
Most real estate tech stacks are a disaster held together with CSV imports and hope. The core problem is data fragmentation. You have MLS feeds firing off RETS or RESO Web API data, a CRM hoarding agent activity, and a dozen lead-gen platforms all speaking different dialects. Before you can build anything useful, you have to stop the bleeding.
1. A Centralized Data Warehouse, Not Another Silo
The first real investment is boring but non-negotiable: a proper data warehouse. We’re talking about Snowflake, BigQuery, or Redshift. This isn’t just a bigger database. It’s a purpose-built system to ingest, store, and query massive, structurally diverse datasets from every corner of the business. We pipe everything in here: raw MLS JSON blobs, lead source data from APIs, CRM contact records, and website analytics events.
This is the only way to get a single source of truth.
The ELT (Extract, Load, Transform) process is key. We extract raw data from the source, load it directly into the warehouse with its native structure intact, and then use the warehouse’s own compute power to transform it. This bypasses the bottleneck of a traditional ETL server and preserves the original data, which is critical for debugging when a source API changes without notice. We can query nested JSON directly from the MLS feed data to map property features without a brittle pre-processing script.
The cost is the main barrier. These platforms are wallet-drainers if you’re not disciplined with query optimization and compute scaling.
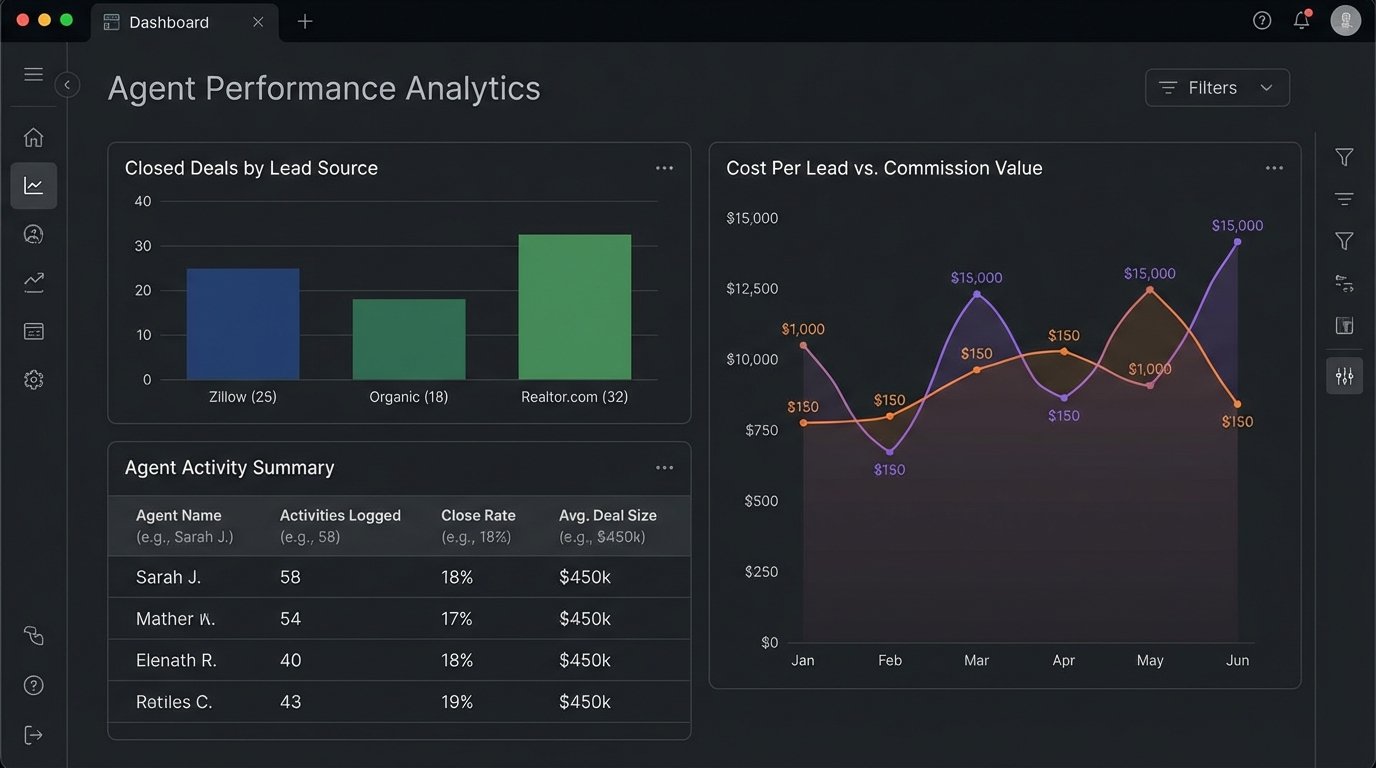
Use Case: Agent Performance Analytics
We can finally join data that never lived together before. By connecting CRM data (calls made, emails sent) with transaction data from the MLS feed, we can build a clear picture of which agent activities actually lead to a closed deal. We can calculate a true cost-per-lead-source by tying ad spend data to the final commission checks, all within a single SQL query.
It stops being about gut feelings and starts being about hard numbers.
2. A Headless CMS to Decouple Content from Presentation
Traditional, monolithic CMS platforms like WordPress are sluggish anchors for a modern real estate brokerage. Every agent page, community guide, and market report is trapped in a rigid theme. Scaling this to thousands of agents or hundreds of hyperlocal landing pages is a technical nightmare. The database becomes a chokepoint, and page load speeds tank, which Google’s ranking algorithms punish without mercy.
A headless CMS rips the content management backend away from the front-end display layer.
We use something like Contentful or Sanity.io to manage the content. Marketing teams get a clean interface to write market reports or update agent bios. The content is then served via an API. The front-end, likely built on a framework like Next.js or Gatsby, fetches this content at build time or on request. This architecture creates blazing-fast static or server-rendered pages that are pure HTML, CSS, and JavaScript. There are no slow database lookups on every page load to render a header.
This approach isn’t a simple install. It demands competent front-end developers who understand how to consume APIs and manage a build process.
Use Case: Hyperlocal SEO Landing Pages at Scale
A firm wants to rank for “homes for sale in [neighborhood name]” for every single neighborhood in a city. With a monolithic CMS, this would mean manually creating hundreds of pages. With a headless setup, a content manager creates a single model for “Neighborhood.” It has fields for a description, market stats, and photos. The developers then write a template that programmatically generates a unique, optimized page for every entry. We can generate 500 landing pages from a single model and a data source.
Trying to manage this volume of content without a decoupled system is like shoving a firehose through a needle. It gets messy, and the pressure breaks things.
3. Custom-Layered Automated Valuation Models (AVMs)
Relying solely on off-the-shelf AVMs from vendors is a strategic error. They provide a baseline, but their models are generic, built on broad county-level data, and are often months behind hyperlocal trends. A home’s value can swing dramatically based on a school district rezoning or the announcement of a new commercial development, factors these national models completely miss. The result is an inaccurate “estimate” that erodes client trust.
The smart investment is to ingest a base AVM feed and then build a proprietary logic layer on top of it.
This means hiring a data scientist or a quantitative analyst. The process involves back-testing the vendor AVM against actual historical sales data from the local MLS to identify its biases. From there, we build regression models that inject hyperlocal factors as new variables. These can be anything from proximity to a new light rail station (geospatial data) to the average price adjustment in a specific subdivision over the last 90 days.
This is a heavy analytical lift, and the models require constant tuning to prevent drift.
Use Case: A More Defensible Home Value Estimate
Instead of just showing a number, the website can show the base AVM and then list the adjustments made by the firm’s proprietary model. For example: “CoreLogic AVM: $500,000. Our Adjustment for Top-Rated School District: +$25,000. Our Adjustment for Recent Neighborhood Comps: +$10,000. Our Estimated Market Value: $535,000.” This transparency builds authority and serves as a powerful lead-generation tool.
A simplified Python example shows the logic of applying a custom factor. This is not production code, but it illustrates the principle of augmenting a base value.
class CustomAVM:
def __init__(self, base_avm_value, property_features):
self.value = base_avm_value
self.features = property_features
def apply_school_district_multiplier(self):
# Logic to fetch multiplier for a specific school district
district = self.features.get('school_district')
if district == 'Northwood High':
# This multiplier would come from a statistical model
self.value *= 1.05
def apply_proximity_adjustment(self):
# Logic to check distance to a key amenity
distance_to_park = self.features.get('distance_to_park_km')
if distance_to_park is not None and distance_to_park < 0.5:
self.value += 10000 # Add a fixed value for park proximity
def get_final_valuation(self):
self.apply_school_district_multiplier()
self.apply_proximity_adjustment()
return int(self.value)
# Example Usage
property_data = {
'school_district': 'Northwood High',
'distance_to_park_km': 0.3
}
base_value = 500000
custom_model = CustomAVM(base_value, property_data)
final_price = custom_model.get_final_valuation()
# final_price would be (500000 * 1.05) + 10000 = 535000
4. API-First CRM Implementation
Many brokerages are stuck with legacy CRMs that are glorified digital rolodexes. They are data prisons. Getting information in or out requires manual CSV uploads or brittle, third-party connectors that break if someone looks at them wrong. Automation is an afterthought, bolted on with clumsy workflows that barely function. This creates enormous friction for agents and zero visibility for leadership.
The fix is to select a CRM based on the quality and documentation of its API.
Modern platforms like Salesforce (if you can afford the army of consultants) or more focused real estate CRMs are built API-first. This means every action you can take in the user interface can also be executed programmatically. This philosophy shift is critical. It allows us to build robust, server-side integrations that are not dependent on a user being logged in or clicking a button. We can force data consistency and automate complex business logic.
A powerful API also means the integration burden is on you. It gives you the tools to build, but you have to supply the labor.
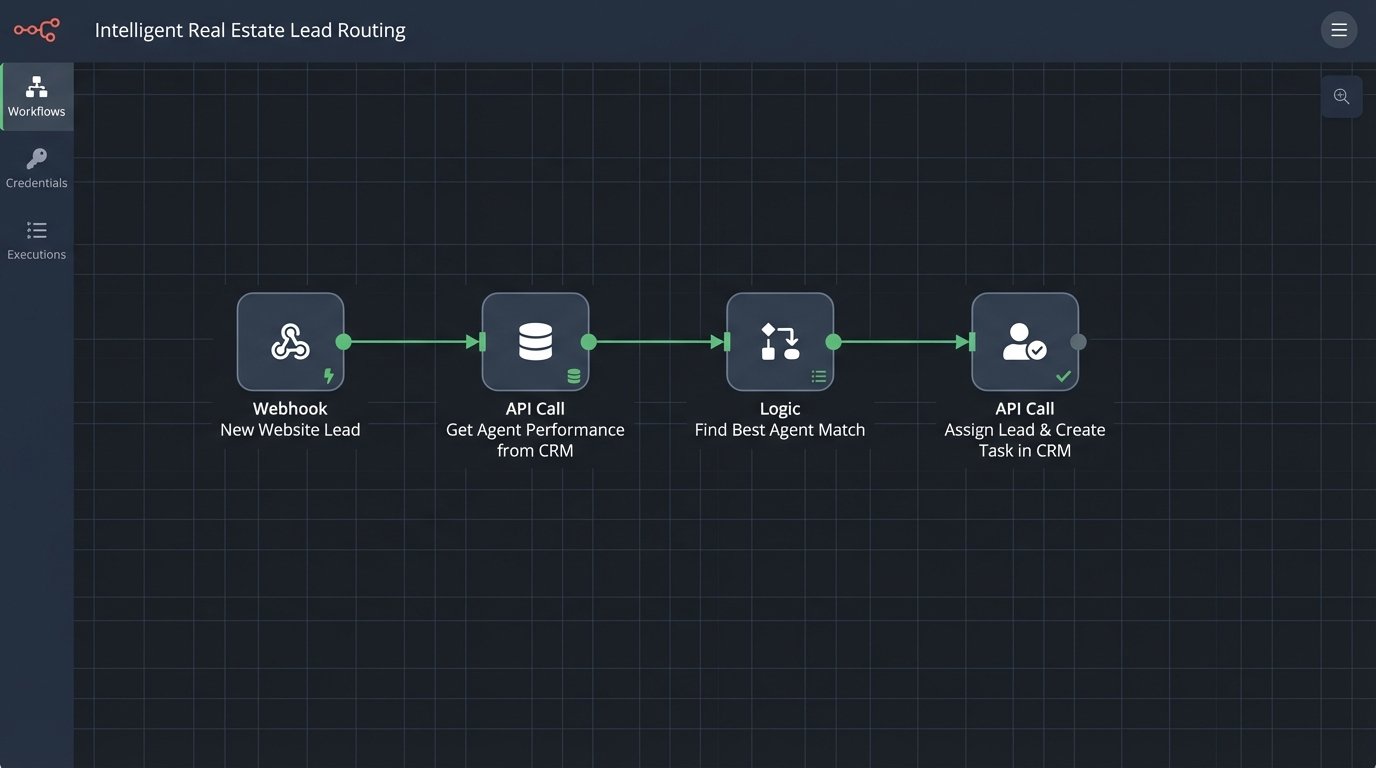
Use Case: Intelligent Lead Routing
A new lead comes in from the website. Instead of just emailing a distribution list, a serverless function is triggered. This function hits the CRM’s API to get data on agent performance. It checks who specializes in the lead’s neighborhood, who has the best close rate for that price point, and who currently has the lowest number of active leads. The function then programmatically assigns the lead to the optimal agent and creates a follow-up task in the CRM. The entire process takes less than a second and requires zero human intervention.
5. Geospatial Data Processing and Layering
Showing a property as a pin on a Google Map is table stakes. It provides almost no real context. Top firms differentiate themselves by layering other datasets onto their maps to tell a richer story. This is about answering the questions a buyer has before they even think to ask them: Is this home in a flood zone? What are the boundaries for the elementary school? How long is the commute to downtown during rush hour?
This requires an investment in geospatial tools and data.
This means moving beyond basic mapping APIs and into platforms like PostGIS (a spatial database extender for PostgreSQL), Esri’s ArcGIS, or the more advanced features of Mapbox. These tools allow you to store, index, and query data based on its physical location. We can ingest shapefiles for floodplains from FEMA, parcel data from the county, and school district boundaries from the local education authority. Then, we can run spatial queries, like “select all properties within this school district boundary that are not inside this flood zone.”
Sourcing and licensing this data is a significant operational hurdle. Government data is often messy and requires extensive cleaning, while commercial data is expensive.
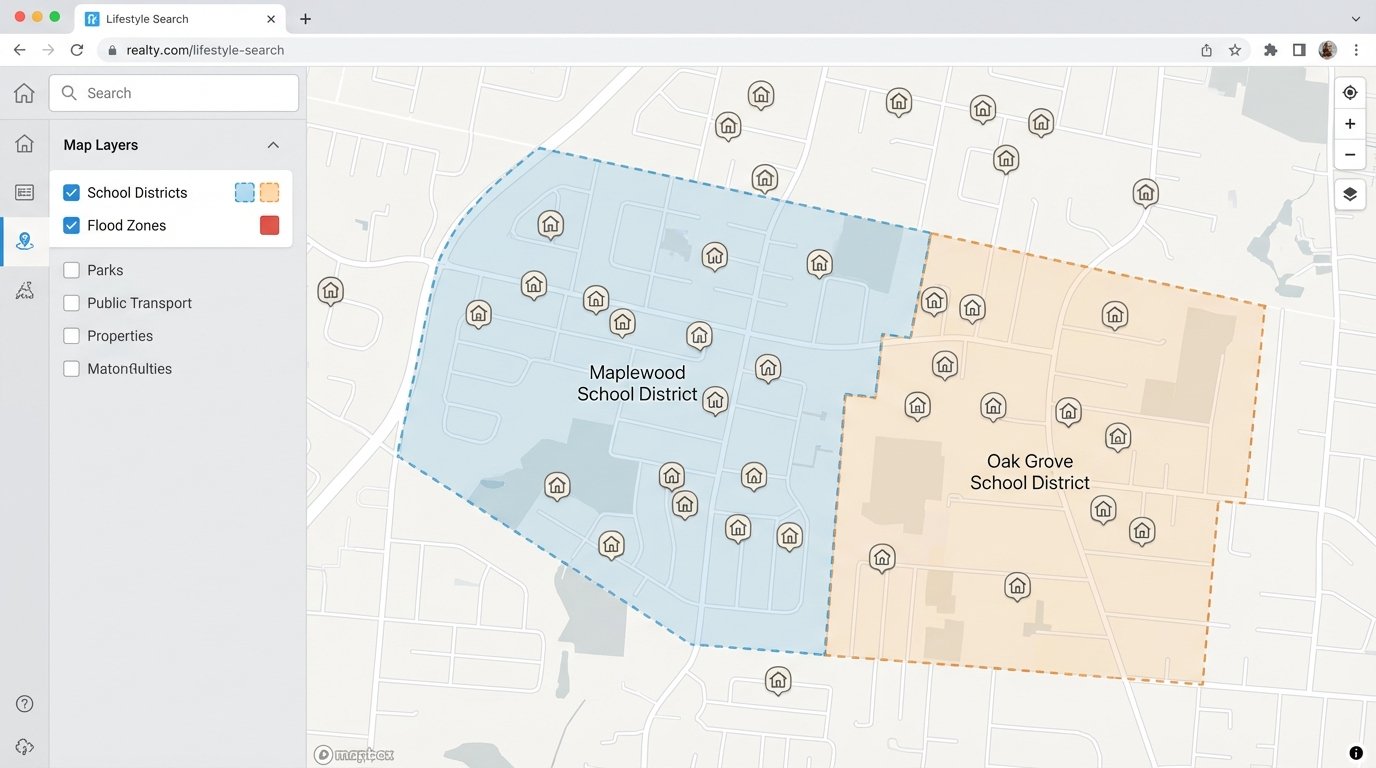
Use Case: The “Lifestyle Search”
A firm can build a search interface that goes far beyond beds and baths. A user can draw a polygon on a map and ask for all listings within a 15-minute drive of their office. They can filter for properties zoned for a specific middle school or properties within walking distance of a grocery store. This turns the property search from a data filtering exercise into a true discovery tool, providing immense value to the user and capturing high-intent leads.
6. Automated Transaction Management Systems
The period between a signed contract and the closing table is where operational inefficiency kills profits and deals. It’s a chaotic mess of PDF attachments, missed deadlines, and manual data entry by transaction coordinators who are buried in paperwork. Each file is a potential lawsuit if a deadline is missed or a signature is forgotten. Relying on checklists in a spreadsheet is not a scalable or defensible process.
The solution is to structure this chaos with an automated workflow system.
Platforms like DocuSign Rooms or a custom-built solution can automate this entire lifecycle. When a property goes under contract, a new “room” or transaction file is created automatically via an API call from the CRM. The system uses predefined templates to auto-generate the necessary documents, pulling data directly from the MLS and CRM to pre-populate fields. Task lists are automatically assigned to the agent, the coordinator, and the client with calendar reminders.
The single biggest challenge here is agent adoption. Forcing a team of independent contractors to adopt a rigid new process is a massive exercise in change management.
Use Case: Compliance and Error Reduction
A brokerage can enforce its compliance rules programmatically. The system can be configured so that a commission disbursement form cannot be generated until the required compliance documents are uploaded and approved by a broker. This logic-checks the process, reducing the risk of a file being closed with missing paperwork. It transforms the role of the transaction coordinator from a data-entry clerk to a true project manager, focused only on the exceptions and problems that require human intervention.