Stop Building Schedulers That Lie
A 24/7 automated scheduler that can’t handle concurrency is not an asset. It’s a liability generating double-bookings and angry phone calls. The core failure isn’t the UI or the notification system. The failure is almost always rooted in a naive approach to state management. Your system’s primary job is to be the single, authoritative source of truth for availability. When it fails at that, it’s useless.
Most scheduling platforms fall apart when two users attempt to book the same 10:00 AM slot. The classic race condition happens between the “check availability” call and the “write booking” call. In that gap, another process can swoop in and claim the slot, leading to a catastrophic data integrity failure. You have to design defensively from the first line of code.
Pessimistic Locking is Your First Line of Defense
Optimistic locking is fine for wikis, not for transactional systems where a conflict means lost revenue. For scheduling, you need to assume the worst. Pessimistic locking, implemented at the database level, is the most direct way to prevent race conditions. The process involves locking the specific time slot resource row in the database for the duration of the transaction. Any other process trying to access that same row is forced to wait until the first transaction is committed or rolled back.
This approach isn’t free. It introduces latency because processes have to wait. If your transactions are slow, holding locks for too long can bring the system to a crawl. You must keep the code inside the transaction block brutally efficient. Fetch the data, lock the row, perform the update, and commit. Nothing else.
A simplified SQL transaction looks like this:
BEGIN TRANSACTION;
-- Select the timeslot and lock the row from other transactions
SELECT * FROM timeslots
WHERE property_id = 123 AND slot_time = '2024-10-26 10:00:00'
FOR UPDATE;
-- Logic to check if the slot is still available (it should be, because of the lock)
-- If available, update it to 'booked'
UPDATE timeslots
SET status = 'booked', user_id = 456
WHERE id = 789;
COMMIT;
If you screw up your transaction logic, you will get deadlocks. Guaranteed.
The Calendar API is Not Your Friend
Your scheduler has to sync with external calendars like Google Calendar or Outlook. These APIs are slow, have aggressive rate limits, and their documentation is frequently a work of fiction. Never make your core scheduling logic dependent on a synchronous round-trip call to a third-party calendar API. That is a recipe for a system that times out under moderate load.
The correct architecture is asynchronous. Your internal database is the source of truth. The booking is confirmed instantly based on your internal state. A separate, asynchronous job is then queued to sync that state to the external calendars. This job needs to be built with retries, exponential backoff, and a circuit breaker pattern. If the Google Calendar API is down, your system should not stop taking appointments. It should queue the sync jobs and process them when the API recovers.
Treating time zones as a simple offset is like trying to map a globe onto a napkin. You will lose entire continents of context. All internal timestamps must be stored as UTC. No exceptions. When you receive a request, you immediately convert the user’s local time into UTC. When you display a time to a user, you convert the UTC timestamp back to their specified time zone. The IANA time zone database is the only reliable source for this, so use a library that implements it properly.
Forgetting to account for Daylight Saving Time will cause your scheduler to be off by an hour for half the year.
State Machines for Appointment Lifecycle Management
An appointment is not a single database row. It is an object with a lifecycle. It starts as `PENDING_CONFIRMATION`, moves to `CONFIRMED`, can be `RESCHEDULED`, and finally ends as `COMPLETED` or `CANCELED`. Managing these state transitions with simple boolean flags in your database is a path to unmaintainable code. Each state should have clearly defined entry and exit criteria.
A formal state machine forces you to think through all possible transitions. For example, a `COMPLETED` appointment cannot transition back to `CONFIRMED`. An agent cannot confirm an appointment that a user has already `CANCELED`. Implementing a state machine, either with a library or your own simple logic, makes these business rules explicit in the code. This prevents impossible state changes and makes the system’s behavior predictable and auditable.
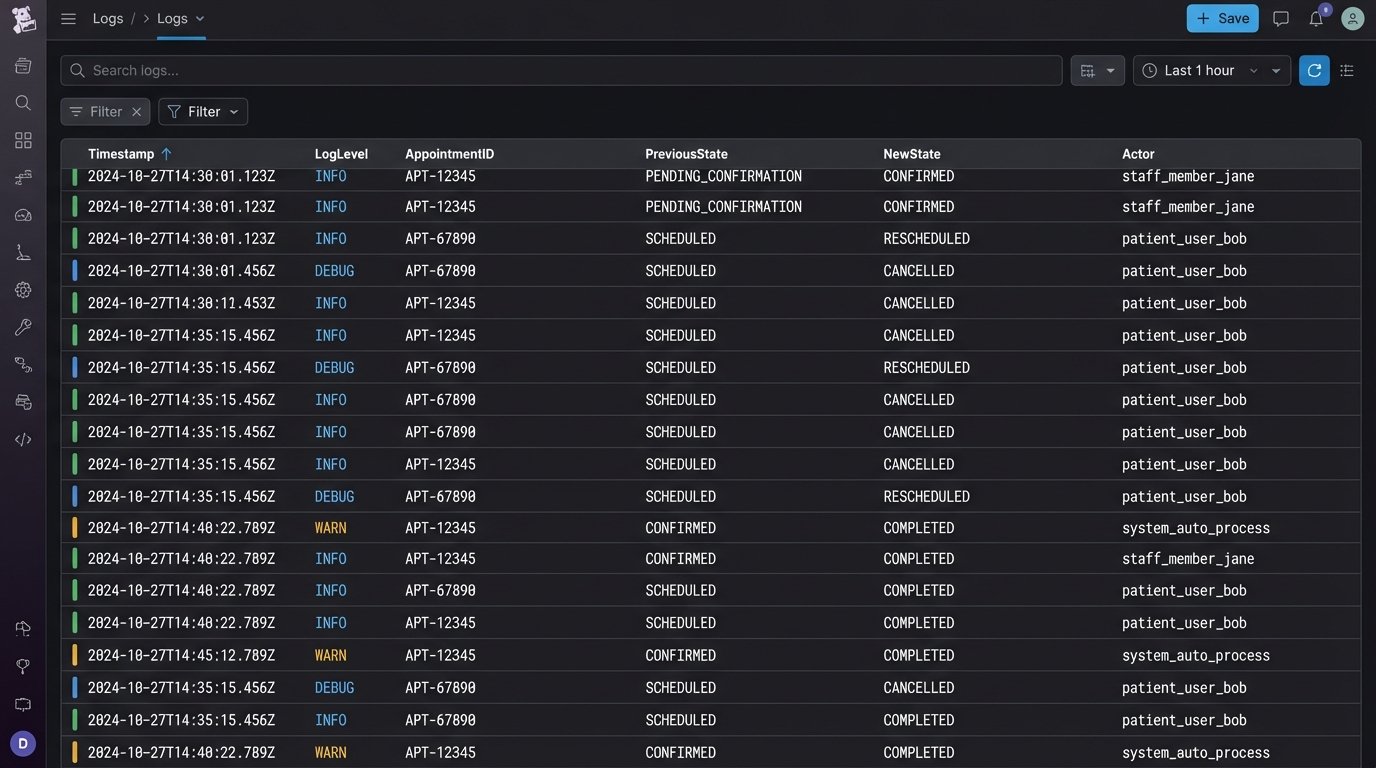
This is where you log every single state transition. The log should include the appointment ID, the previous state, the new state, the actor who triggered the change (user, agent, system), and a timestamp. When something goes wrong, this audit trail is invaluable for debugging.
Idempotency in Notifications and Webhooks
What happens if your notification service sends the “Appointment Confirmed” email twice? Or your webhook to the CRM fires three times for the same event because of a network hiccup and a faulty retry mechanism? The receiving system creates duplicate records, and the user gets spammed. Every external communication from your scheduler must be idempotent.
Idempotency means that performing the same operation multiple times produces the same result as performing it once. For API calls and webhooks, this is often handled by including a unique idempotency key in the request header. The server checks for this key. If it has seen the key before, it doesn’t process the request again. It just returns the same successful response it sent the first time. For emails or SMS, this is harder. The best you can do is generate a unique event ID for each notification and log it immediately before attempting to send. Your retry logic can then check this log to avoid re-queueing a job that has already been processed.
Without idempotency, your system will eventually corrupt downstream data.
Build for Failure: Logging and Monitoring
Your scheduler will fail. APIs will go down. Users will input bad data. The database will deadlock. The question is not if it will fail, but how quickly you can diagnose and fix it. Generic log messages like “Error processing appointment” are worthless. You need structured logging.
Every log entry should be a JSON object containing consistent fields. At a minimum, include a precise timestamp, log level, a correlation ID that ties together all operations for a single request, the service name, and a clear message. More importantly, include the relevant context. For a failed booking, log the `property_id`, `user_id`, and `requested_timeslot`. This lets you search and filter your logs effectively without having to piece together a story from a dozen disconnected text lines.
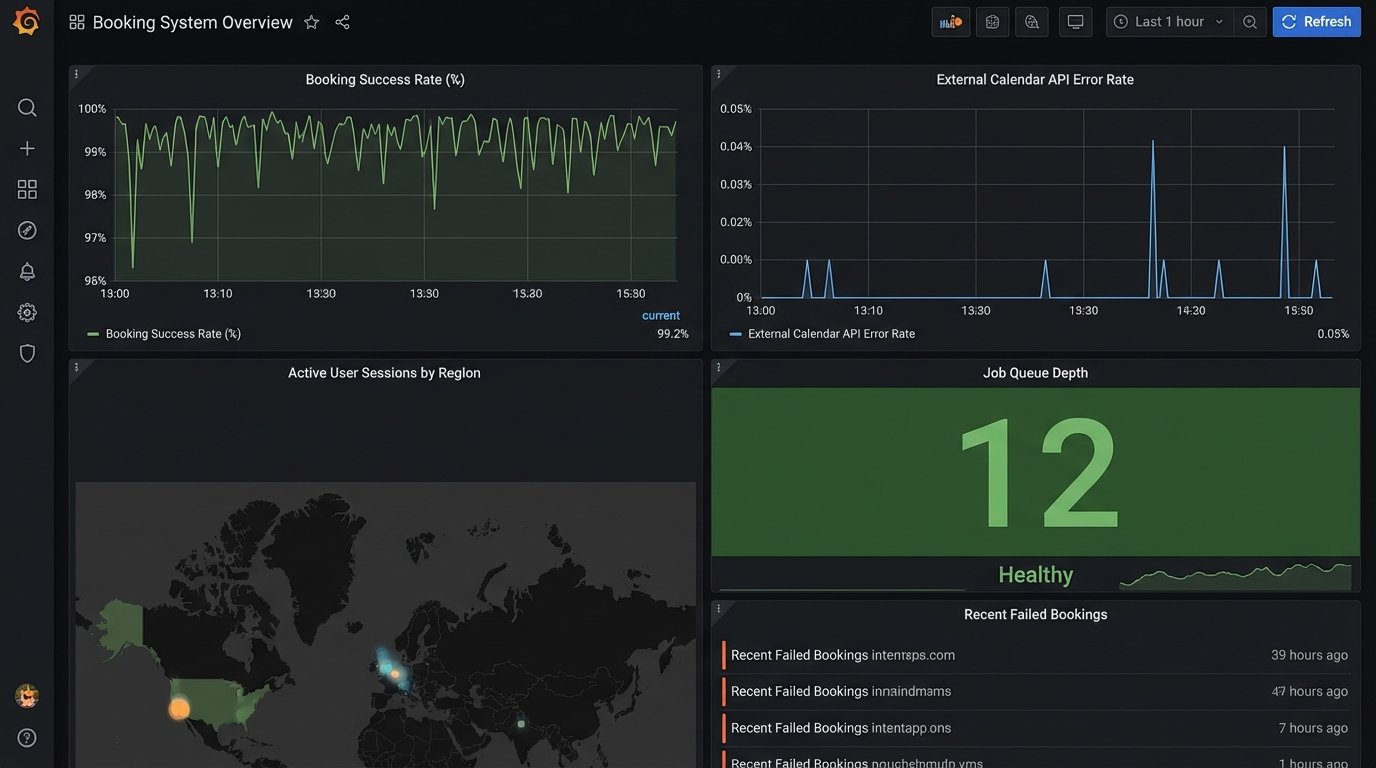
Your monitoring should go beyond CPU and memory usage. Create dashboards that track key business metrics.
- Booking Success Rate: The percentage of booking attempts that succeed. A sudden drop indicates a systemic problem.
- API Error Rate: The failure rate for calls to third-party calendars. A spike here means an external dependency is broken.
- Job Queue Depth: The number of pending jobs in your asynchronous queues. If this number is constantly growing, your workers can’t keep up.
These metrics tell you about the health of the application, not just the server it runs on.
Buffer Times and Agent Availability Are Not Simple Rules
A showing is not instantaneous. You need to implement configurable buffer times before and after each appointment. A 15-minute buffer prevents back-to-back showings that don’t account for travel time or conversations running long. This logic should be part of the availability calculation. When a 10:00 AM slot is booked for 30 minutes, your system must automatically block out 9:45-10:00 AM and 10:30-10:45 AM.
Agent availability is even more complex. It’s not a static 9-to-5 schedule. It’s a combination of their base schedule, one-off overrides, existing appointments pulled from their synced calendar, and even property-specific showing restrictions. You must build a flexible rules engine that can layer these constraints. The final availability for a given property at a given time is the intersection of all applicable rules. Trying to manage this with a single table and a few `if` statements is a fast track to chaos.
This is where trying to build everything in-house becomes a wallet-drainer. You spend months reinventing a poor version of a rules engine that already exists.
Garbage In, Garbage Out: Input Validation
Never trust data from the client. Every incoming request to your API must be rigorously validated before it touches your business logic. This is not just about checking for required fields. It’s about enforcing data types, ranges, and formats. Is the email address a valid format? Is the requested `timeslot` on the hour or half-hour, as your business rules require? Is the `property_id` a valid integer and does it actually exist in your database?
Forcing this validation at the edge of your system, in the API controller or a middleware layer, keeps your core domain logic clean. Your service layer can operate on the assumption that it is receiving sanitized, valid data. This separation of concerns simplifies the code and reduces the surface area for bugs. A single invalid date format string can crash an entire booking process if it’s not caught early.
A scheduler that can be crashed by a bad request is not a 24/7 scheduler.