
5 Metrics to Automate for Better Real Estate Decision-Making
Most real estate analytics platforms are just dashboards pulling from clean, predictable MLS feeds. They tell you what happened yesterday. That information is table stakes. True operational advantage comes from automating the ingestion and analysis of dirty, disparate data sources to predict what happens tomorrow. This is about building a system that flags opportunities and risks before they appear on a Zillow trend line.
The goal is not to build another report that gets ignored. The goal is to build triggers. We are connecting public records, zoning laws, and market velocity into a logic-checked system that forces a decision. Forget dashboards. Think alerts, automated work orders, and pre-populated acquisition models. This is about converting raw data into mechanical action.
1. Rental Yield Volatility Index
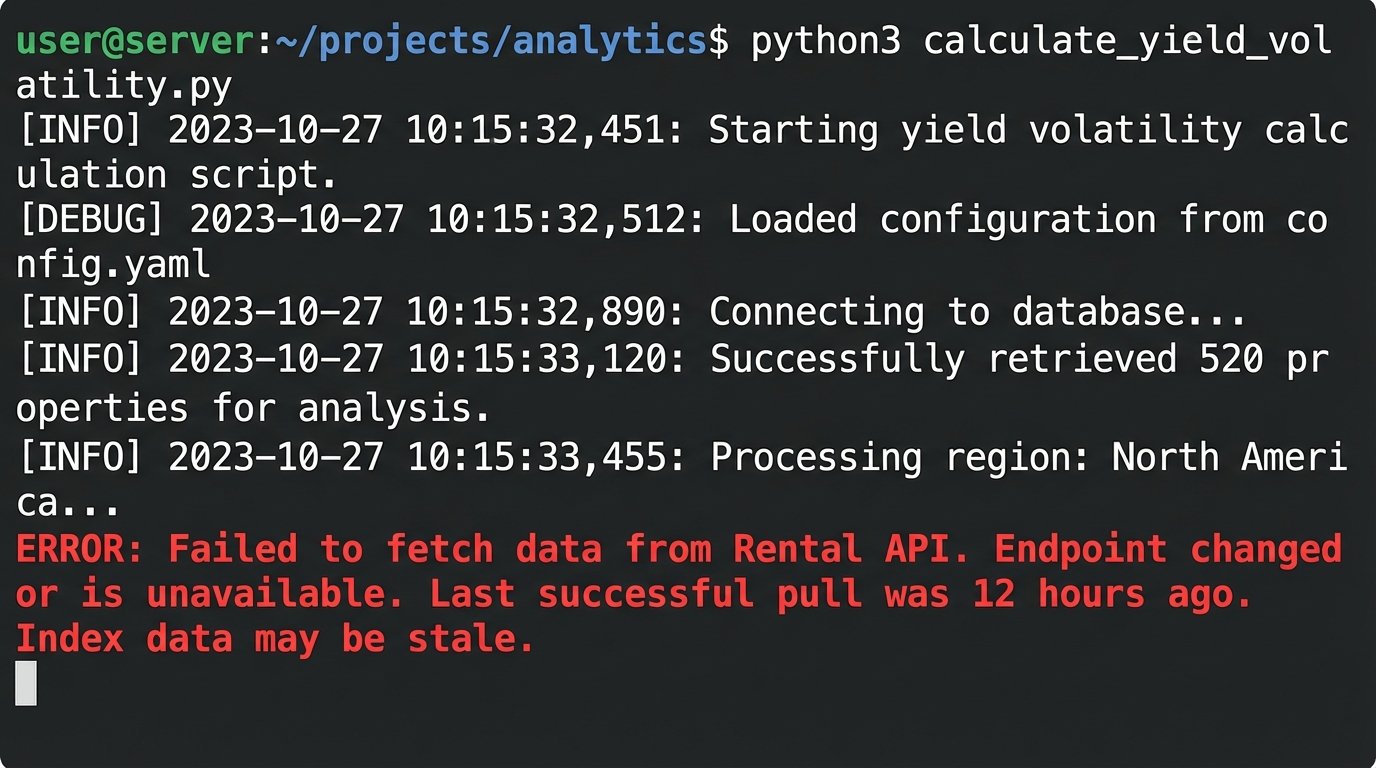
Gross rental yield is a simple calculation. It is also a dangerously static one. A 7% yield today means nothing if the local market rents swing wildly based on seasonal demand or the construction of one new apartment complex. Automating a volatility index requires continuously pulling historical rental data against current for-sale listings for a specific neighborhood or zip code. We are measuring the standard deviation of the rental yield over a trailing 12 or 24 month period.
This requires a script scheduled to hit multiple endpoints. One for rental averages, another for sales data. You then have to normalize the data, because the rental data source will define a “two-bedroom” differently than the sales data source. It’s a data janitor’s job before you ever get to the math.
A low volatility index signals a stable, bond-like asset class perfect for conservative cash-flow investors. A high volatility index points to a speculative market where timing is everything. It separates the buy-and-hold markets from the trade-for-a-profit markets.
Your script will fail, probably due to an unannounced API change from your data provider. Build in error logging that does more than just print a stack trace. It needs to tell you which source broke and whether the last successful data pull is stale enough to invalidate your entire index.
2. Days on Market (DOM) Decay Rate
Days on Market is a lagging indicator. A more potent metric is the rate at which sellers in a given submarket are forced to drop their asking price. This decay rate is a direct measurement of seller desperation and market leverage. To automate this, you must capture a snapshot of active listings daily, tracking every single price change until the property goes off-market.
This is a classic web scraping operation, unless you want to pay a fortune for a historical data feed. You will be writing parsers that target specific HTML elements on listing sites. These parsers are brittle. A minor front-end update to a site like Redfin or Realtor.com will break your data pipeline, often silently. You need checksums and structural validation on every run to detect when your scraper starts pulling garbage.
The output is a simple percentage. For example, “In the 78704 zip code, properties on the market for more than 30 days see an average price reduction of 1.2% per week.” This is not just data. It is a negotiation tool. It tells an acquisitions agent exactly how much pressure to apply and when.
You’re not just archiving data. You are building a time-series database that maps market psychology.
3. School District Performance to Property Tax Ratio
Everyone knows good schools drive property values. Few analysts actually quantify the premium. This metric automates the process of finding undervalued assets in strong school districts. It requires joining two completely different and often messy datasets: public school performance scores and county property tax records. One comes from an API like GreatSchools, the other comes from a government portal that looks like it was designed in 1998.
The core of the problem is the join key. You need to map a property parcel ID from the tax assessor’s office to a school district boundary. This often involves working with shapefiles and geospatial queries, or brute-force mapping of addresses. The addresses from the county will be non-standardized. You will spend more time writing data cleaning functions than you will on the actual analysis.
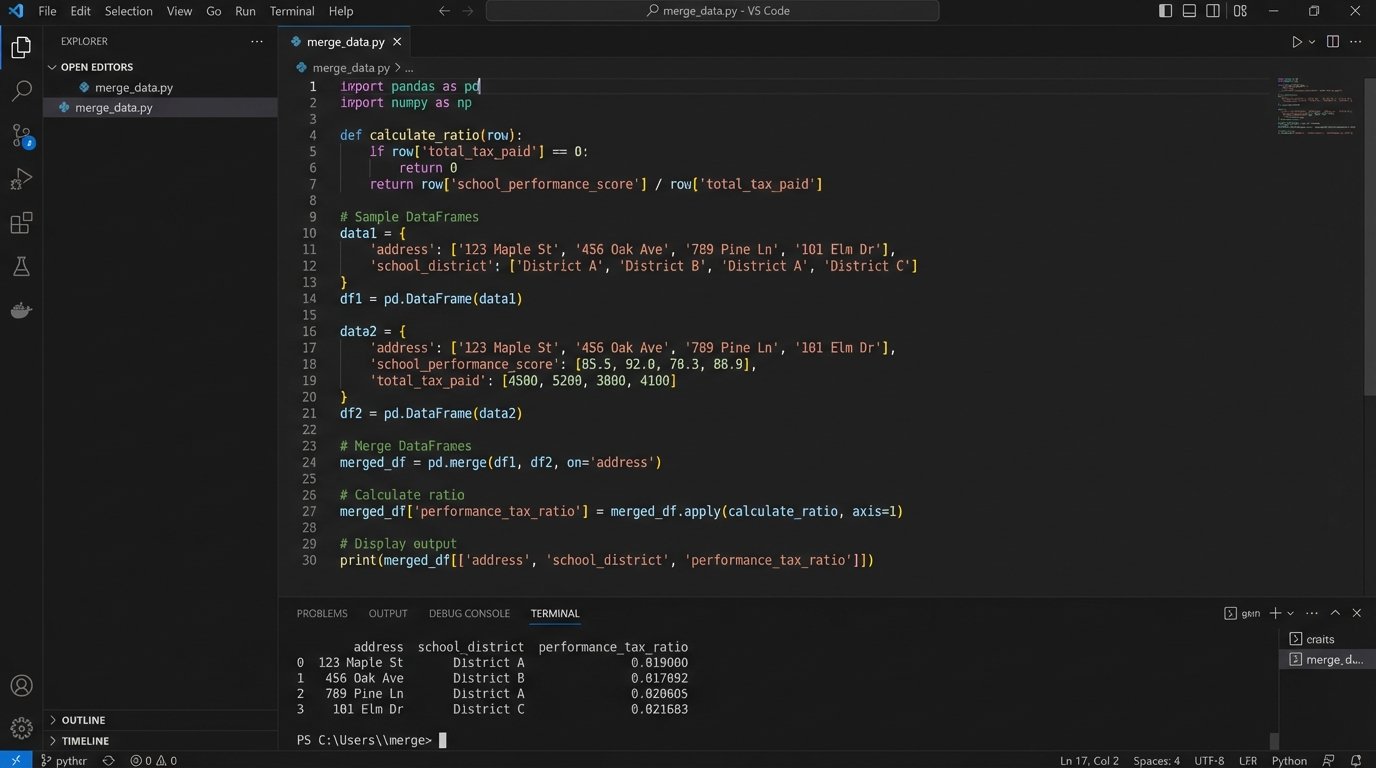
This is like trying to bolt a car engine onto a bicycle frame. The school data from an API is structured and clean. The public tax record data is a dumpster fire of inconsistent formatting and missing fields. Your automation script needs to be robust enough to handle the garbage data without crashing the entire pipeline. Below is a simplified look at what the core data merge might involve using pandas, assuming you’ve already done the hard work of cleaning both sources.
import pandas as pd
# Assume 'tax_df' is cleaned data from county assessor
# Assume 'school_df' is cleaned data from a school rating API
# The 'school_district' column is the key we've engineered
def calculate_ratio(tax_df, school_df):
# Merge on the engineered school district key
merged_df = pd.merge(tax_df, school_df, on='school_district', how='left')
# Logic-check for failed joins
merged_df.dropna(subset=['avg_school_rating', 'property_tax_assessed'], inplace=True)
if merged_df.empty:
raise ValueError("Data join resulted in empty DataFrame. Check keys and source data.")
# Calculate the metric: a simple ratio of rating points per dollar of tax
# A higher number is 'better'
merged_df['performance_tax_ratio'] = merged_df['avg_school_rating'] / merged_df['property_tax_assessed']
# Identify top 5% of properties based on this new ratio
top_performers = merged_df[merged_df['performance_tax_ratio'] > merged_df['performance_tax_ratio'].quantile(0.95)]
return top_performers[['address', 'school_district', 'performance_tax_ratio']]
This script finds the arbitrage. It flags properties where you get the most school performance for the least amount of tax burden. These are the hidden gems that simple CMA reports will always miss.
4. Infrastructure Development Proximity Score
Future value is driven by future infrastructure. A new light rail station or the development of a large corporate campus can fundamentally alter a neighborhood. This metric automates the tracking of approved municipal projects and scores properties in your portfolio based on their proximity to these developments. It is an attempt to quantify future appreciation.
The data source here is the weakest link. You are often dealing with unstructured PDFs from city planning department websites. You will need to build a system that polls these sites for new documents, then uses optical character recognition (OCR) and regular expressions to extract key information like project type, address, and completion date. It is a fragile process that requires constant supervision.
Once you have a location, you use a geocoding API to get coordinates. Then you run a spatial query against your own property database, calculating the distance. A property within 0.5 miles of a new transit stop gets a high score. A property within 2 miles of a new landfill gets a heavily negative score. This transforms vague “up-and-coming neighborhood” talk into a hard number.
This is not a set-it-and-forget-it script. The document formats will change without notice. The geocoding APIs have costs that can spiral if you are processing thousands of properties. This is an expensive metric to maintain, but it provides a massive information advantage.
5. Comparative Market Analysis (CMA) Anomaly Detection
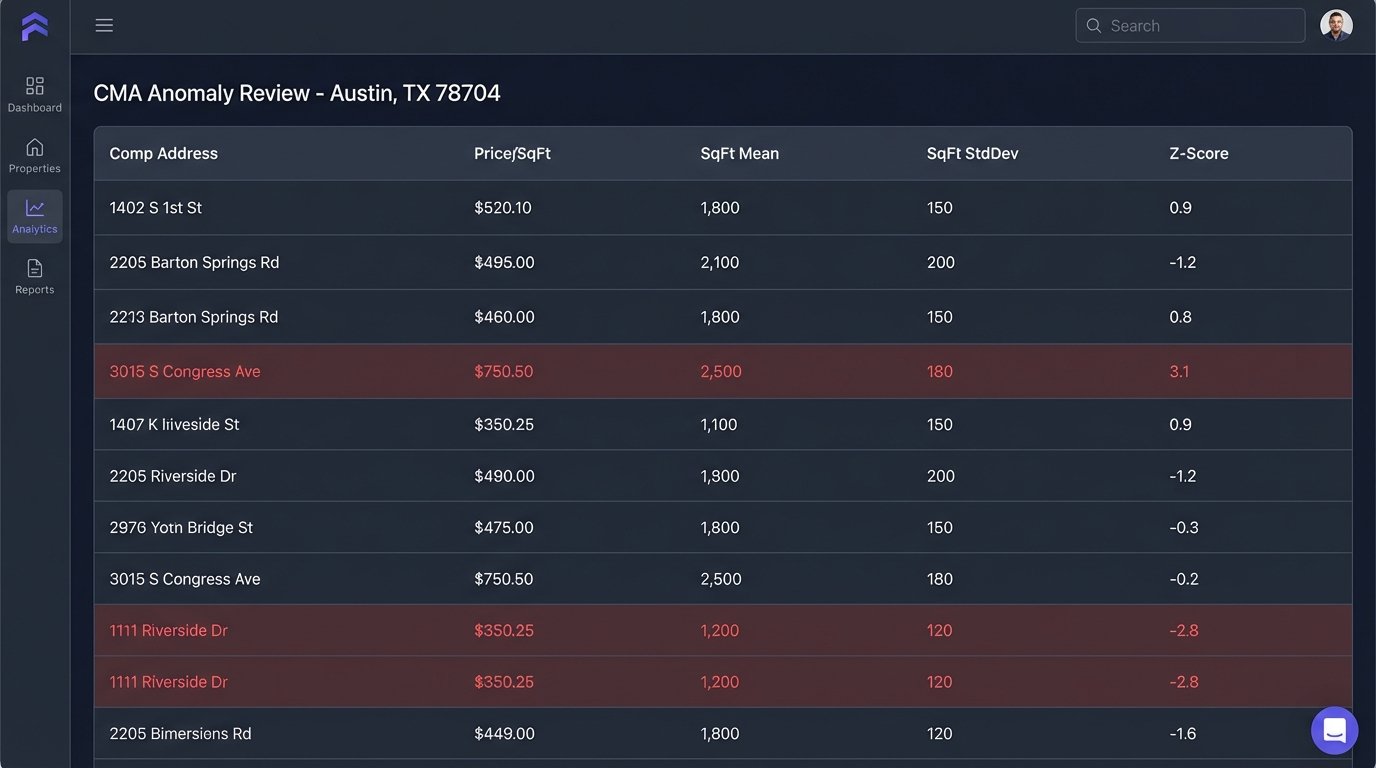
A Comparative Market Analysis is the foundation of every real estate valuation. It is also easily manipulated by cherry-picking comps to support a desired price. This automated metric does not create the CMA. It audits it. It uses statistical methods to flag comparable properties that are significant outliers from the local norm.
The automation pulls a list of all recent sales within a given radius, not just the ones selected by an agent. It then calculates the mean and standard deviation for key features like price per square foot, lot size, and age. Any “comp” used in a CMA that falls more than two standard deviations from the mean for that neighborhood gets flagged for manual review.
You can build this with a direct MLS data feed and some basic statistical functions. The model can be as simple as Z-scores or a more complex algorithm like an Isolation Forest to detect anomalies across multiple dimensions simultaneously. The point is to inject objective mathematical validation into a subjective process.
This system acts as a logic-check on human bias. It will not make you popular with agents who are trying to push a high valuation to win a listing. It will, however, prevent your firm from overpaying for an asset based on a skewed analysis.
Building these automated systems is not about replacing human expertise. It is about focusing that expertise on the exceptions. The automation handles the 99% of properties that fit the expected pattern. The analyst’s job is to investigate the 1% that the system flags as anomalous, risky, or uniquely valuable. That is where the real money is made.