The initial system we found at a mid-market mortgage brokerage was a monument to technical debt. Their lead scoring was a chain of hard-coded `if/else` statements buried in their CRM’s workflow engine. If a lead’s self-reported credit score was over 700 and their loan amount was above $400k, they were flagged as “hot.” This logic missed nuance and treated every lead from a specific postal code as identical, clogging the sales pipeline with false positives.
Sales development representatives were burning 15 to 20 hours a week chasing ghosts. The cost of this waste wasn’t just in salary; it was in the opportunity cost of ignoring genuinely qualified leads who were buried under the noise. The conversion rate from marketing qualified lead (MQL) to sales qualified lead (SQL) was a dismal 8%. The system was broken by design.
Deconstructing the Failure
The core problem was a reliance on static, user-provided data. This data is often inaccurate or incomplete. The old system had no capacity to infer intent or validate information against external sources. It couldn’t distinguish between a C-level executive researching a mortgage for a second home and a student filling out a form with bogus data to download a whitepaper.
We needed a system that could weigh dozens of signals simultaneously, many of them behavioral. The goal was not just to rank leads but to generate a probabilistic score of their likelihood to convert to a closed deal. This requires moving from a rules-based engine to a predictive model. The old logic was like trying to identify a specific vehicle by its color alone, ignoring its make, model, and speed. A statistical model was the only viable path forward.
The Data Ingestion Problem
Before any model could be built, we had to centralize the data. It was scattered across three primary sources: the Salesforce CRM, Google Analytics behavioral logs, and HubSpot marketing engagement records. Stitching these together was the first major hurdle. The only common key was the lead’s email address, which itself was often unreliable.
We built a small data pipeline using Python scripts running on a schedule. These scripts would pull data from each platform’s API, perform a preliminary cleaning and normalization process, and dump the results into a centralized PostgreSQL database. We had to aggressively handle API rate limits, implementing exponential backoff for connection failures and caching results to avoid redundant calls. The initial data pull took 72 hours and exposed just how dirty the source data was.
Building the Predictive Engine
With a unified dataset, we could begin feature engineering. This is where the project’s success was determined. A predictive model is only as intelligent as the data you feed it. We discarded vanity metrics like `total_site_visits` and engineered more potent features that signaled actual intent.
Key features included:
- Behavioral Velocity: The number of key pages (e.g., pricing, loan calculator, contact) visited in the last 7 days. This captures recent interest.
- Content Affinity: A score based on engagement with content related to specific loan types (e.g., FHA, VA, Jumbo).
- Firmographic Signals: We used a data enrichment service like Clearbit to pull in company size and the lead’s job title seniority, but only for non-generic email domains. This was a wallet-drainer, so we built a Redis cache to store enrichment data for domains we had already seen.
- Email Domain Analysis: A simple boolean flag for `is_free_email_provider` (gmail, yahoo, etc.) turned out to be a surprisingly strong negative predictor.
Dumping raw data into a model is a rookie mistake. It’s like shoving a firehose through a needle. You have to strip the signal from the noise first.
Model Selection and Training
We opted for an XGBoost (Extreme Gradient Boosting) model. It’s highly effective on the kind of structured, tabular data we were working with and offers some level of feature interpretability, which was critical for getting sales team buy-in later. A deep learning model would have been overkill and a black box we couldn’t easily explain.
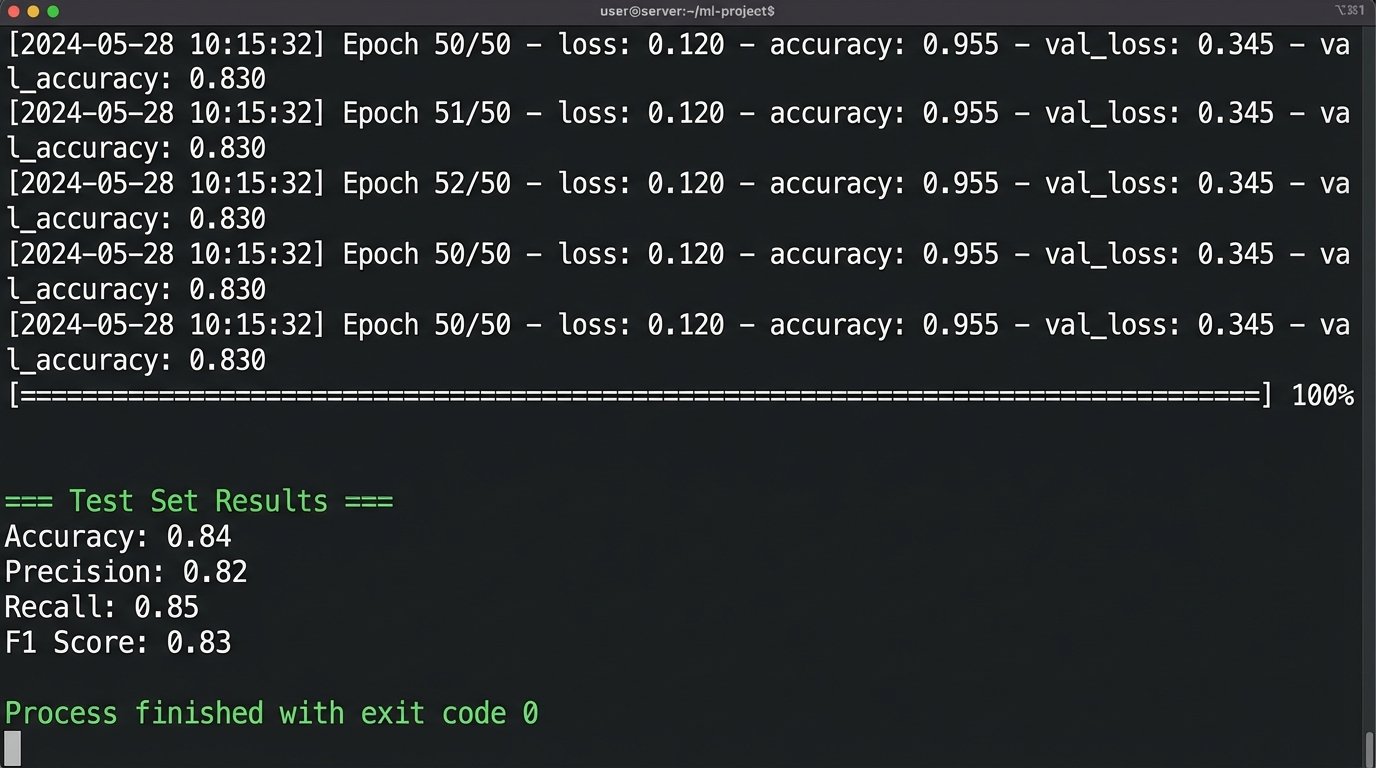
The training data consisted of roughly 50,000 historical leads, with the target variable being a binary flag: `is_closed_won`. We performed a standard 70/15/15 split for training, validation, and testing. The first training run was a disaster. The model showed 99% accuracy, a clear sign of data leakage. We discovered that some of the marketing data we were using was only populated *after* a deal was closed, contaminating the training set. After purging these future-telling features, the model’s accuracy dropped to a more realistic 84% on the test set.
This is the part that isn’t glamorous. It involves tedious data forensics and rerunning training jobs over and over. You have to hammer the data into a shape that accurately represents the state of knowledge at the moment of prediction.
Deployment Architecture: From Model to Live Scoring
A trained model file sitting on a disk is useless. It needs to be integrated into the live operational flow. We built a serverless architecture on AWS to handle real-time scoring. The workflow was direct and built for speed.
The process works like this:
- A new lead is created in Salesforce.
- A Salesforce outbound message (a webhook, essentially) fires, sending a payload with the new lead’s basic info to an Amazon API Gateway endpoint.
- The API Gateway triggers an AWS Lambda function.
- This Python-based Lambda function orchestrates the scoring. It takes the lead data, performs the same feature engineering transformations used in training, and then calls a SageMaker model endpoint with the feature vector.
- SageMaker returns a prediction score between 0 and 1.
- The Lambda function then makes a REST API call back to Salesforce, updating a custom field on the lead record called `Lead_Conversion_Probability__c`.
The entire round trip takes less than two seconds. We created a separate, low-priority field for a human-readable explanation of the score, generated using SHAP (SHapley Additive exPlanations) values. This showed the top three positive and negative contributors to the score, such as “+0.15 for visiting pricing page 3 times” or “-0.20 for using a free email provider.”
Example Request Payload
The JSON payload sent from the Lambda to the SageMaker endpoint had to be precise. It’s a simple vector of the engineered features, stripped of any identifying information.
{
"data": [
[
0.85, // behavioral_velocity_score
3, // content_affinity_cluster
1, // is_corp_email
0, // title_seniority_index (0 for unknown)
450000,// loan_amount_requested
710, // self_reported_credit_score
0.12 // time_on_site_normalized
]
]
}
This lean payload keeps the inference request fast and cheap. The logic lives in the Lambda, not the endpoint.
Results and Operational Impact
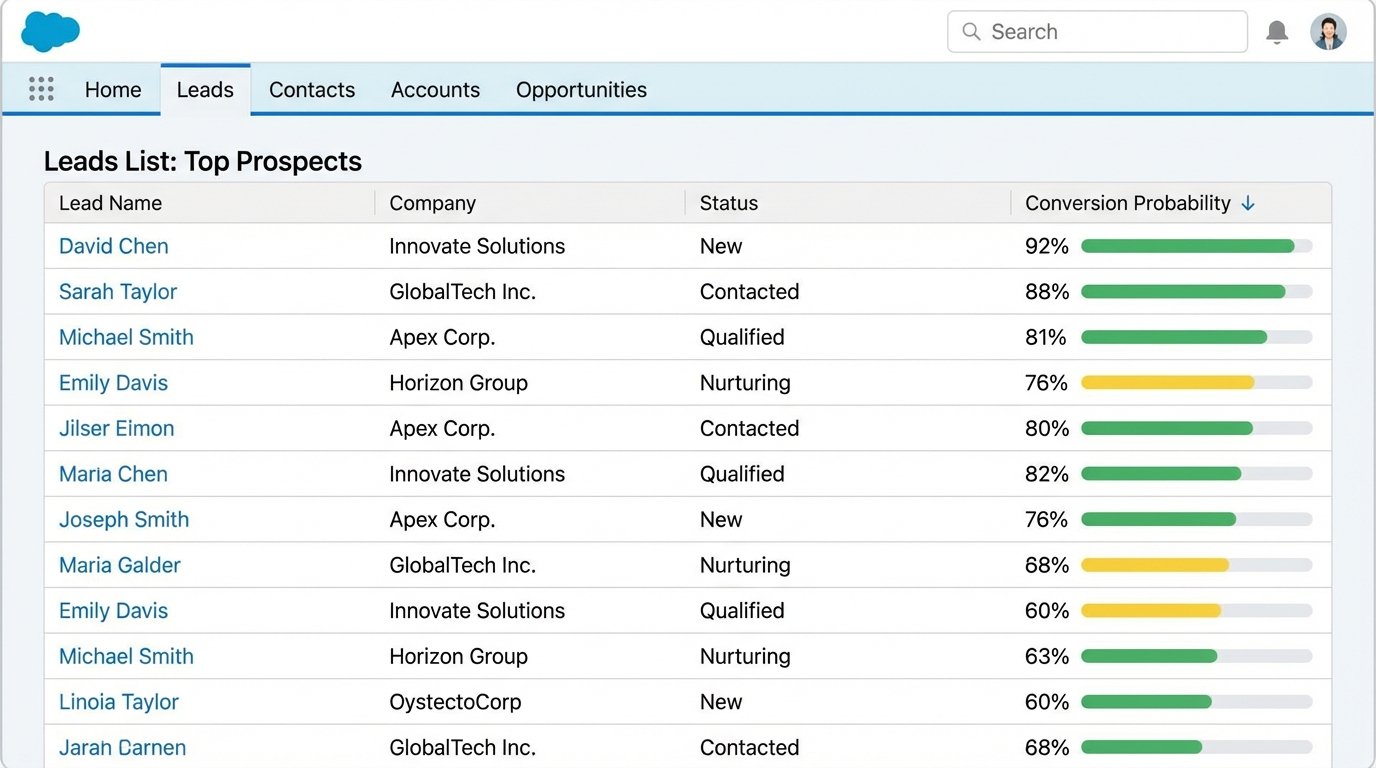
The sales team was skeptical at first. They were used to their old system and didn’t trust a number generated by a machine. The SHAP-based explanations were critical for adoption. When a rep could see *why* a lead was scored a 92, they started to trust the system. We reconfigured their Salesforce list views to sort leads by our probability score, forcing the highest-potential leads to the top.
The business impact was measured over the first six months of operation.
- Lead-to-Opportunity Conversion Rate: Increased from 8% to 21%. Reps were engaging with leads who were genuinely ready for a conversation.
- Sales Cycle Length: Decreased by an average of 9 days. Better qualified leads moved through the pipeline faster.
- Wasted SDR Hours: We estimated a reduction of over 400 hours per quarter previously spent on chasing junk leads.
The model is not static. We have a retraining pipeline that runs every quarter, using the latest set of converted and lost leads to keep the model from drifting. This ensures it adapts to changing market conditions or new marketing campaigns. The system now functions like a high-speed sorting machine on a conveyor belt, kicking junk leads into a discard bin before they ever consume a minute of human time.
This project was not about “AI” as a buzzword. It was about applying a specific machine learning technique to solve a clear business problem: resource misallocation. The upfront investment in data infrastructure and model development paid for itself within two quarters, primarily by plugging the leak of wasted sales effort and focusing human attention where it generated the most value.