
Case Study: Automating Commission Disbursement with Custom APIs
Manual commission processing is a known point of failure. At a previous engagement, a mid-sized SaaS company was bleeding 40 hours of a senior finance analyst’s time every month to a process built on spreadsheets and prayer. The system involved exporting CSVs from Salesforce, applying calculations through a fragile chain of VLOOKUPs, and manually uploading the results to a payment processor. The error rate hovered around 5%, creating payment delays and destroying sales team morale.
The core task was to stop the bleeding. We needed to gut the manual process and replace it with a system that could execute complex, multi-tiered commission logic without human intervention. This wasn’t about building a simple script. It was about architecting a durable, auditable, and fault-tolerant transaction engine.
The Anatomy of the Failure
The legacy workflow was a textbook example of technical debt. A sales operations manager would pull a raw transaction report from Salesforce. This CSV file contained deal size, product type, close date, and account executive ID. The file was then handed over to the finance department, where the analyst began the painful process of reconciliation.
Multiple commission plans existed simultaneously. A plan for strategic accounts had different accelerators than the plan for the mid-market team. New hires had a separate ramp-up structure. The analyst had to manually identify which plan applied to each line item and calculate the payout. This manual sorting and calculation was the primary source of errors.
Once calculated, the data was pasted into another CSV template required by the payment gateway. Mismatched column headers or incorrect data formatting would cause the entire upload to fail with cryptic error messages. The whole Rube Goldberg machine was slow, opaque, and a massive compliance risk. There was no clean audit trail, just a folder of spreadsheets with names like `Commissions_April_Final_v3_FINAL.xlsx`.
Solution Architecture: A Serverless Data Bridge
We rejected building a monolithic application. The process was fundamentally event-driven, or in this case, schedule-driven. A serverless architecture using AWS Lambda was the logical choice. It eliminated server management overhead and allowed us to build a focused function that did one thing: process commissions. The entire workflow was orchestrated by Amazon EventBridge, triggering the master Lambda function on the first day of each month.
Our stack was lean. The core logic was written in Python for its data manipulation libraries. We used AWS Secrets Manager to handle API credentials for Salesforce and Stripe Connect. All execution logs were piped to CloudWatch for monitoring and alerting. The goal was observability, not a black box that might or might not have worked.
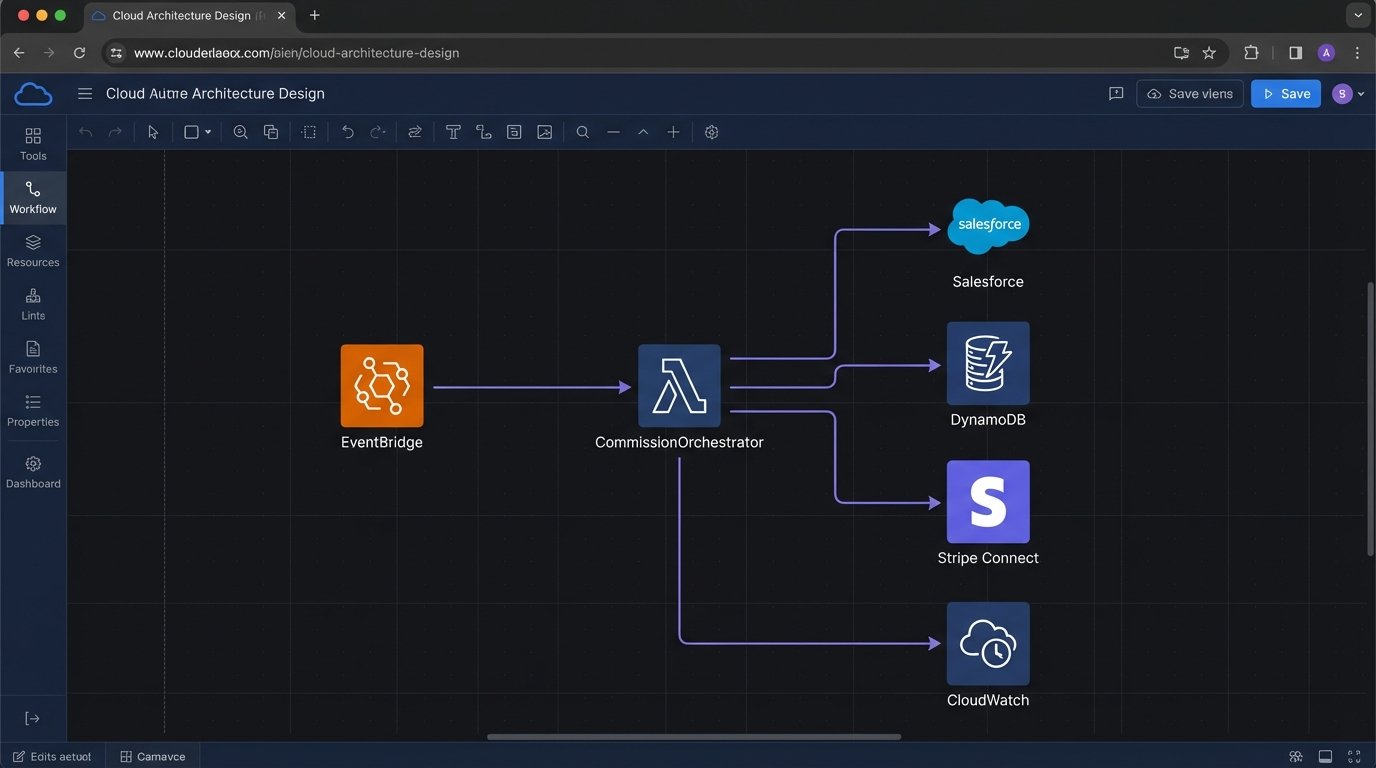
The process breaks down into four distinct stages. Each stage acts as a gate for the next. A failure in any stage halts the process and triggers an alert. We were not going to automatically pay anyone until multiple logic-checks passed.
Stage 1: Data Extraction from the Source of Truth
The first step was to bypass the manual CSV export. We needed to pull data directly from Salesforce. The standard reporting API endpoints proved to be sluggish and heavily throttled. They also had a nasty habit of omitting certain custom fields that were critical for our commission logic. This forced us to go deeper and use the Salesforce Object Query Language (SOQL) to pull exactly what we needed.
We built a targeted SOQL query to fetch closed-won opportunities within the previous month. The key was to be surgical. We only pulled the fields required for the calculation: `Amount`, `AccountId`, `OwnerId`, `CloseDate`, and a few custom fields defining the product tier. Pulling the entire Opportunity object would have bloated the payload and pushed us against API limits faster. Reconciling all the various data sources felt like trying to thread a dozen needles at once with a single piece of frayed string.
This is a simplified look at the type of query we ran using the `simple-salesforce` Python library.
from simple_salesforce import Salesforce
sf = Salesforce(username='user', password='pwd', security_token='token')
# Get last month's date range
# ... logic to define start_date and end_date ...
soql_query = f"""
SELECT Id, Amount, CloseDate, OwnerId, Custom_Product_Tier__c
FROM Opportunity
WHERE StageName = 'Closed Won'
AND CloseDate >= {start_date}
AND CloseDate <= {end_date}
"""
records = sf.query_all(soql_query)['records']
The `query_all` method was critical. It handled the API’s pagination for us, preventing us from having to build our own looping and offset logic to fetch record sets larger than 2,000. It’s a small detail that saves a lot of headaches.
Stage 2: The Commission Logic Engine
Getting the data was the easy part. The real complexity was in replicating and automating the tiered commission rules. Hardcoding these rules into the Python script would have been a catastrophic mistake. The sales compensation plan changes at least once a year. We needed a solution that allowed the finance team to update the rules without requiring a developer to redeploy the Lambda function.
We externalized the rules into an Amazon DynamoDB table. This table became our logic engine’s source of truth. Each item in the table represented a rule with attributes like `min_deal_size`, `max_deal_size`, `product_tier`, and the corresponding `commission_rate`. The finance team was given a simple web interface (built separately) to manage these rules.
The Python function would first pull the current rule set from DynamoDB. Then, for each sales record pulled from Salesforce, it would iterate through the rules to find a match. This decoupled the business logic from the execution code. It made the system flexible and reduced our long-term maintenance burden.
Stage 3: Pre-Flight Validation and Integrity Checks
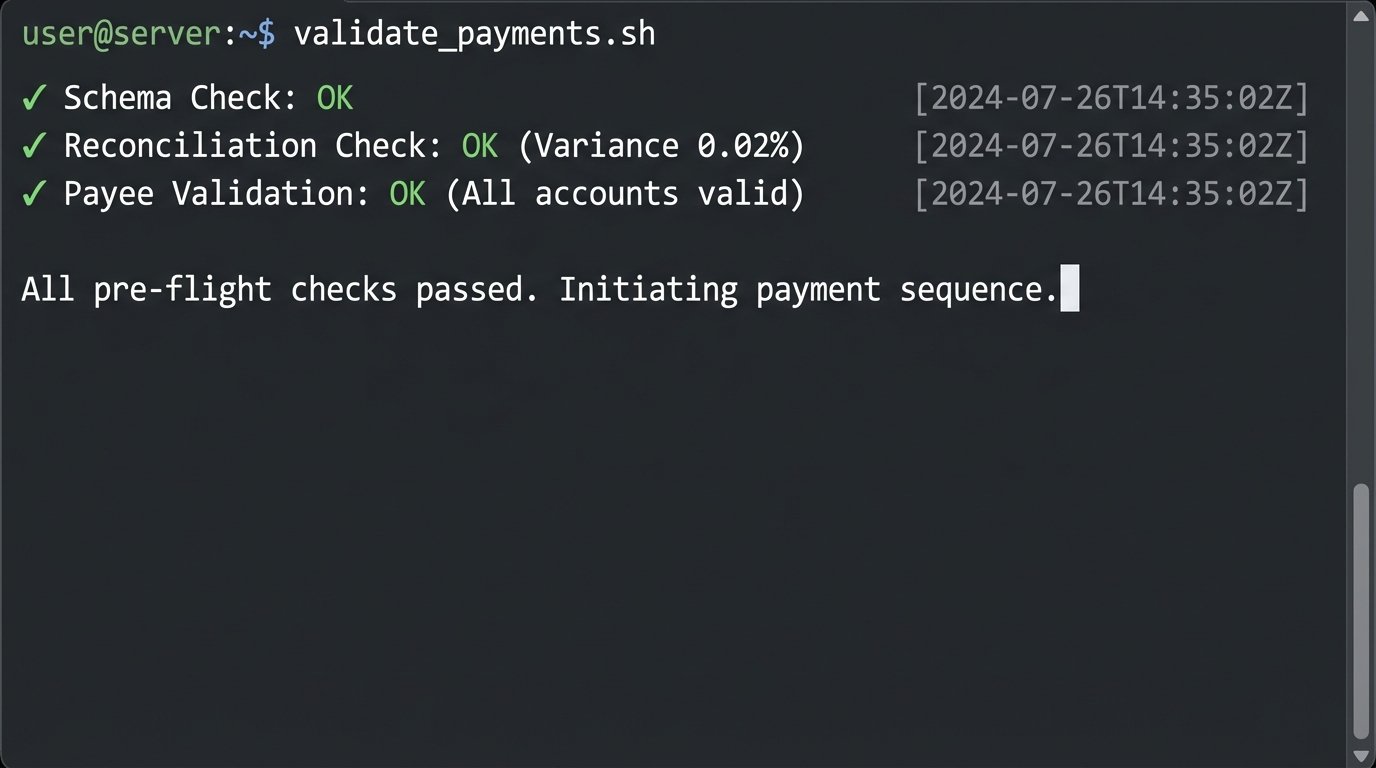
Before a single API call was made to the payment processor, we injected a mandatory validation stage. We have all been burned by systems that blindly push bad data. This stage was designed to catch errors before they cost money. We implemented several checks.
- Schema Check: Did the data from Salesforce contain all expected fields? If a sales admin added or removed a field, we needed the process to stop and alert us.
- Reconciliation Check: The sum of all calculated commissions was compared against a control total. If the variance exceeded a 0.1% threshold, the process would halt for manual review.
- Payee Validation: We performed a lookup against the payment processor’s API to ensure that every `OwnerId` from Salesforce corresponded to a valid, payable account. This prevented failures caused by sales reps who had left the company but still had deals close in their name.
This validation step was the most important part of the entire architecture. It’s the circuit breaker that prevents a small data issue from becoming a massive financial and operational problem. It’s not glamorous, but it’s what separates a production-grade system from a proof-of-concept.
Stage 4: Disbursement via Stripe Connect
With validated and calculated data in hand, the final step was to execute the payments. We used Stripe Connect, which provides APIs for making payouts to connected accounts. For each line item in our final commission data, we constructed an API call to create a transfer to the appropriate sales representative’s account.
One non-negotiable requirement for any payment integration is the use of an idempotency key. This is a unique identifier you send with your API request. If a network error occurs and you have to retry the request, sending the same idempotency key guarantees that the operation is not performed twice. Without it, you risk double-paying commissions during a network glitch.
import stripe
import uuid
stripe.api_key = 'sk_test_...'
# Generate a unique key for this specific payment attempt
idempotency_key = str(uuid.uuid4())
try:
transfer = stripe.Transfer.create(
amount=150000, # amount in cents
currency="usd",
destination="{{CONNECTED_STRIPE_ACCOUNT_ID}}",
transfer_group="Commissions_2023_04",
headers={'Idempotency-Key': idempotency_key}
)
except stripe.error.StripeError as e:
# Handle API errors, log, and alert
print(f"Stripe API error: {e}")
The `transfer_group` parameter was also useful. It allowed us to batch all payments for a given month under a single, searchable identifier within the Stripe dashboard. This simplified reporting and reconciliation on their end.
Navigating Production Realities
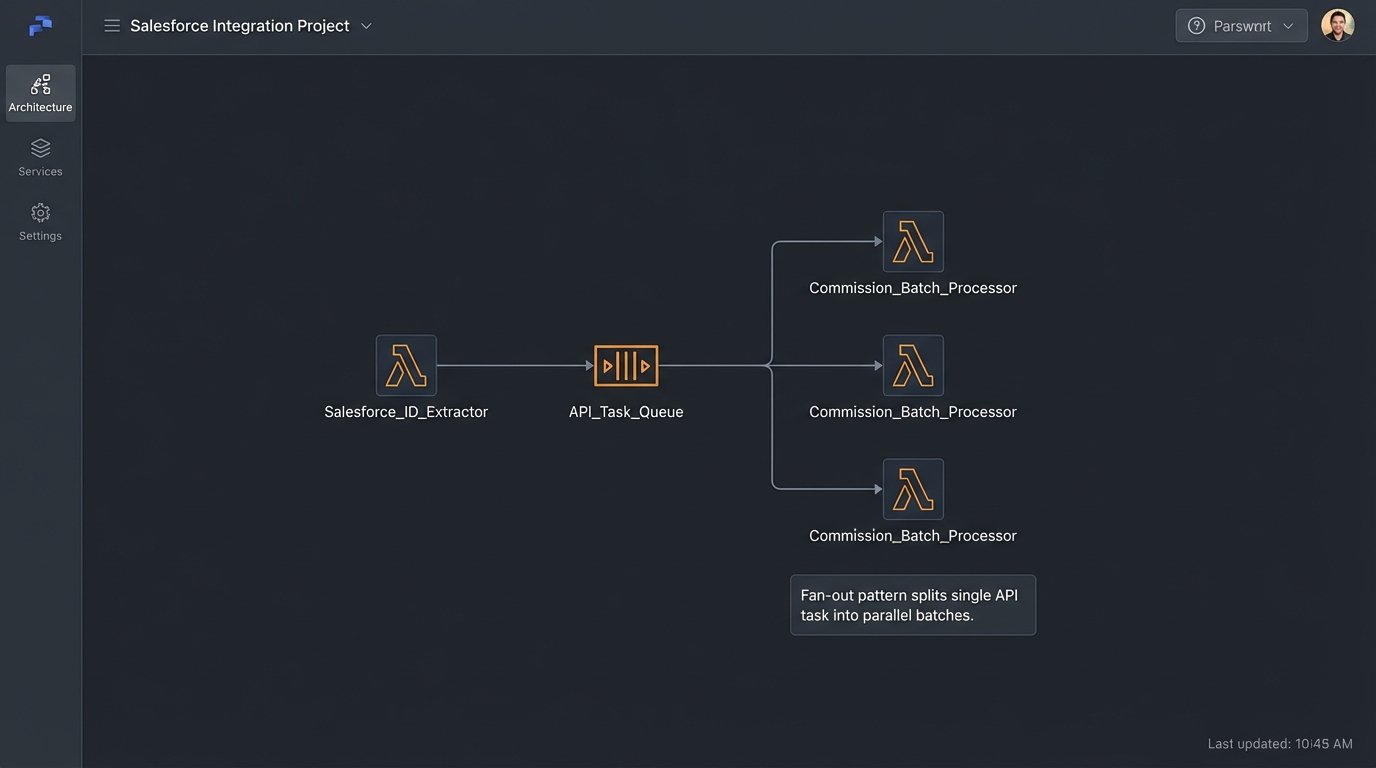
The initial build went smoothly, but production is always a different beast. We hit two major roadblocks. First, Salesforce API limits. During peak load, with thousands of opportunities to process, we started getting `REQUEST_LIMIT_EXCEEDED` errors. The solution was to re-architect the extractor. Instead of one large Lambda function, we created a “fan-out” pattern. A master function queried for record IDs only, then pushed those IDs onto an SQS queue. A second pool of Lambda functions then processed items from the queue in small, independent batches. This distributed the API load and kept us under the concurrency limits.
The second problem was data drift. The finance team adjusted the commission rules in DynamoDB but introduced a typo, which caused the logic engine to fail to match any rules. The system correctly halted, but the alerts were not specific enough. We enhanced the logging to pinpoint the exact rule that was malformed and included that detail in the Slack notification. The goal is to reduce the mean time to resolution. An alert that just says “failed” is useless at 3 AM.
Quantifiable Results and Business Impact
The results were immediate and stark. The new system executed the entire monthly commission run in under 20 minutes, a 99% reduction from the previous 40 hours of manual labor. This freed up a senior analyst to focus on strategic financial planning instead of data entry.
The error rate, previously around 5%, dropped to effectively zero. The pre-flight validation caught all data-related issues before payment execution. The only “errors” we see now are alerts about bad source data in Salesforce, which are routed back to the sales operations team to fix at the source. The system became a data quality enforcement tool by proxy.
Finally, the disbursement timeline shrank. Payments used to go out around the 15th of the following month. With the automation, commissions were calculated and paid by the 2nd business day. This had a measurable impact on sales team satisfaction and trust in the company’s operations. The audit trail is now perfect. Every single calculation and transaction is logged with timestamps, providing a clear, immutable record for compliance and accounting.
This project was not about simply writing a script. It was about building a reliable financial transaction system. The lesson is clear. Do not trust your source data. Do not trust the network. Build for failure, validate everything, and make your systems observable. Otherwise, you’re just building a faster way to make the same old mistakes.