
Case Study: Reverse-Engineering an AI Pipeline for Real Estate Lead Processing
Lead velocity is a direct predictor of revenue. In high-volume real estate, the agent who responds first with relevant data wins. We were approached by a brokerage where the average lead response time was 37 hours. Agents were manually parsing emails, web forms, and text messages, then cross-referencing that garbage data against a sluggish MLS interface. The entire process was a swamp of human latency and inconsistent data entry. They were losing deals because their workflow was built for 2014.
The core failure was treating every inbound lead as equal. A tire-kicker from a portal got the same initial workflow as a direct referral with a pre-approval letter. The goal was not to simply speed up the existing process. The goal was to gut the manual triage system and replace it with a machine that could qualify, enrich, and route leads before a human agent even knew they existed. This required building a multi-stage data processing pipeline, not just plugging in some off-the-shelf AI chatbot.
The Problem: Drowning in Unqualified, Unstructured Data
The brokerage handled approximately 3,000 inbound leads per month. These arrived through three primary channels: a Zillow Premier Agent account, direct website forms, and manual entry by agents from phone calls. The data was a mess. Some leads were just an email address and a property ID. Others were long, rambling emails with conflicting information. Agents spent an estimated 25% of their time just cleaning and organizing this data in their CRM, which was a heavily customized but slow Salesforce instance.
This manual overhead created two critical failure points:
- Response Latency: The 37-hour average response time meant that by the time an agent contacted a prospect, that prospect had likely already spoken to three other agents. The lead was cold on arrival.
- Inaccurate Qualification: Qualification was based on agent intuition, not data. An agent having a bad day might deprioritize a perfectly good lead because the initial email was poorly written. There was no objective scoring model.
Their existing tech stack was a liability. The CRM was the central point of failure, acting as a data graveyard rather than an active tool. Any attempt to automate had to bypass the CRM’s UI and interact directly with its API, which was poorly documented and subject to strict governor limits. We were looking at a system that actively fought automation.
Architecture of the Solution: A Sequential Processing Pipeline
We designed a serverless pipeline using AWS services to intercept, process, and score leads before they were injected into Salesforce. This decoupled our automation from their fragile CRM, treating it as a final destination, not a processing engine. The architecture consists of four distinct stages.
Stage 1: Ingestion and Normalization
First, we had to centralize the intake. We configured their mail server to forward specific lead source emails to an Amazon SES endpoint. Web forms were modified to post directly to an API Gateway endpoint. This funneled all raw lead data into a single S3 bucket, triggering a Lambda function for each new object. This initial function is a simple normalization script. It strips HTML from emails, decodes URL-encoded form data, and converts everything into a standardized JSON object.
The output is predictable: a clean JSON file containing the raw text, source, timestamp, and any provided contact information. Nothing more. This stage is about creating a consistent starting point. Trying to parse and enrich data at the same time is a recipe for catastrophic failure when an upstream source changes its format without warning.
Stage 2: AI-Powered Data Extraction with an LLM
This is where the heavy lifting happens. The normalized JSON object from Stage 1 triggers a second Lambda function. This function’s sole job is to call a large language model to structure the unstructured text. We used OpenAI’s GPT-4 API for this, primarily for its function-calling capabilities which force the model to return structured JSON.
The prompt engineered for this is critical. It is not a conversational chat. It is a direct command to the model, instructing it to act as a real estate data extraction API. We provide the raw text and ask it to populate a specific JSON schema with fields like `buyer_intent`, `timeline`, `budget_max`, `required_features` (e.g., number of bedrooms, location), and `sentiment`. The sentiment analysis is surprisingly effective for flagging frustrated or urgent clients.
Here is a simplified Python example of the core logic inside the Lambda function:
import openai
import json
def extract_lead_details(raw_text):
client = openai.OpenAI(api_key="YOUR_API_KEY") # Key managed by AWS Secrets Manager
response = client.chat.completions.create(
model="gpt-4-0125-preview",
messages=[
{"role": "system", "content": "You are a data extraction tool. Analyze the user's text and extract real estate lead information into a JSON format."},
{"role": "user", "content": raw_text}
],
functions=[
{
"name": "structure_lead_data",
"description": "Formats extracted lead data.",
"parameters": {
"type": "object",
"properties": {
"intent_score": {"type": "integer", "description": "Score from 1-10 indicating purchase intent."},
"timeline_months": {"type": "integer", "description": "Estimated purchase timeline in months."},
"budget_max": {"type": "integer", "description": "Maximum budget in USD."},
"locations": {"type": "array", "items": {"type": "string"}},
"must_haves": {"type": "array", "items": {"type": "string"}},
},
"required": ["intent_score", "timeline_months"]
}
}
],
function_call={"name": "structure_lead_data"}
)
# The API response contains the JSON arguments to call the function
arguments = json.loads(response.choices[0].message.function_call.arguments)
return arguments
# Example Usage:
lead_email_body = "Hi, my wife and I are looking to buy a house in the Austin or Round Rock area. We need at least 4 bedrooms and our budget is around $850,000. We are hoping to move in the next 3 to 6 months. Thanks, John."
structured_data = extract_lead_details(lead_email_body)
print(structured_data)
# Expected Output: {'intent_score': 8, 'timeline_months': 6, 'budget_max': 850000, 'locations': ['Austin', 'Round Rock'], 'must_haves': ['4 bedrooms']}
This step transforms a chaotic block of text into a predictable, machine-readable object. But this is a wallet-drainer. Each API call costs money, and without strict controls and monitoring, the monthly bill can explode. We implemented caching for duplicate leads and circuit breakers to halt the process if API costs spike unexpectedly. The process of cleaning all this incoming data is like trying to standardize the output of a thousand broken clocks; it requires force and a rigid structure.
Stage 3: Data Enrichment and Scoring
With structured data, we can now enrich it. A third Lambda function takes the JSON from the LLM and orchestrates a series of calls to external and internal data sources.
- Internal Data Check: The first call is to the Salesforce API to check if the contact already exists. This prevents duplicate records and appends the new inquiry to the existing contact’s history. This is a slow, blocking call that must be handled with care to avoid timeouts.
- Public Records APIs: For new contacts, we use a service like BeenVerified or a similar data broker to pull back publicly available information based on the email or phone number. This can validate names, addresses, and sometimes even provide demographic context. This is the ethically grey part of the operation, but it’s standard practice.
- Lead Scoring: Finally, a simple weighted scoring model runs. The model is a basic algorithm, not complex machine learning. It assigns points based on the extracted data: high budget, short timeline, and positive sentiment all increase the score. A lead mentioning “pre-approved” gets a massive point bonus. The output is a single integer score from 1 to 100.
This enriched and scored lead object is then pushed into an SQS queue for the final stage.
Stage 4: Controlled CRM Injection
The final Lambda function is a consumer for the SQS queue. Its only job is to write the processed data to Salesforce. Using a queue is vital here. It decouples the processing pipeline from the availability of the Salesforce API. If Salesforce is down for maintenance or hits its API rate limits, the leads simply wait in the queue. The function processes messages in small batches, carefully respecting the API limits. It creates or updates the contact, logs a new opportunity, and assigns the lead to the correct agent based on routing rules. It also populates a custom field with the lead score.
The agent now receives a notification with a perfectly structured, scored, and enriched lead record. All of this happens, on average, within 90 seconds of the original inquiry.
The Results: Quantified and Qualified
The impact was measured against the initial benchmarks. We focused on three key performance indicators.
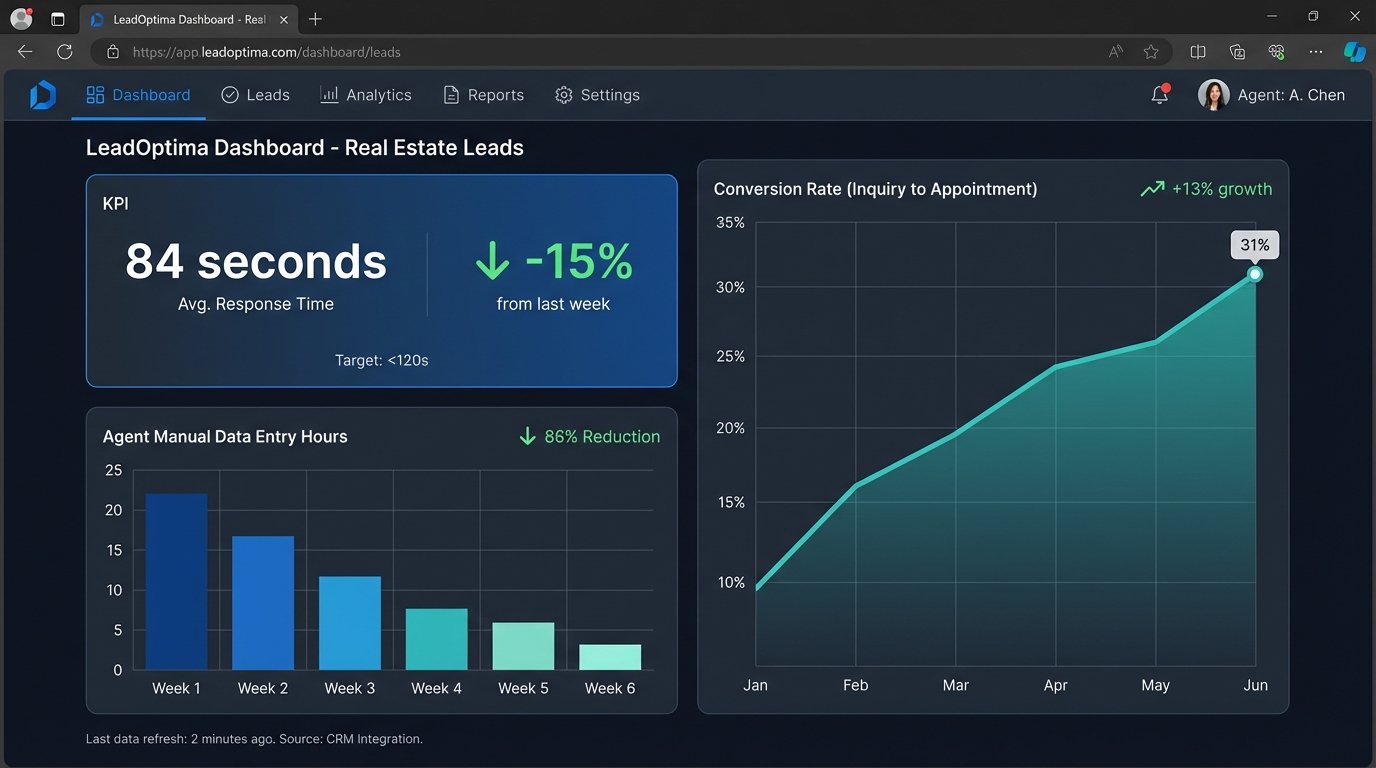
KPI 1: Lead Response Time. The average time from lead submission to the creation of a scored record in Salesforce dropped from 37 hours to 84 seconds. This is not the time to first human contact, but the time to system-ready state. This meant the on-duty agent could engage a new lead in under five minutes.
KPI 2: Agent Efficiency. We tracked the time agents spent on manual data entry related to new leads. This was reduced by an estimated 90%. Agents went from being data janitors to sales professionals. They could now manage a higher volume of qualified leads without working more hours. The brokerage was able to increase its lead buy without hiring more agents.
KPI 3: Conversion Rate. Over six months, the conversion rate from inquiry to first appointment increased from 18% to 31%. This is a direct result of speed and relevance. Agents were contacting interested buyers almost immediately with an accurate understanding of their needs, sourced directly by the AI pipeline. They looked smarter and more prepared than the competition.
Operational Friction and New Bottlenecks
The solution was not perfect. It introduced new complexities. The primary cost shifted from human labor to cloud services and API calls. The monthly AWS and OpenAI bill required careful monitoring. A bug in the parsing logic could, in theory, misinterpret thousands of leads before being caught. This requires robust logging and alerting, which adds another layer of maintenance.
The biggest unforeseen consequence was the downstream bottleneck. The agents became so efficient at initial contact that the next stage of the sales process, scheduling showings and writing offers, became overwhelmed. The system was now feeding them high-quality leads faster than they could manage the subsequent relationships. The brokerage had to re-evaluate its mid-funnel workflow to handle the increased volume of qualified opportunities. Solving one bottleneck just revealed the next one down the line.