The Sync Catastrophe: Manual Entry and Data Drift
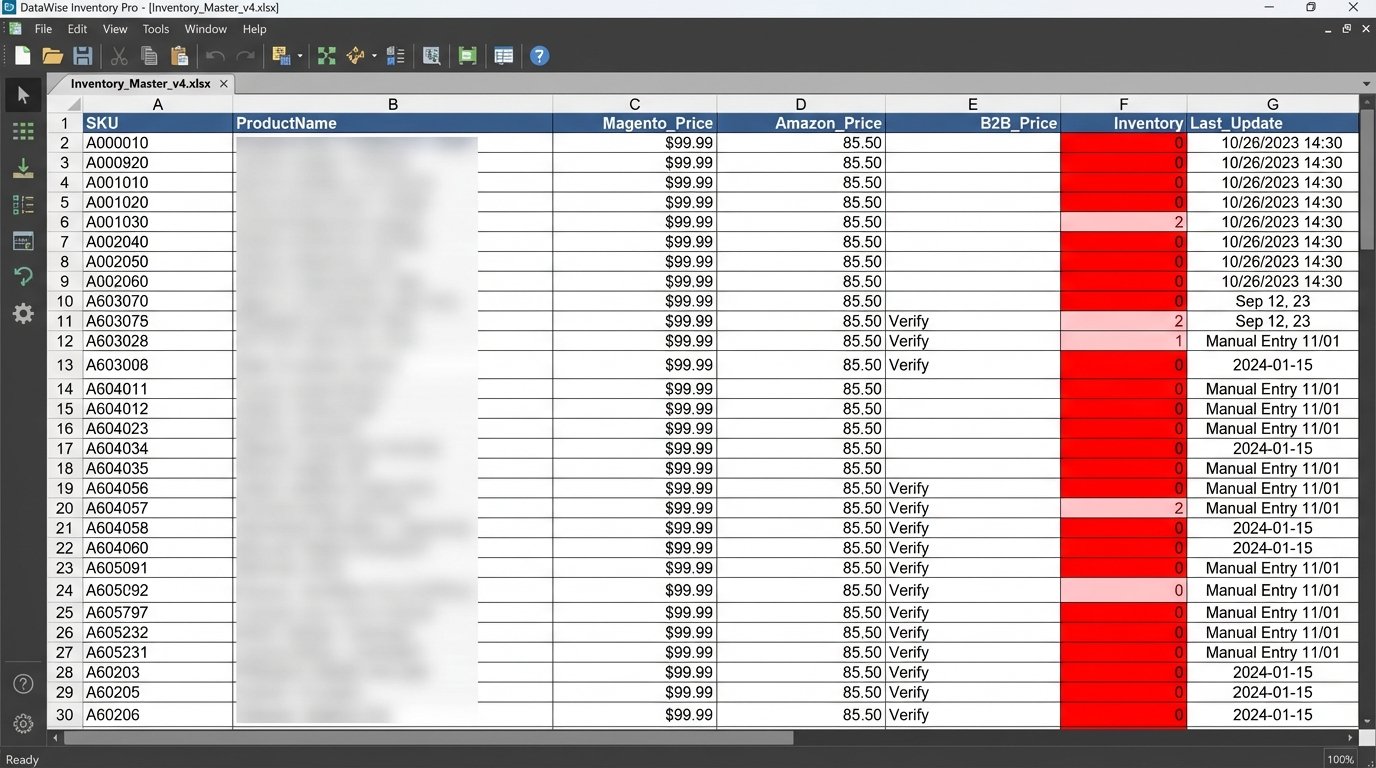
The initial state was chaos. A client was selling industrial equipment parts across a primary Magento 2 site, an Amazon Seller Central account, and a niche B2B marketplace. Their “synchronization strategy” consisted of two full-time employees manually copying product data, pricing, and inventory levels from a master spreadsheet into three different admin panels. This wasn’t just inefficient. It was a self-inflicted wound that bled revenue daily.
Data drift was rampant. A price update on the spreadsheet might take 72 hours to reflect on all platforms, if it was not forgotten entirely. Inventory counts were a work of fiction. The company regularly sold items that were out of stock, leading to an order cancellation rate hovering around 15%. Each cancellation was not just a lost sale. It was a negative review waiting to happen and a direct hit to their marketplace seller rating.
The time-to-market for a new product was five business days. Five days of a part sitting in the warehouse, invisible to customers, because the process of creating three unique listing formats with different required attributes was a tedious bottleneck. The operational cost of this manual labor, combined with the lost revenue from cancellations and delays, was unacceptable. The spreadsheet had to be decommissioned.
Architecting a Bridge, Not a Shortcut
Management’s first instinct was to find an off-the-shelf plugin. We evaluated three popular options. All of them failed. They were built for simple retail products, not industrial parts with complex, multi-level custom attributes and conditional validation rules. These plugins were wallet-drainers that offered a rigid, one-size-fits-all data model that could not handle the client’s specific schema.
The only viable path was a custom middleware service. We opted for a lean Python application running on an AWS EC2 instance. This service would act as the central nervous system for all product data. The core principle was establishing a single source of truth. Magento 2 was designated as the master record. No product data would be modified directly on any other platform. All changes, from stock adjustments to new product creation, had to originate in Magento.
Polling the Magento API every few minutes for changes is clumsy and inefficient. It generates useless network traffic and introduces delays. We bypassed this by using Magento’s native webhook system. We configured webhooks to fire on product save events (`catalog_product_save_after`). When an admin updated a product, Magento would instantly send a POST request with the product payload to a specific endpoint on our middleware service. This gave us real-time data flow.
The Data Transformation Engine
Getting the data was the easy part. The real work was in the transformation logic. The three target platforms had wildly different schemas and validation requirements. Amazon demanded a specific `ProductType` with its own set of attributes. The B2B portal required dimensions in metric units only. Magento, being the most flexible, stored this data in a generic key-value EAV (Entity-Attribute-Value) model. A direct one-to-one mapping was impossible.
We built a transformation layer that used simple JSON configuration files to define the mapping rules for each platform. This decoupled the mapping logic from the application code, allowing us to add or modify rules without a full deployment. The service would ingest the raw Magento product data, look up the target platform’s mapping file, and begin restructuring the payload. This was less of a simple data transfer and more of an architectural translation, forcing one system’s vocabulary into another’s grammar.
This process also handled data enrichment and cleaning. For example, the B2B portal had a strict character limit on product titles. The transformation engine would automatically truncate the Magento title and append “…” if it exceeded the limit. It stripped HTML tags from descriptions for Amazon and converted imperial weight measurements from Magento into kilograms for the B2B platform. The goal was to automate every single manual edit the staff had been performing.
# Simplified Python example of a mapping configuration
# This is NOT production code, just a conceptual illustration.
AMAZON_MAPPING = {
"target_field": "sku",
"source_field": "sku",
"transform_func": None
},
{
"target_field": "standard_price",
"source_field": "price",
"transform_func": lambda p: round(float(p), 2)
},
{
"target_field": "quantity",
"source_field": "quantity_and_stock_status.qty",
"transform_func": lambda q: int(q) if int(q) > 0 else 0
},
{
"target_field": "product-id-type",
"source_field": "upc_attribute",
"transform_func": lambda upc: "UPC" if upc else None
}
def transform_product(source_product, mapping_config):
"""
Applies mapping rules to a source product dictionary.
A real implementation would handle nested keys and more complex logic.
"""
transformed_data = {}
for rule in mapping_config:
# Simplified key access for illustration
source_value = source_product.get(rule["source_field"])
if source_value is not None:
if rule["transform_func"]:
transformed_data[rule["target_field"]] = rule["transform_func"](source_value)
else:
transformed_data[rule["target_field"]] = source_value
return transformed_data
This config-driven approach was critical. When the client decided to expand to a fourth marketplace six months later, we didn’t have to rewrite the core application. We simply wrote a new JSON mapping file and a new API client class. The development time was days, not weeks.
Surviving Hostile APIs
Every external API is a potential point of failure. API rate limits are not a guideline. They are a concrete wall you will slam into during a bulk update. The B2B portal’s API was particularly sluggish, allowing only 60 calls per minute. A mass inventory update from Magento could generate hundreds of webhooks in a few seconds, which would have immediately triggered the rate limiter and caused cascading failures.
To solve this, we injected a Redis queue between the webhook ingestion endpoint and the API call workers. When a webhook arrived, the application would simply validate the payload and push a job onto the queue. Separate worker processes would pull jobs from this queue at a controlled pace, respecting the rate limits of each target API. If an API returned a `429 Too Many Requests` or a `503 Service Unavailable` error, the job was not discarded. It was re-queued with an exponential backoff delay. This made the entire system resilient to temporary API outages.
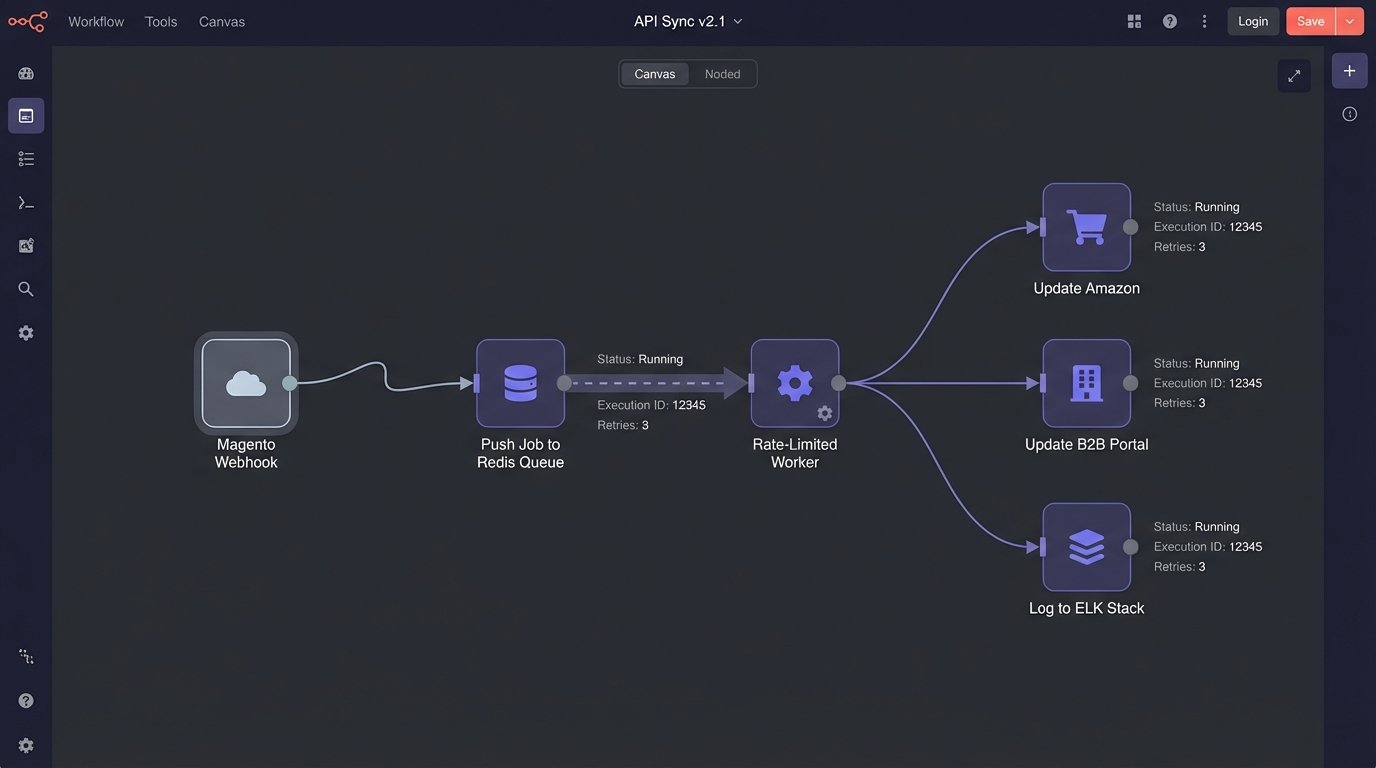
Aggressive logging was non-negotiable. Every inbound webhook, every transformation step, and every outbound API call with its full request and response was logged to an ELK stack (Elasticsearch, Logstash, Kibana). This was not for vanity. It was for survival. Three weeks after launch, updates to Amazon started failing intermittently. The API error was a generic “Invalid Data.” The logs showed us that Amazon had, without documentation, started requiring a new attribute for that specific product category. Without detailed logs, we would have been debugging blind.
The Measured Outcome: From Chaos to Control
The results were not subjective. We measured the impact against the initial baseline metrics. The improvements were immediate and significant.
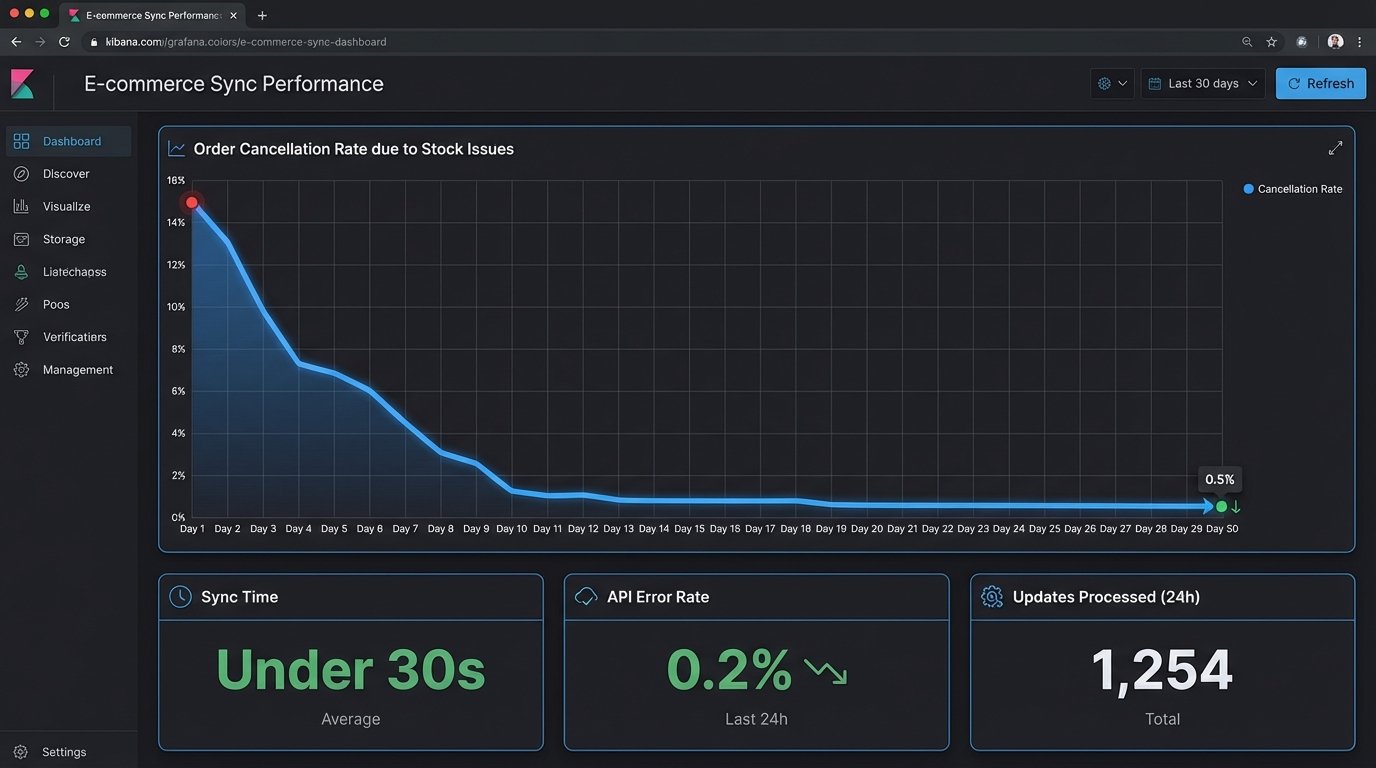
- Order Cancellation Rate: This was the primary pain point. Within 30 days of deployment, the cancellation rate due to stock issues dropped from 15% to below 1%. This had a direct impact on revenue and drastically improved the client’s seller ratings on the marketplaces.
- Time to Sync: The time for a price or stock update to propagate across all channels went from an average of 48 hours to under 30 seconds. New products created in Magento were live on all platforms within two minutes.
- Operational Overhead: We completely eliminated the 60+ hours per week of manual data entry. The two employees previously tasked with this mind-numbing work were retrained to focus on higher-value activities like marketing and customer support. The monthly cost of the EC2 instance and Redis cache was a fraction of one employee’s salary.
The return on investment was calculated based on recovered revenue from eliminated cancellations and the direct cost savings from reallocated labor. The project paid for itself in under four months. The system has since processed over 50,000 product updates without significant manual intervention.
What We Learned: The Unwritten Rules
A project like this teaches you a few hard lessons that are never in the API documentation. First, logic-check every claim an API document makes. Use a tool like Postman to hit the endpoints and inspect the real responses before you write a single function. We found discrepancies between the documented data types and the actual JSON output in two of the three APIs.
Second, build for idempotency from day one. Your system must be able to handle receiving the same update message twice without creating duplicate data or throwing an error. Network issues can cause webhooks to be resent. Your update logic should be based on `update_or_create`, not just `create`.
The “single source of truth” policy must be enforced with technical controls, not just memos. We had to use the marketplace APIs to disable the ability to edit product data directly in their user interfaces. Early on, a well-meaning employee would “quickly fix” a typo on the B2B portal, only for it to be overwritten by the next automated sync from Magento. You have to force the correct workflow.
This system reduced daily toil, but it did not eliminate the need for oversight. We built a monitoring dashboard to track queue depth and API error rates. APIs evolve, and marketplaces introduce new required fields with little warning. An automated sync system is an operational responsibility, not a fire-and-forget solution.