
Selecting Real Estate Software That Won’t Implode Your Stack
Most articles on choosing real estate software are written for project managers. They talk about user interfaces, feature sets, and ROI calculators. This is not one of those articles. This is for the architects and engineers who get paged when the data sync fails, the API key mysteriously invalidates, or the entire lead pipeline grinds to a halt because of a vendor’s undocumented schema change. We’re not evaluating a product. We’re inheriting a dependency, and that requires a different level of scrutiny.
Forget the sales demo. The glossy front-end is irrelevant. The real product is the API. That is the engine you have to bolt onto your own. If that engine is a sputtering mess held together with legacy code and wishful thinking, the beautiful chassis it sits in means nothing.
The API is the Product, The UI is a Wrapper
Before you even look at a user dashboard, demand the API documentation. If they send you a password-protected PDF from five years ago, end the conversation. A modern, viable platform will have a public or semi-public developer portal with a clear OpenAPI or Swagger specification. This isn’t a “nice-to-have.” It is the bare minimum for conducting a technical evaluation.
You must logic-check their API for basic sanity. Pay close attention to authentication. An API that still relies on static keys passed as URL parameters is a security incident waiting to happen. Look for OAuth 2.0 implementation. Then, examine the error handling. A system that returns a generic 500 error for everything from a missing field to a full database crash is functionally useless for automated workflows. You need granular, documented error codes that your scripts can actually parse and act on.
A well-structured error response tells you what broke and why. A lazy one just tells you something broke.
Consider this hypothetical Python snippet to test an endpoint. It’s not about the code’s complexity, it’s about what the response tells you. Does it give you a structured JSON error payload, or just a useless HTML error page?
import requests
import json
headers = {
'Authorization': 'Bearer YOUR_ACCESS_TOKEN',
'Content-Type': 'application/json'
}
# Intentionally send a malformed payload
payload = json.dumps({
"listing_address": "123 Main St",
"price": "950000", # Price as string instead of integer
"agent_id": None # Missing required field
})
response = requests.post('https://api.vendor.com/v2/listings', headers=headers, data=payload)
print(f"Status Code: {response.status_code}")
# Does this print a clean JSON object with error details, or a wall of text?
print(response.json())
A good API returns a 400 or 422 status with a body like `{“error”: “Invalid type for field ‘price’. Expected integer, got string.”}`. A bad one returns a 500 and forces you to dig through logs. That difference is your weekend.
Interrogate the Data Schema
The second critical failure point is the data model. Inconsistent naming conventions, ambiguous data types, and a lack of clear relationships between objects will force you to write mountains of brittle transformation code. Your ETL jobs will become a collection of edge-case handlers designed to compensate for the vendor’s messy architecture. This is not sustainable.
Request a full data dictionary. Look for obvious red flags. Is the primary key for a property called `property_id` in one endpoint and `listingID` in another? Is a timestamp an ISO 8601 string in one place and a Unix epoch in another? These small inconsistencies multiply into massive data integrity problems. Trying to force these two systems to talk is like shoving a firehose of unstructured data through the needle-eye of your clean database schema.
The data model must be versioned. Ask the vendor how they handle schema changes. If they tell you they just add new fields and “it won’t break anything,” they are either lying or incompetent. A non-versioned API is a ticking time bomb. A single field removal or type change in their backend can shatter your production environment without warning. A versioned API (e.g., `/api/v1/leads`, `/api/v2/leads`) gives you control over the upgrade path.
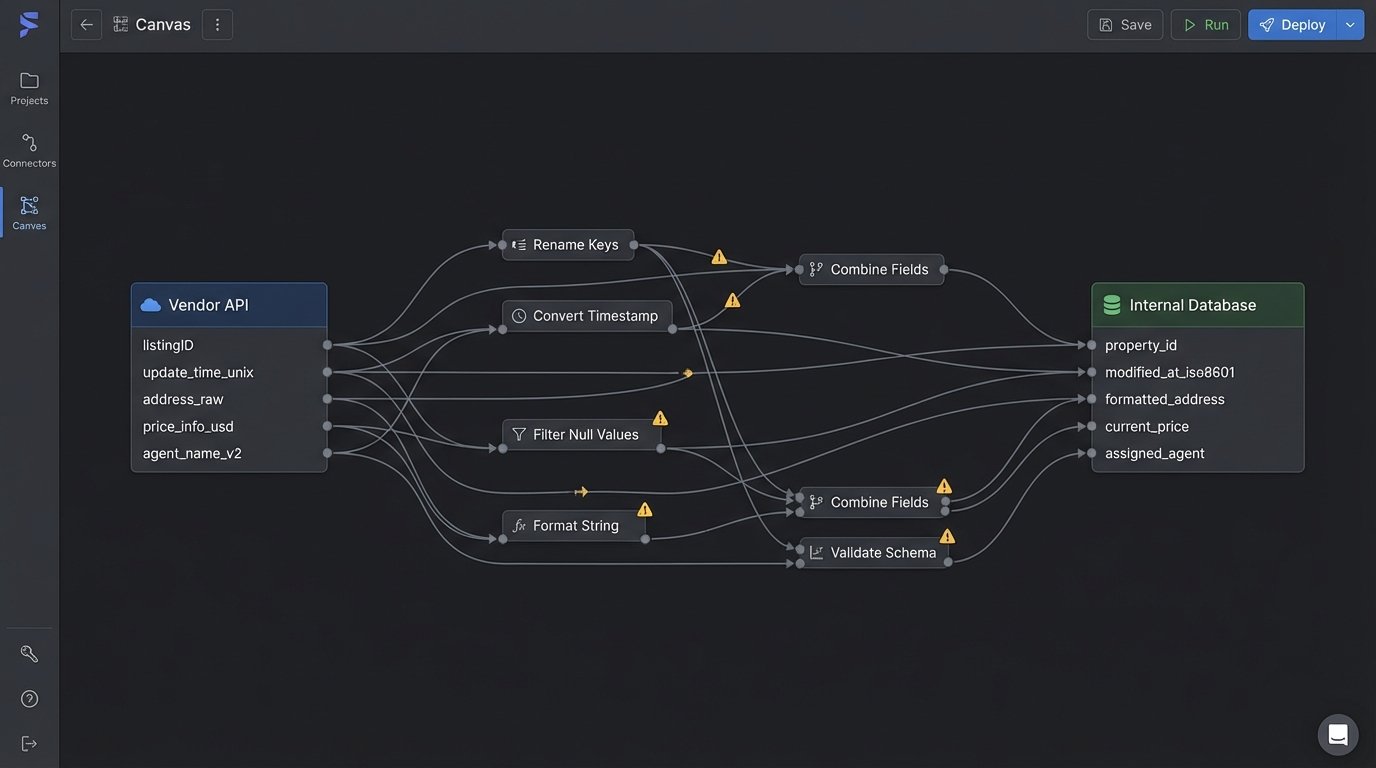
You need to map their core objects to your own before signing anything. Can you cleanly represent their `Contact` object as your `Lead`? How many hoops must you jump through to connect their `Showing` records to your `AgentCalendar`? If this mapping process looks like a complex web of joins and conditional logic, walk away. The initial pain of integration will be nothing compared to the long-term cost of maintenance.
Vendor Lock-in is a Technical Debt Mortgage
Business teams think of vendor lock-in as a contractual problem. For engineers, it’s a crippling architectural constraint. The key question is not “Can we leave?” but “What is the technical cost of leaving?” The answer lies in data portability. How do you get your data out of the system, in bulk, in a format that isn’t proprietary garbage?
Look for a bulk export API or, at minimum, a documented database dump process. If the only way to extract your data is to paginate through their `GET` endpoints one record at a time, you are being held hostage by their rate limits. An export of a million records, 100 at a time, with a 1-second delay between calls, takes over two and a half hours. That’s not a data export, that’s a denial-of-service attack on your own operations.
The format of that export matters. Insist on open formats like CSV, JSON, or Parquet. If they provide a proprietary file format that can only be read by their own special tool, your data is not your own. You are renting it. Pay special attention to identifiers. If their entire system hinges on a proprietary `guid` that has no meaning outside their ecosystem, migrating that data to a new platform means you lose all historical context. You must be able to use your own internal identifiers or industry standards like RESO’s `ListingKey`.
- Good Sign: A documented, rate-limit-exempt bulk export API that delivers data in JSONL or CSV.
- Bad Sign: The only export option is a “Print to PDF” button in the UI.
- Disaster Sign: The sales engineer doesn’t know what a bulk export is.
Load Test Their Staging, Not Their Sandbox
A demo in a pristine sandbox environment proves nothing. That environment has a dozen records and one user. Your production environment has millions of records and thousands of concurrent requests. Performance in the sandbox is a fantasy. You need to get access to a staging or UAT environment that mirrors the architecture and data scale of their actual production systems.
Once you have access, hammer it. Don’t just test the simple `GET /records/{id}` endpoint. Test the complex, high-value queries. How does it perform when you ask for all listings in a specific zip code with three or more bedrooms, sorted by price, with associated agent data joined? That’s the query that will actually run in production, and that’s the one that will time out under load.
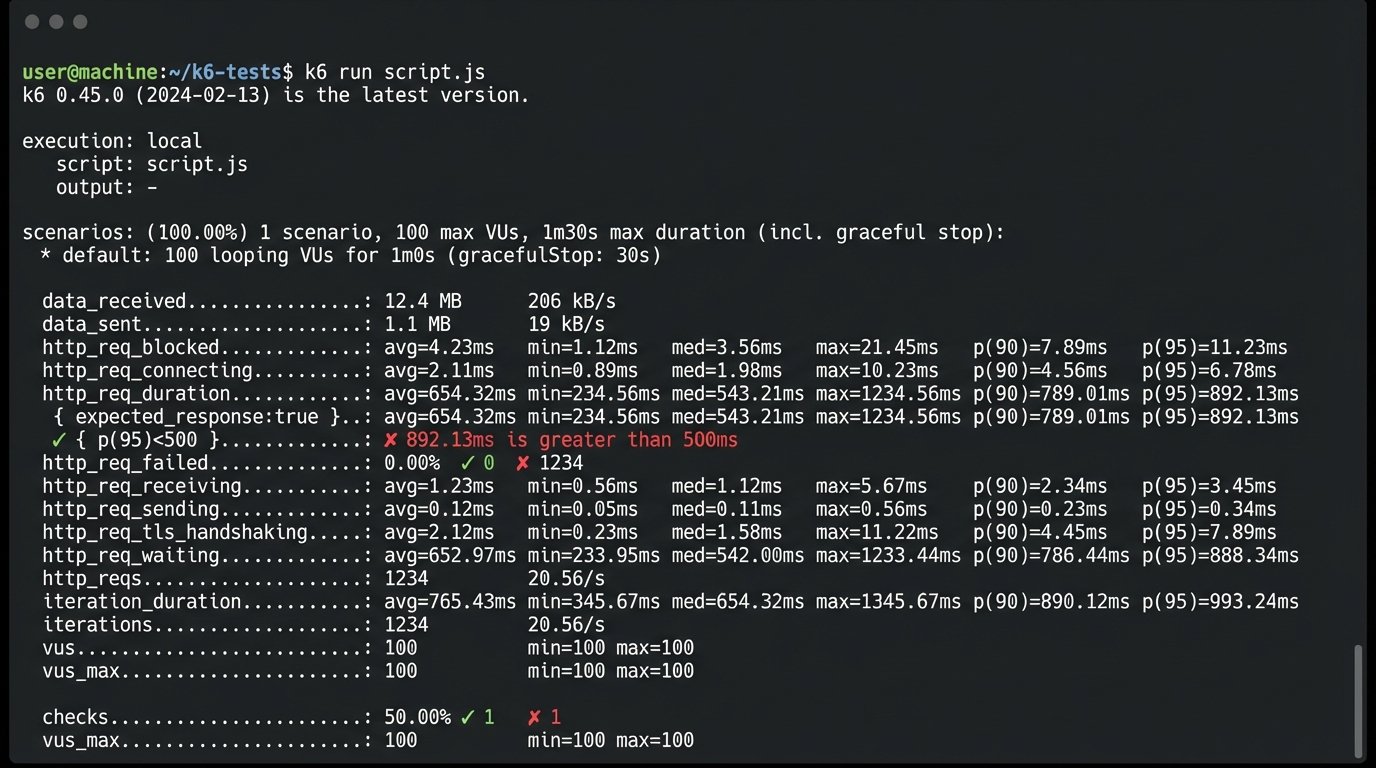
A simple k6 script can give you a baseline. It’s not a comprehensive test, but it will expose fundamental weaknesses that a UI demo never will. A system that can’t handle 50 virtual users hitting a search endpoint without response times spiking is not ready for production.
import http from 'k6/http';
import { sleep, check } from 'k6';
export const options = {
stages: [
{ duration: '30s', target: 20 }, // Ramp up to 20 users
{ duration: '1m', target: 20 }, // Stay at 20 users
{ duration: '10s', target: 0 }, // Ramp down
],
thresholds: {
'http_req_duration': ['p(95)<500'], // 95% of requests should be below 500ms
},
};
export default function () {
const res = http.get('https://staging-api.vendor.com/v1/listings?q=complex_query');
check(res, { 'status was 200': (r) => r.status == 200 });
sleep(1);
}
The results of this test are non-negotiable. If their p(95) response time for a critical query is over a second, your own application’s performance will suffer. Their slow API becomes your problem.
Logging and Auditing Aren’t Optional Features
The integration will fail. Not “if,” but “when.” The moment it does, your only tools are the logs. If the vendor’s platform provides no accessible, structured logging of API requests and responses, you are flying blind. Debugging becomes a nightmare of trying to correlate timestamps between your system and a black box.
You must verify what level of audit trail is available. Can you see the exact request payload your system sent? Can you see the exact response the vendor’s system returned? Without this, any troubleshooting conversation devolves into a finger-pointing exercise. “We sent the correct data.” “No, you didn’t.” The logs are the objective truth. Insist on seeing them.
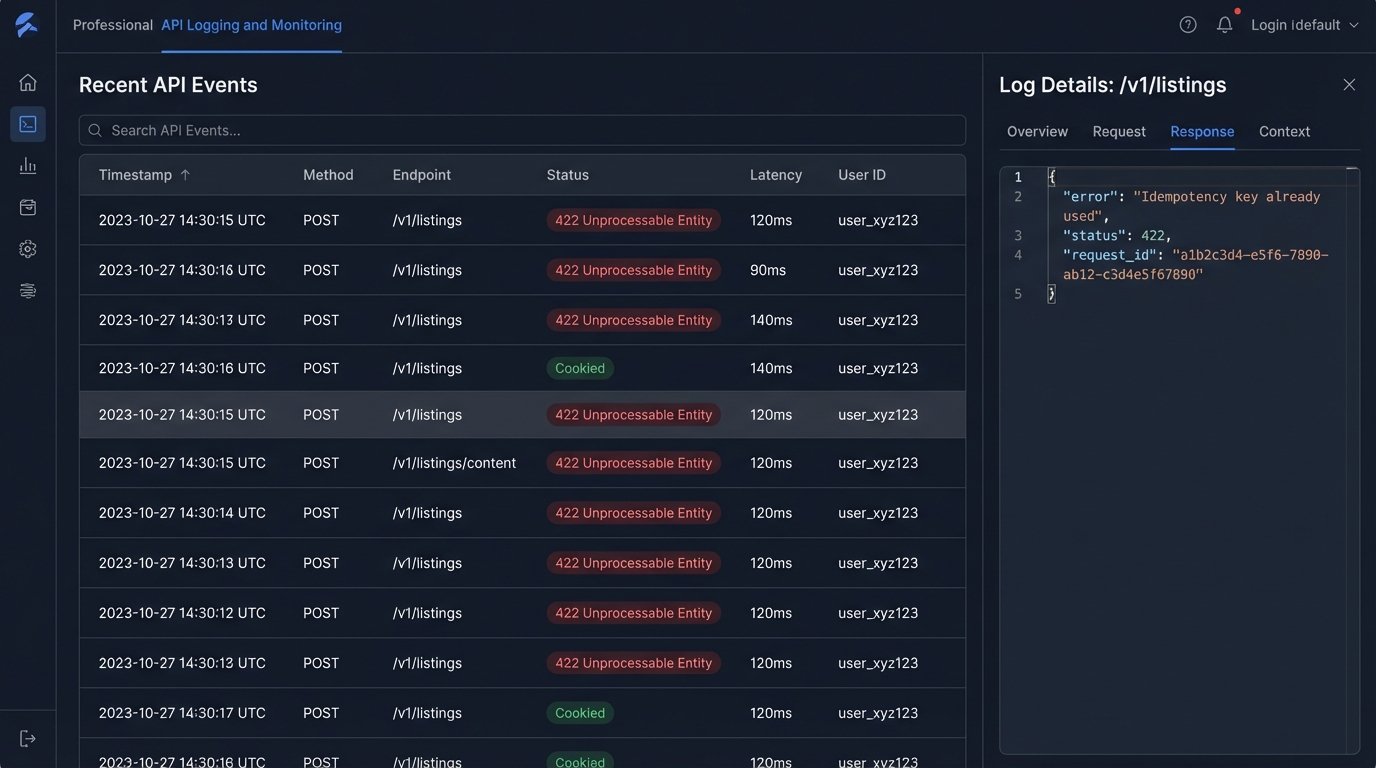
For any endpoint that creates or modifies data, especially financial or transactional data, check for support for idempotency keys. An idempotency key is a unique identifier you send with your API request. If the request is interrupted by a network blip and your system retries, the vendor’s API sees the same key and knows not to process the request twice. Without it, you risk creating duplicate payments, duplicate contacts, and duplicate listings. Trying to de-duplicate a production database after the fact is a high-risk, low-reward operation.
A platform without idempotency support for critical write operations is not an enterprise-grade system. It is a liability.
Choosing a software vendor isn’t about finding the best features. It’s about risk mitigation. You are chaining another system to your own architecture. Do the due diligence to ensure those chains are made of steel, not rust.