
The first sign of catastrophic failure was the First Response Time metric. It crept from 15 minutes to 45 minutes, then to three hours. Our brokerage client’s support team was drowning in a sea of Tier 1 tickets. The root cause was growth, but the symptoms were agent burnout and a collapsing Customer Satisfaction Score. The queue was clogged with the same three questions, repeated endlessly: “How do I reset my password?”, “What’s my account balance?”, and “Did my trade for AAPL execute?”.
Hiring more agents was the obvious, and obviously wrong, answer. It’s a linear solution to an exponential problem. You can’t hire your way out of a structural deficiency. The real problem was agent occupancy. Our senior support staff, people who understood complex trade settlement issues, were spending 60% of their day handling queries a script could resolve. This was an expensive, inefficient use of specialized human capital.
Diagnostic: Pinpointing the Failure Modes
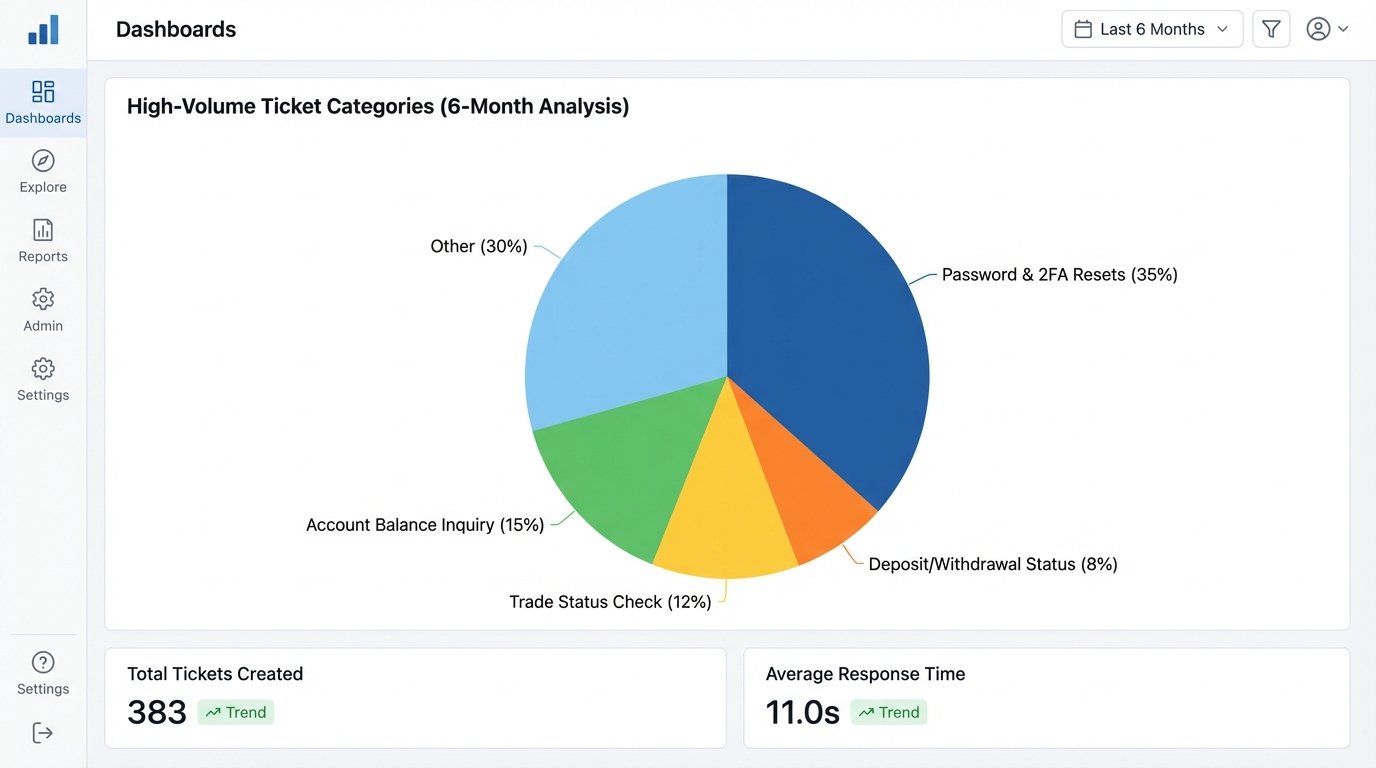
Before architecting a solution, we had to gut the existing workflow. We ingested six months of support ticket data from their Zendesk instance. We stripped out PII and ran a simple clustering analysis based on ticket tags and keywords. The data was not surprising, but it was damning. Approximately 70% of all incoming support requests fell into five categories, all of which were resolvable via an internal API call or a link to a static knowledge base article.
The High-Volume Ticket Categories:
- Password & 2FA Resets: The single largest contributor. High volume, low complexity, pure procedural work.
- Account Balance Inquiry: A direct data lookup. The user wants a number, nothing more.
- Trade Status Check: Another data lookup, slightly more complex due to various order statuses (pending, executed, failed).
- Deposit/Withdrawal Status: A query against their payment processor’s API.
- Document Requests: “Send me my last account statement.”
The existing process required a human to authenticate the user, toggle to a different system, perform the lookup, and then paste the result back into the chat window. Each ticket consumed, on average, four minutes of an agent’s time. The math was simple. At 10,000 tickets a month in these categories alone, we were burning over 650 hours of agent time on tasks that required zero critical thinking.
The Architecture of Containment
We didn’t need a “conversational AI.” We needed a logical gatekeeper. The goal was not to replace human agents but to shield them from the barrage of low-value, repetitive work. The solution required two core components: an intent recognition engine and a secure orchestration layer to interact with the brokerage’s backend systems.
We evaluated several commercial platforms. Most were polished wallet-drainers, charging per API call or per “active user,” a metric designed to punish scale. Their walled gardens also made deep integration with proprietary backend services a nightmare. We opted for a more direct approach: pairing a large language model’s NLU capabilities with a custom-built service acting as a bridge. This gave us full control over the logic and, more important, the security model.
Component Breakdown:
- Intent Classifier: We used OpenAI’s GPT-4 model, but not for generating conversational fluff. We used it for one task only: to classify the user’s raw input into one of a dozen predefined intents with brutal accuracy. We fed it the query and forced it to respond with a structured JSON object. No conversation, just data. This is key. Using an LLM as a tool, not a personality, avoids hallucinations and unpredictable behavior.
- Vector Database for Knowledge Base: For “how-to” questions, a simple keyword search is useless. We chunked their entire knowledge base of 200+ articles, generated embeddings for each chunk using an open-source model, and loaded them into a Pinecone vector index. When a query comes in, we first convert the query to an embedding and perform a semantic search against the index to find the most relevant context. This context is then injected into the prompt for a final, accurate answer.
- Secure API Orchestrator: This was the hardest part. The brokerage’s internal APIs were not designed for this kind of direct, automated access. We built a lightweight service in Go that sat behind their firewall. It exposed a single, tightly controlled endpoint. This service received the structured intent from the classifier and was responsible for authenticating the user (via a temporary, scoped-down JWT passed from the frontend chat widget), constructing the correct internal API call, and returning only the necessary data.
Trying to make these new components talk to the old backend felt like plumbing a modern datacenter’s cooling system with rusty lead pipes. The legacy APIs were not RESTful, returned inconsistent data structures, and had pathetic error handling. We had to build a thick layer of data validation and transformation just to make the responses usable.
The orchestrator became the central nervous system. It would receive a payload, logic-check the intent, and then route the request. If the intent was `trade_status_inquiry`, it knew to hit the trade management service. If the intent was `password_reset`, it triggered a call to their identity provider. This prevented the LLM from ever directly touching a sensitive system.
Intent Classification and API Mapping
The core logic hinged on mapping a classified intent to a concrete action. The LLM’s job was to translate messy human language into a machine-readable instruction set. A user might type “did my trade go through for nvidia,” and the system needed to turn that into a structured object that the orchestrator could execute.
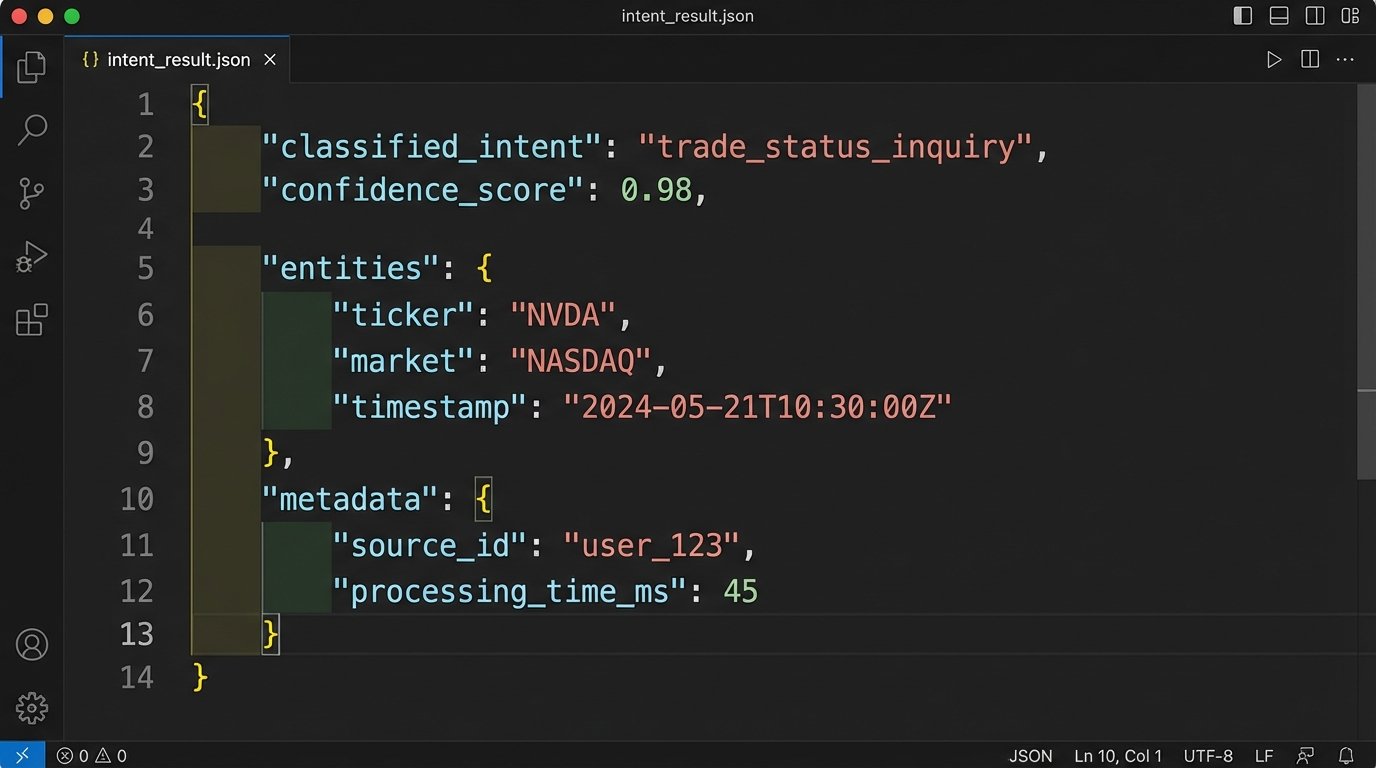
Here is a simplified example of the JSON object our classifier would generate and send to the backend orchestrator:
{
"session_id": "f4a5c6d7-e8b9-12d3-a456-426614174000",
"user_query": "what's the status of my order to buy 100 shares of NVDA",
"classified_intent": "trade_status_inquiry",
"confidence_score": 0.98,
"entities": {
"ticker": "NVDA",
"quantity": "100",
"action": "buy"
},
"required_api_call": {
"endpoint": "/v1/orders/status",
"method": "POST",
"payload_template": {
"user_id": "{user_id}",
"ticker_symbol": "{entities.ticker}"
}
}
}
This structure gave the orchestrator everything it needed. It validated the intent, checked the confidence score, and used the `required_api_call` block to build and execute the request against the internal system after injecting the authenticated user’s ID. If the confidence score dropped below a certain threshold (we set it at 0.85), the system would immediately stop and escalate to a human agent with the full context. No guessing.
Rollout and Results: The Numbers Don’t Lie
We deployed the system in stages. First, we ran it in “shadow mode” for two weeks. The bot would classify the intent and log the action it would have taken, but a human agent would still handle the ticket. This allowed us to fine-tune the intent classification and identify edge cases without any customer impact. We found dozens of weirdly phrased questions that we used to build a more resilient classification prompt.
Next, we enabled it for internal employees, then for a small beta group of 5% of users. After a month of monitoring logs and performance, we opened the floodgates. The impact was immediate and measurable.
Key Performance Indicators: Before and After
- Ticket Deflection Rate: Within the first month, the bot was successfully resolving 42% of all incoming support queries without human intervention. This number stabilized at around 38% long-term.
- Average First Response Time (FRT): FRT for all tickets dropped from over 3 hours to just 12 minutes. For queries the bot could handle, the response was instantaneous.
- Agent Occupancy on Tier 1 Issues: We reduced the time senior agents spent on automatable tickets from 60% of their day to less than 10%. This 10% was mostly escalations and complex variations the bot couldn’t handle.
- Customer Satisfaction (CSAT): This was the surprising metric. We expected a neutral or slightly negative reaction to a bot. Instead, CSAT scores increased by 8%. Users preferred an instant, accurate answer from a bot for simple questions over waiting hours for a human.
The system was not perfect. It created new work. We now needed someone to monitor the bot’s performance, update the knowledge base to keep the vector search relevant, and manage the prompt library for the classifier. The bot also struggled with compound questions, where a user asks about their account balance and a trade status in the same sentence. Our initial logic would only classify the first intent, so we had to build a secondary process to parse for multiple intents and handle them sequentially.

The project didn’t reduce headcount. It stopped the desperate need to hire more people just to keep up. The human agents were freed to focus on high-value, complex problems that actually required their expertise: investigating failed trades, handling margin calls, and dealing with legitimately angry customers. They became problem solvers again, not just glorified data lookup machines.
The biggest lesson was that “AI” is not a magic wand. It’s a precision tool. We achieved success not by building a chatbot that could talk about the weather, but by designing a system that could surgically extract intent from user text and translate it into a specific, authorized system action. It’s less about artificial intelligence and more about structured automation.