch. The cost is the highest in the industry, and contract negotiations are notoriously painful. You are paying a massive premium for the Lexis brand, the Shepard’s signal, and their exclusive content. Their search technology, while improved with some natural language capabilities, still feels rooted in a Boolean mindset. You get the best results when you construct queries with the precision of a database administrator, a skill that is becoming less common. The architecture is a clear example of legacy systems being retrofitted with new technology, leading to an often disjointed user experience.
Rolling Your Own: The CAP API and Vector Databases
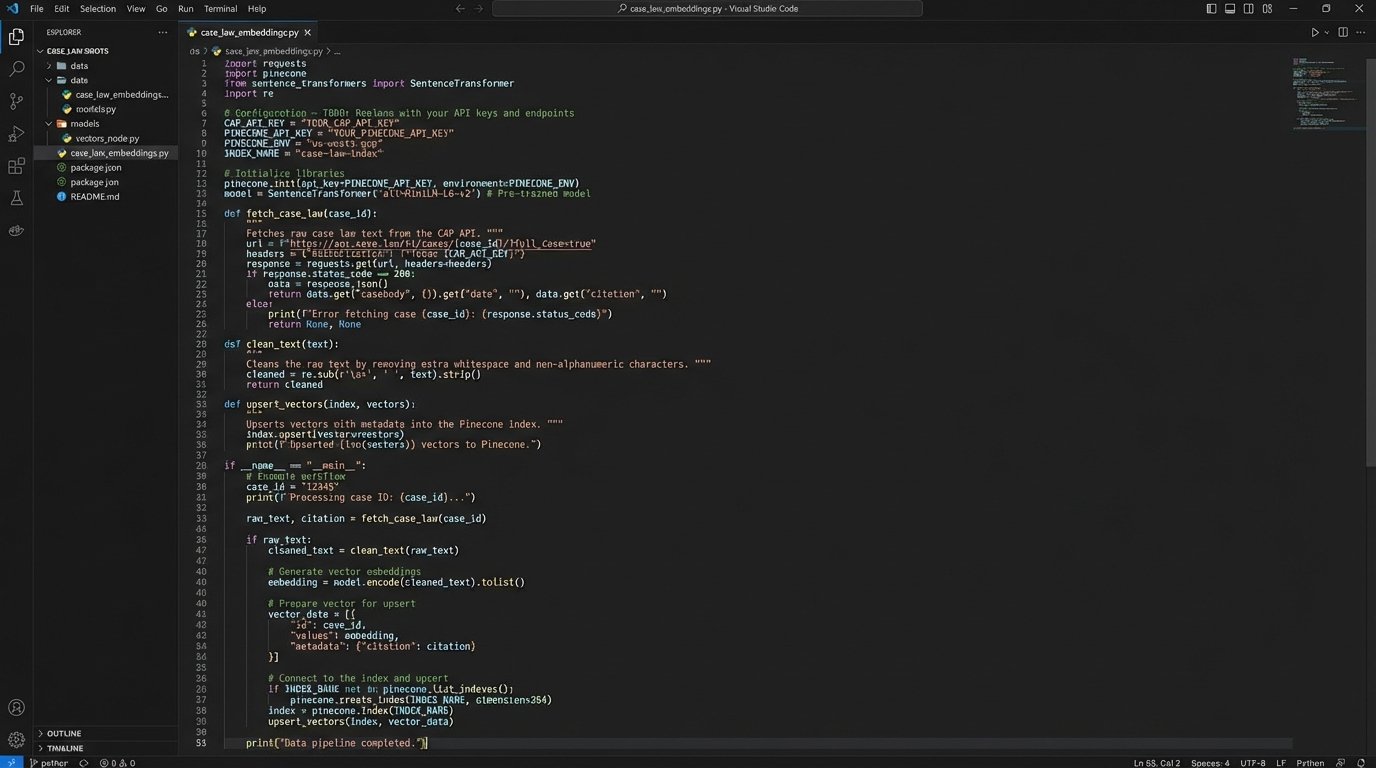
For firms with in-house technical resources and highly specialized needs, forgoing commercial platforms entirely is a viable option. This involves pulling raw case law data from an open-source repository, such as Harvard’s Caselaw Access Project (CAP) API, and building a custom search engine. The process involves setting up a data pipeline to fetch and clean the raw text, running it through an embedding model to create vectors, and then loading those vectors into a dedicated vector database like Pinecone or Weaviate.
This gives you absolute control over the entire research stack.
Technical Benefits and Use Cases
This approach is best for creating a research tool for a niche practice area where the commercial vendors lack sufficient depth or specific functionality. A patent litigation group could ingest not only case law but also all relevant USPTO filings and technical journals, creating a unified semantic search engine across the entire corpus. You control the data sources, the update frequency, the embedding model, and the ranking algorithm. You can fine-tune the system to understand the specific jargon and concepts of your practice area far better than a generalist tool ever could.
The cost structure is also radically different. Instead of paying per-user license fees, you are paying for cloud computing resources and engineering time. For large firms, this can be significantly more cost-effective in the long run. You are building a proprietary asset, not renting a service. The entire system is a white box, completely auditable and customizable.
The Catch
This is a major engineering undertaking. It is not a project for a part-time IT consultant. You need dedicated data engineers who understand data ingestion pipelines, NLP, and database management. The data from sources like CAP is notoriously messy. It’s the result of a massive OCR project, and it’s filled with scanning errors, garbled text, and inconsistent metadata. Your first task is a massive data-cleaning operation, which is like shoving unstructured text through a woodchipper and hoping structured data comes out the other side. You are also responsible for everything: uptime, security, maintenance, and the ethical implications of your ranking algorithm. It is the most powerful option, but also the most brittle and resource-intensive.
The Inevitable Choice: Speed, Cost, Control
No platform offers a perfect solution. The decision is a direct mapping to your firm’s operational priorities. Casetext offers speed and conceptual search at the expense of transparency and cost. vLex provides unparalleled raw data access, but requires you to compensate for its dated search interface. Lexis+ delivers the gold-standard citator for validation, but locks you into a bloated, expensive, and often sluggish ecosystem.
Building a custom solution offers total control, but demands a significant and ongoing investment in engineering resources that most firms are not structured to support. The correct choice depends entirely on the problem you are trying to force a solution upon. Is it rapid analysis for a high-volume practice, deep data mining for litigation analytics, or bulletproof validation for high-stakes filings? Each use case points to a different architecture. The real work begins after the tool is chosen. The hardest part is rarely the research itself. It’s forcing the clean, structured output from these modern platforms into the creaking, legacy case management systems that actually run the business.