
API security isn’t a feature you bolt on at the end. It’s a foundational requirement that gets ignored until a production database is sitting on a public S3 bucket. Most breaches aren’t sophisticated attacks; they are the direct result of a developer taking a shortcut, a misconfigured permission, or a blindly trusted third-party endpoint. We are building systems where services talk to each other over networks, and assuming any part of that chain is secure by default is negligence.
The goal is not to create an impenetrable fortress. That’s a fantasy. The goal is to create layers of defense that make a breach so difficult and noisy that it’s not worth the effort. Forget the marketing slides. This is about practical, often tedious, work that keeps systems running and data safe.
Authentication Is Not Authorization
This is the most fundamental concept people get wrong. Authentication confirms who you are. Authorization dictates what you are allowed to do. Confusing the two is how a user with read-only access ends up deleting production records. A valid API key proves the request is from a known client. It says nothing about whether that client should be able to access a specific resource or perform a certain action.
Stop using static API keys for anything beyond a simple, public data feed. They are glorified passwords, often hardcoded in repositories or passed around in Slack messages. The moment one leaks, you have to revoke it and redeploy every service that uses it. It’s a brittle and dangerous architecture. Implement a proper token-based system like OAuth 2.0 or OIDC. Short-lived access tokens force clients to re-authenticate periodically, drastically reducing the window of opportunity for a compromised credential.
OAuth 2.0 grants are the mechanism to control this. The client credentials grant is for machine-to-machine communication. The authorization code grant is for user-facing applications. Use the right tool for the job. Force scope limitations on every token. If a service only needs to read user profiles, its token should only have the `profile.read` scope. A request with that token attempting to call `profile.write` must be rejected with a 403 Forbidden. No exceptions.
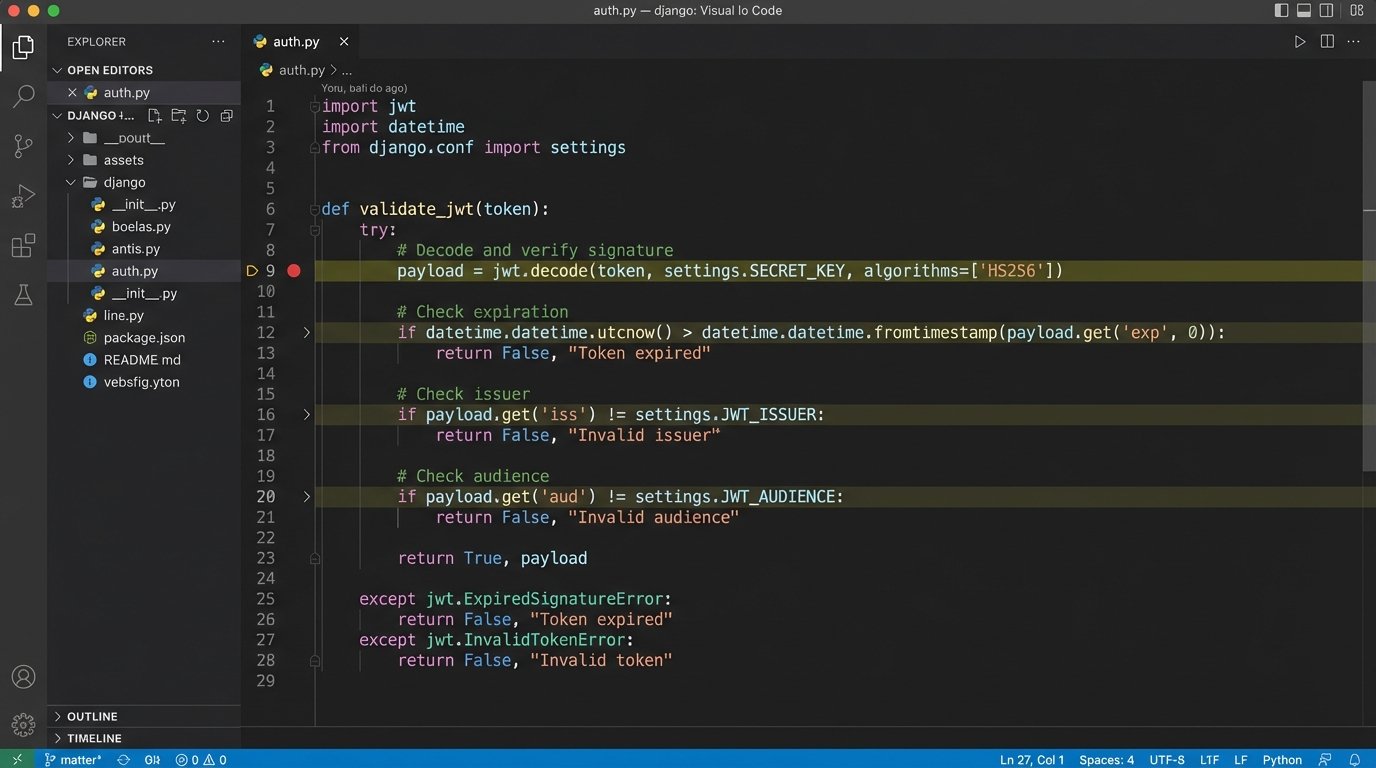
Token Validation Logic
A JSON Web Token (JWT) is not inherently secure. It’s just a signed JSON object. Your service’s first job upon receiving a JWT is to validate it. First, check the signature using the correct public key. Second, check the expiration time (`exp` claim) to prevent replay attacks. Third, check the issuer (`iss`) and audience (`aud`) claims to ensure the token was meant for your specific service. Only after all these checks pass should you even consider looking at the authorization scopes.
Hammer the Inputs
Never trust data coming from an external system. Never. This includes your own company’s microservices if they’re maintained by a different team. Every single piece of incoming data must be validated against a strict schema. This is your primary defense against injection attacks, buffer overflows, and a whole class of deserialization vulnerabilities. Don’t write your own validation logic from scratch; use a battle-tested library for your language, like Pydantic for Python or Zod for TypeScript.
Piping raw user input directly into a database query without sanitization is the digital equivalent of connecting a fire hydrant to your car’s fuel injector. It’s not going to work, and the results will be catastrophic. You must validate for type, length, format, and range. An `order_id` should not be a 2GB string containing executable code. Define your data contracts using a format like OpenAPI Specification (OAS) and enforce them at the API gateway or in your application’s middleware. If a request body doesn’t match the schema, reject it immediately with a 400 Bad Request.
This validation must happen at the edge of your service. Don’t pass tainted data through three internal services before one finally checks it. By then, the malicious data might have been logged, cached, or triggered an unintended side effect in another system. Validate on ingress, and you contain the problem at the source.
The Principle of Least Privilege in Practice
Every system component, from the API gateway to the database connection pool, should operate with the absolute minimum level of permissions required to function. If an integration is only supposed to pull daily reports, give it a read-only database user that can only access the specific views needed for those reports. Don’t give it the master `db_owner` role because it’s faster to configure.
This applies to infrastructure too. If your API is running in a container, its associated IAM role or service account should not have S3 `ListAllBuckets` or `DeleteObject` permissions unless it explicitly needs them. This level of granular control feels like a lot of overhead during development, but it’s what contains a breach. A compromised service with a tightly scoped role can only cause limited damage. A compromised service with `admin` access takes down the entire environment.
A Concrete Example
Consider a service that processes user-uploaded images. It needs to read the image from a temporary S3 bucket and write a thumbnail to a processed S3 bucket. The correct IAM policy grants `s3:GetObject` on `arn:aws:s3:::temp-uploads/*` and `s3:PutObject` on `arn:aws:s3:::processed-thumbnails/*`. That’s it. No `s3:ListBucket`, no permissions on any other bucket, and absolutely no `s3:*` on `*`.
This is not optional. It’s the difference between an attacker stealing one user’s unprocessed photo and an attacker deleting your entire company’s data store.
Encrypting the Internal Network
TLS for public-facing endpoints is obvious. What’s less obvious is the need for TLS on internal, service-to-service communication. The classic “hard shell, soft core” network model is obsolete. Once an attacker gains a foothold inside your network, they can sniff all unencrypted internal traffic with ease. This is how API keys, user data, and other secrets are harvested during the lateral movement phase of an attack.
Implementing mutual TLS (mTLS) is the solution. With mTLS, both the client and the server present and validate certificates to prove their identity before a connection is established. This prevents rogue services from calling your protected endpoints and ensures traffic is encrypted in transit. Service meshes like Istio or Linkerd can automate the certificate rotation and mTLS enforcement, but they add a significant layer of operational complexity. It’s a wallet-drainer in terms of engineering hours, but it plugs a massive security hole.
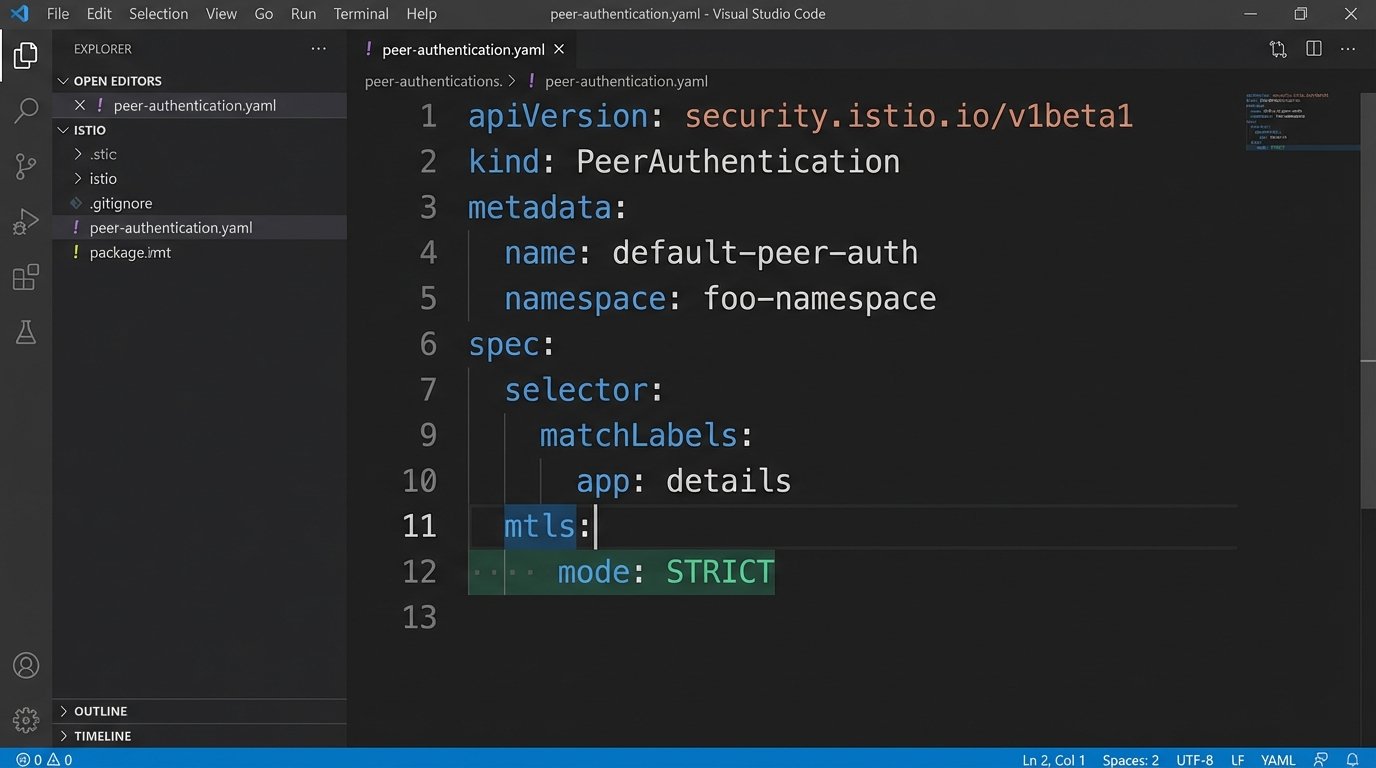
The performance overhead of TLS is often cited as a reason to skip it internally. Modern CPUs have dedicated instruction sets for AES encryption, making the impact minimal for most workloads. The latency added by the TLS handshake is a real factor, but you can mitigate it with connection keep-alives. The security benefits far outweigh the minor performance cost.
Rate Limiting and Throttling Are Not Just for DDOS
Everyone implements rate limiting to stop denial-of-service attacks. That’s its primary function. A less appreciated function is preventing cascading failures and controlling costs. If a misconfigured client starts calling a third-party API in a tight loop, you’re not just risking a DDOS; you’re risking a five-figure bill from your provider. A simple bug can become a financial incident.
Implement multiple layers of rate limiting.
- Per IP: Protects against classic DDOS from a single source.
- Per User/API Key: Prevents a single authenticated user from abusing the system.
- Global: Protects the overall stability of the service.
Your API gateway is the logical place to enforce this. Configure sensible defaults for your endpoints. A login endpoint might be limited to 5 attempts per minute per IP, while a data retrieval endpoint might allow 100 requests per minute per API key. When a client exceeds the limit, return a `429 Too Many Requests` status code with a `Retry-After` header indicating when they can try again. This provides a clear, machine-readable signal to well-behaved clients.
Here’s a barebones example of setting a timeout in a Python request, a fundamental part of client-side resilience that prevents a slow API from locking up your worker processes.
import requests
try:
# Set a timeout for connect and read phases (in seconds)
response = requests.get('https://api.example.com/data', timeout=(3.05, 27))
response.raise_for_status() # Raise an exception for bad status codes (4xx or 5xx)
except requests.exceptions.Timeout:
# Handle timeout error
print("Request timed out.")
except requests.exceptions.RequestException as e:
# Handle other request errors (e.g., connection error, bad status code)
print(f"An error occurred: {e}")
This simple `timeout` parameter is a circuit breaker. Without it, your application could hang indefinitely waiting for a response from a dead or overloaded dependency.
Your Post-Mortem Toolkit: Meaningful Logging
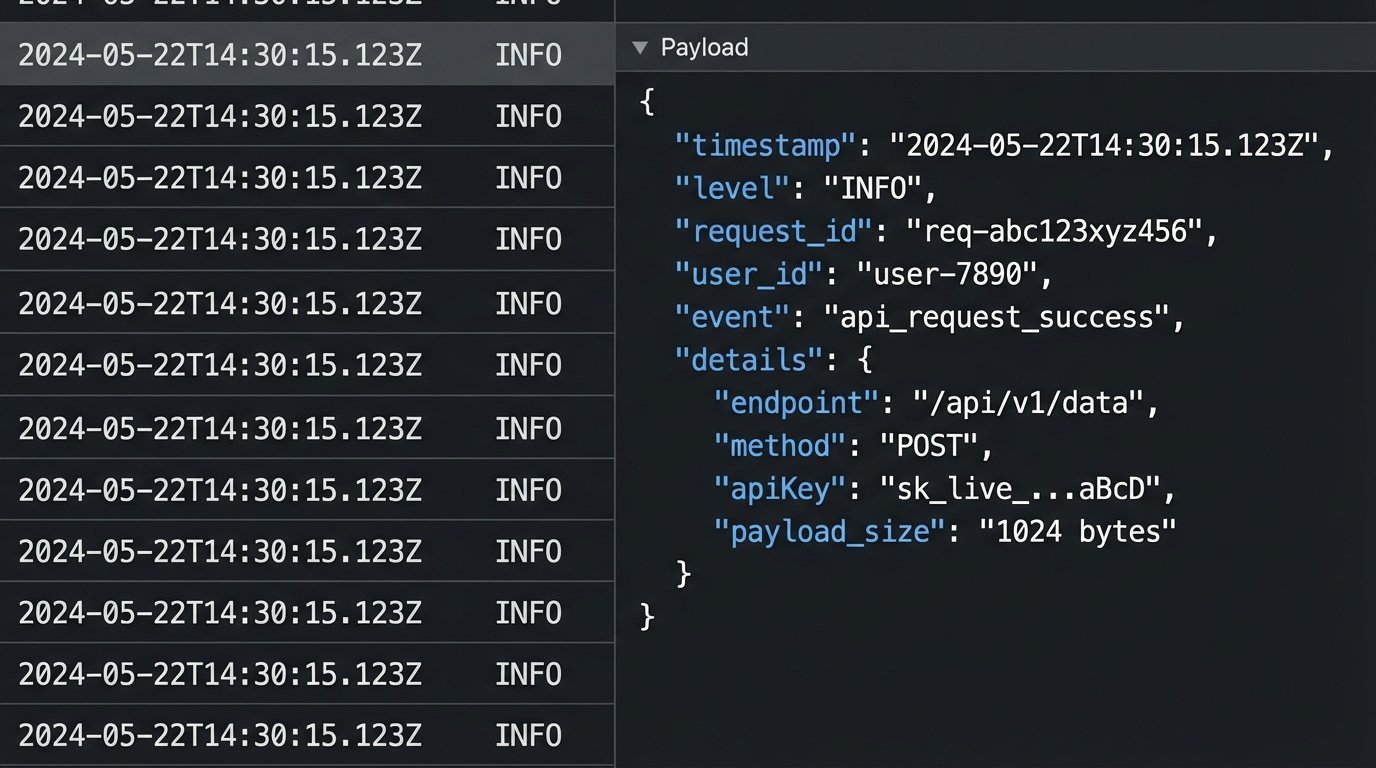
When an integration fails at 3 AM, logs are your only window into what happened. But a stream of useless “INFO: Processing request” messages is just noise. Good logs are structured, searchable, and contain context. Log the request ID, the authenticated user or service principal, the source IP address, and the specific action being performed. Use a structured format like JSON so you can easily filter and aggregate logs in a system like Elasticsearch or Splunk.
Just as important is what you *don’t* log. Never log sensitive data in plaintext. This includes passwords, API keys, session tokens, and personally identifiable information (PII). A breach of your log aggregation system should not automatically become a full-scale data breach. Use data masking techniques to redact sensitive fields before they are written to disk. Log “credit_card_number”: “************1234”, not the full number.
Your logging level should be configurable at runtime. In normal operation, you might log at the `INFO` level. During an incident, you need the ability to dynamically switch a specific service to `DEBUG` to get verbose output without redeploying the application. This is critical for rapid diagnostics. Treat your logging pipeline with the same respect you treat your production database. It’s a critical piece of infrastructure.