
Statutory research automation is not about finding a magic API that spits out perfect answers. It’s about wrestling with inconsistent data structures, undocumented API endpoints, and version control systems that were designed before the internet was a public utility. The core engineering problem is not search. The problem is trust. How do you programmatically verify that a specific statutory section is still good law without a human manually checking three different sources?
The marketing slicks promise AI-powered insights. The reality is a series of brittle data pipelines held together by Python scripts and a healthy fear of legislative updates. Choosing a platform is not a feature comparison. It is a commitment to a specific vendor’s technical debt and data architecture. Below is a breakdown of the primary players, viewed from the perspective of someone who has to build on top of them.
Westlaw Precision: The Incumbent with a New Engine
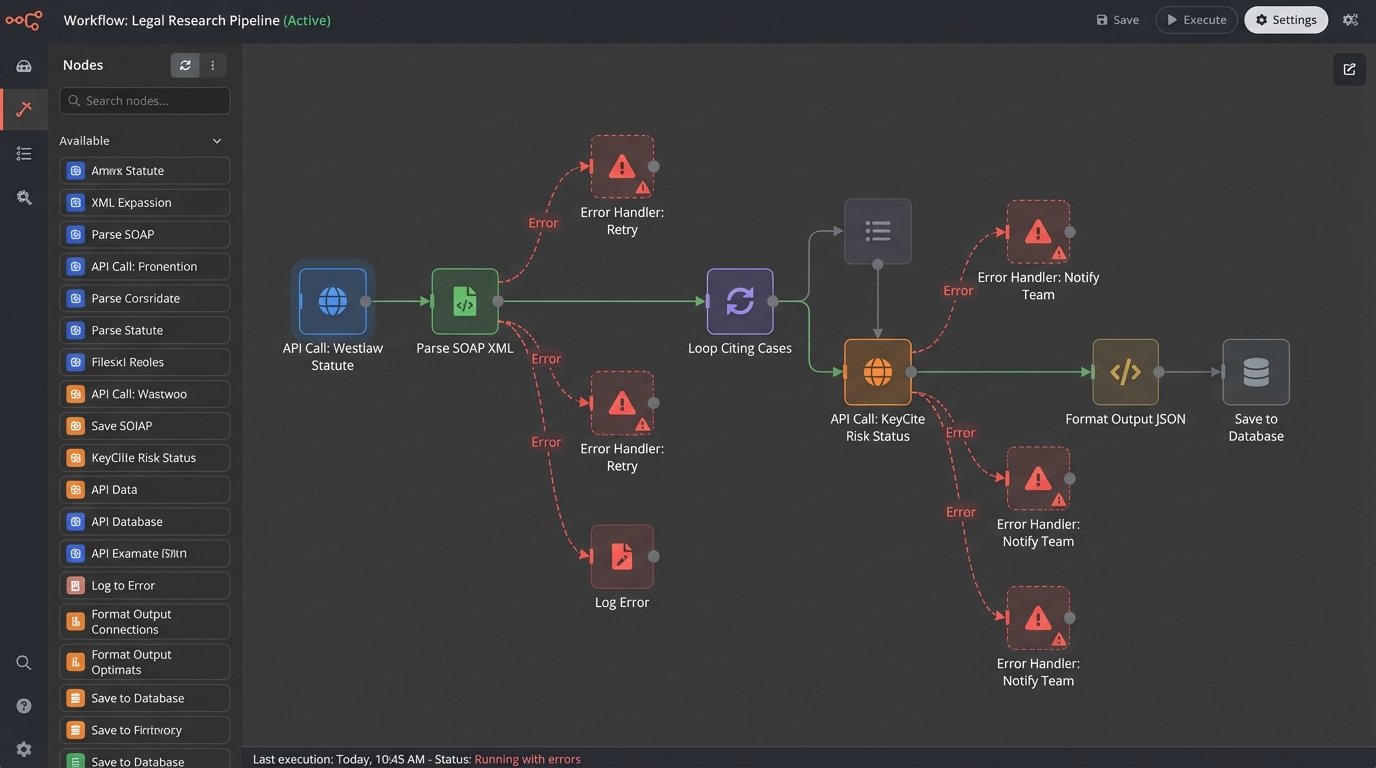
Westlaw’s primary technical asset is the KeyCite database. For decades, it has been the benchmark for citation analysis. The system functions as a massive, heavily indexed graph database where nodes represent cases, statutes, and regulations, and the edges represent citations with associated treatments like “overruled by” or “amended by.” Automating against this requires understanding its limitations. The signals are not real-time. They are the result of a massive batch processing system run by an army of human editors.
Accessing this data programmatically is where the trouble starts. The Thomson Reuters Legal API is a sprawling collection of endpoints with inconsistent authentication schemes and data formats. Some parts feel modern, returning clean JSON. Others are clear holdovers from a SOAP-based architecture, forcing you to parse ugly XML that violates half the principles of sane data design. You will spend more time writing data cleaning and validation scripts than you will building your core application logic.
Key Features from an Engineering Perspective
- KeyCite Overruling Risk: This feature flags cases that rely on a point of law that has since been implicitly overruled. From a data perspective, this is a sophisticated edge-weighting algorithm. It identifies a “parent” case that was directly overruled and then traces the citation graph “downstream” to find cases that cited the now-bad law. Automating this check requires a multi-step API call. First, you query the primary statute, then you iterate through its citing cases, and for each case, you make a separate call to check its overruling risk status. This is slow and expensive.
- Precision Research: The marketing calls it AI. Under the hood, it’s a proprietary Natural Language Processing (NLP) model layered on top of their existing boolean search index. It tokenizes your query, runs it through a classifier to identify legal issues, and then constructs a complex boolean query against the Westlaw index. It is better than simple keyword search, but it is not a true semantic or vector search. It can still be tripped up by unusual phrasing or novel legal arguments. You cannot directly access this NLP layer via the public API. You can only send it a string and get back a list of results.
- Statutory Version Comparison: Westlaw’s platform allows you to see redline comparisons between different versions of a statute. This is incredibly useful for tracking legislative changes. The API provides access to these historical versions, but it does not provide a clean “diff” output. You have to pull the full text of two separate versions and run your own text comparison logic. This is a massive missed opportunity that forces redundant work on your end.
The fundamental trade-off with Westlaw is cost for data integrity. Their data is meticulously curated by human editors, which makes it a reliable source of truth. But that curation comes at a premium that makes large-scale, high-volume automation a true wallet-drainer. They know they have the data, and they price it accordingly.
Lexis+: The Challenger’s Bet on AI and Integration
Lexis has been aggressively bolting on AI features to its core platform to compete with Westlaw. Their strategy is less about a single, unified data model and more about integrating a suite of acquired tools and technologies. This creates a powerful but sometimes disjointed experience for an engineer. The data for statutory analysis might live in one system, while the data for case analytics lives in another, and bridging the two requires navigating different API schemas.
The Shepard’s signal is the direct competitor to KeyCite. It functions on a similar principle of tracking citations and applying treatment codes. From a technical standpoint, the output from Shepard’s via the API is often more structured than KeyCite’s. It tends to return cleaner JSON with more predictable key-value pairs. This can slightly reduce the amount of data munging required to make the information usable.
Architectural Highlights and Headaches
- Lexis+ AI: The platform offers a suite of generative AI tools for summarizing statutes, drafting arguments, and answering legal questions. This is built on top of a large language model from the Anthropic family, fine-tuned on Lexis’s proprietary legal data. When you use their API for this, you are not just getting a simple text completion. Your query is passed through a Retrieval-Augmented Generation (RAG) system that first performs a search against the Lexis database to find relevant statutes and cases, then injects that context into the prompt sent to the LLM. This reduces hallucinations but introduces latency.
- Brief Analysis: This tool allows you to upload a brief and have the system extract citations, find similar arguments in other documents, and check the validity of the cited law. The API for this is useful but heavy. You are not sending a simple query. You are POSTing an entire document, which then kicks off an asynchronous processing job. You have to build a system that can handle webhooks or poll a status endpoint to know when the analysis is complete. It is not a simple request-response cycle.
- Statutory Code Compare: Similar to Westlaw, Lexis offers a tool to compare legislative text. The API support for this feature is slightly better. Some endpoints will provide a structured object that breaks down what was added, deleted, or changed between versions, saving you the trouble of running your own diffing algorithm. This can be a significant time saver for any application tracking legislative histories.
Lexis presents a different kind of complexity. The AI tools can surface connections that a human researcher might miss, but they also operate as a black box. If the AI provides a faulty summary of a statute, debugging the root cause is nearly impossible. You are forced to trust the output, which is a dangerous position for any engineering team responsible for data accuracy. Trying to force high-volume statutory updates through their legacy API feels like shoving a firehose through a needle. The pressure builds and something eventually breaks, usually your data validation script.
Casetext and CoCounsel: The API-First Disruptor
Casetext, now part of Thomson Reuters, was built as a software company first and a legal publisher second. This is evident in its architecture. Their entire platform was designed around search from day one, and their API is a core product, not an afterthought. This means better documentation, a more consistent RESTful design, and a focus on developer experience that the incumbents simply do not have.
The platform’s core search technology, CARA A.I., is a vector search engine. Instead of just matching keywords, it converts both your query and the documents in its database into numerical representations (embeddings) and finds the closest matches in that vector space. This is fundamentally different from the boolean logic that powers the older platforms. It is much better at finding conceptually similar statutes even if they do not share the same keywords.
The introduction of CoCounsel, which is a fine-tuned GPT-4 integration, pushes this further. It is a true legal copilot, but integrating with it requires a different skillset. You are no longer just fetching data. You are performing prompt engineering. You must construct highly specific, context-rich prompts to get reliable, accurate output from the LLM. A poorly worded prompt can easily lead the model to misinterpret a statute or invent legal concepts.
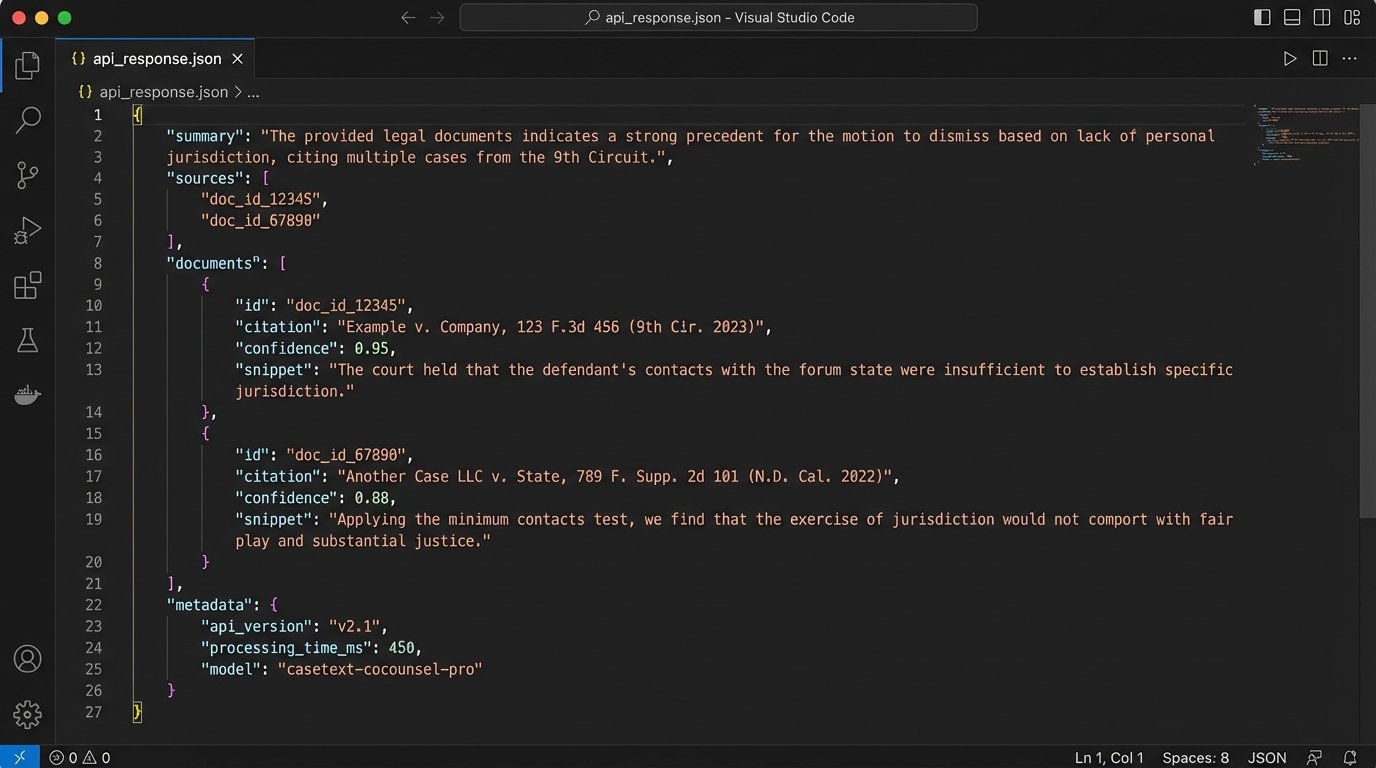
Building on CoCounsel requires a robust validation layer. After receiving a response from the API, your application must perform its own logic checks. This includes extracting the sources the model claims to have used, making separate API calls to fetch those source statutes directly, and then comparing the source text to the model’s generated summary or analysis. You cannot blindly trust the output.
json
{
“query”: “What are the requirements for standing under California Code of Civil Procedure § 367?”,
“response”: {
“summary”: “Under CCP § 367, an action must be prosecuted in the name of the real party in interest, except as otherwise provided by statute. This means the person who has the right to sue under the substantive law.”,
“sources”: [
{
“citation”: “Cal. Code Civ. Proc. § 367”,
“document_id”: “doc_12345”,
“confidence_score”: 0.98
}
],
“model_used”: “gpt-4-legal-tuned-v2”
}
}
The code above shows a simplified JSON response from a hypothetical CoCounsel-like API. The critical part is the `sources` array. Your automation must parse this, grab the `document_id`, and then make a follow-up call to a separate endpoint to retrieve the raw text of that statute to validate the `summary`.
The trade-off with Casetext is depth for speed. Its modern, API-first architecture makes it far easier and faster to build with. However, its library of annotated codes and secondary sources is not as comprehensive as Westlaw’s or Lexis’s. You might get a faster answer, but you might miss a crucial law review article from 1985 that perfectly interprets your statute.
The DIY Route: Parsing Government Feeds
For teams with more engineers than budget, there is always the option of bypassing commercial vendors entirely and sourcing statutory data directly from government websites like the U.S. Government Publishing Office (GovInfo) or state legislative portals. This approach gives you complete control over the data pipeline. It is also a path fraught with peril.
Government data feeds are notoriously unreliable. You will not get a clean, versioned REST API. You will get a collection of FTP servers, poorly documented XML feeds, and raw HTML pages that change their structure without warning. Your team will first need to become experts in web scraping and data parsing. You will build and maintain a fleet of custom parsers for each jurisdiction you need to cover.
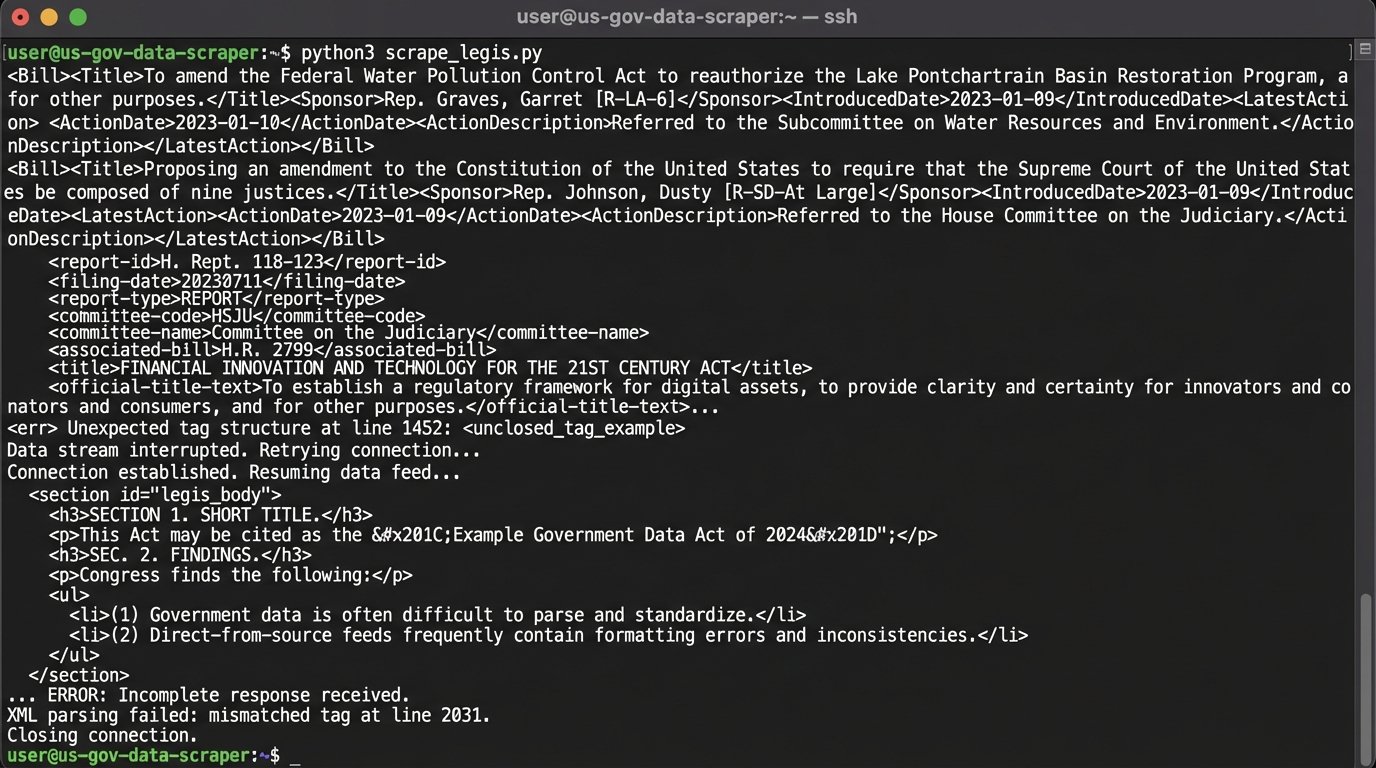
Once you have the raw text, the real work begins. You have to build your own database to store and, most importantly, version the statutes. You need a system to detect when a law has been amended, repealed, or renumbered. This requires constantly polling the source feeds and running comparisons against your existing data. It is a full-time data engineering job for multiple people.
The biggest missing piece is the analytical layer. You get the text of the law and nothing else. There is no KeyCite or Shepard’s to tell you how that statute has been interpreted by the courts. There are no editor-written annotations or cross-references. You have to build all of that yourself, which would involve an even more massive undertaking of scraping court opinions and building your own citation analysis engine.
Choosing the DIY route means accepting all responsibility for data integrity. If your parser misses an amendment and your system presents a lawyer with an outdated version of a statute, the liability is entirely yours. It is the cheapest option in terms of licensing fees and the most expensive in terms of engineering hours and risk.
Head-to-Head: Data Latency, API Usability, and Cost
No platform is superior on all metrics. The choice depends entirely on which compromises your organization is willing to make. Westlaw offers the highest data confidence but shackles you with a legacy API and enterprise-level pricing. Lexis provides a more modern API for some features but can feel like a collection of disconnected systems, and its AI requires careful validation.
Casetext offers the best developer experience and a truly modern search architecture, but it lacks the historical depth of its older rivals. The direct government-feed approach provides total control but requires a massive, ongoing investment in specialized engineering talent to build and maintain the necessary infrastructure.
Ultimately, the decision rests on a simple question. Are you optimizing for data completeness, developer velocity, or operational cost? You can pick two at most. The ideal tool for automated statutory research does not exist. The best you can do is select the platform whose specific set of problems you are best equipped to solve.