The Sequential Bottleneck is a Self-Inflicted Wound
Every slow transaction closing shares a common point of failure: a rigid, sequential task list. A processor completes step A, then manually triggers step B by sending an email or updating a status field. The person responsible for step B is at lunch. The entire transaction now sits idle, blocked by a single dependency in a chain that never needed to be a chain in the first place. This isn’t a process problem. It’s an architectural failure.
We treat a complex, multi-party operation like a single-threaded application from 1995. The reality of a closing is a graph of dependencies, not a straight line. Certain tasks can run in parallel, while others are gated by specific data points, not the completion of a loosely related predecessor. Forcing a linear path on a parallel problem is the primary source of process latency. The fix is not better project management. It is to gut the underlying architectural assumption.
Dissecting the Dependency Graph Fallacy
Most platforms visualize a transaction as a checklist. Task 1: Order Title. Task 2: Order Appraisal. Task 3: Collect Borrower Docs. This model is fundamentally wrong. Ordering the title and the appraisal are independent operations. They can be fired off simultaneously the moment a loan file is opened. The only true dependency is the existence of the file itself. Waiting for one to complete before starting the other is manufactured delay.
The real dependency map is a Directed Acyclic Graph (DAG). An underwriting review can’t begin until both the appraisal value and the borrower’s income verification are present. It doesn’t care if the title search is complete. The system’s job is to understand these specific data dependencies, not enforce an arbitrary, human-readable sequence. Mapping this out reveals massive opportunities for parallel execution that a simple checklist obscures.
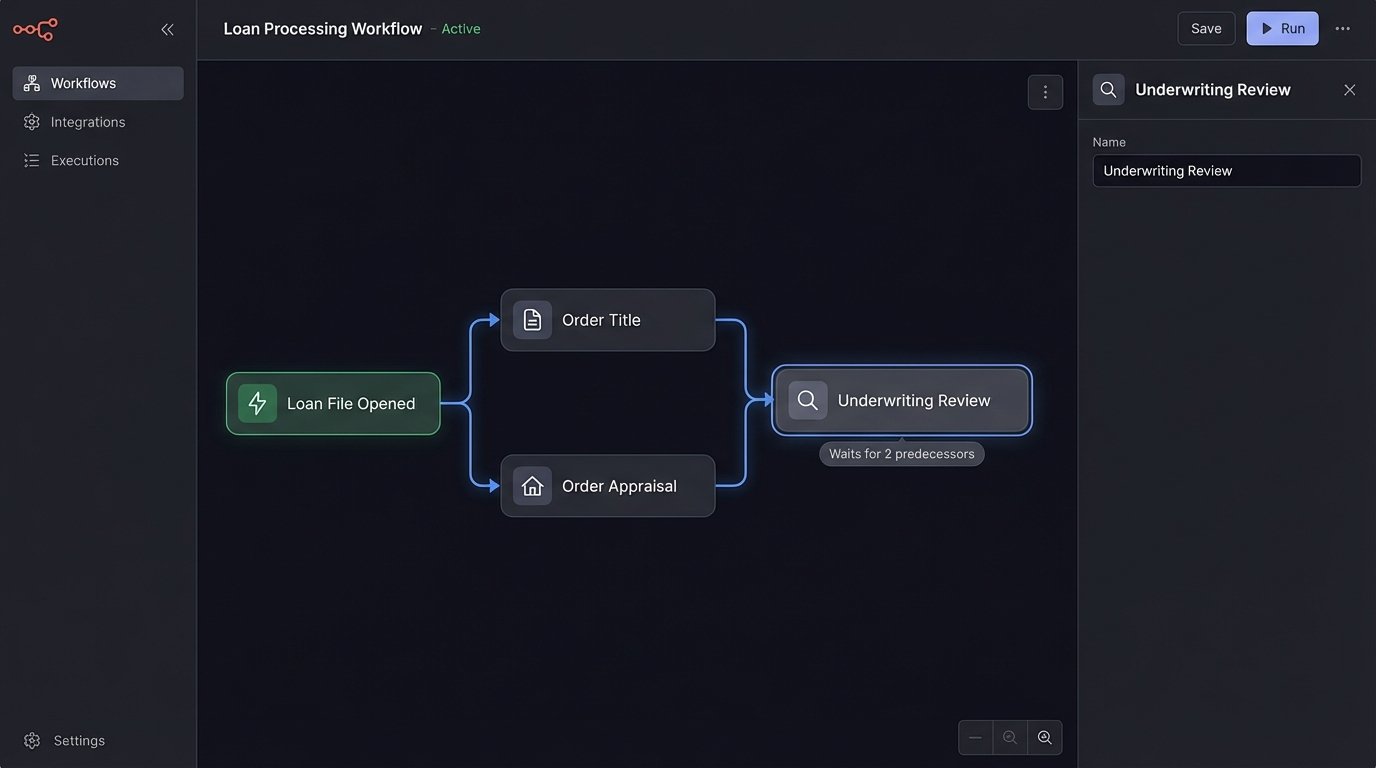
Your current workflow is likely forcing a developer to hard-code a `if task_A_complete then start_task_B` logic. This is brittle. When the business process changes, you have to redeploy code. A proper architecture externalizes this logic, treating the workflow itself as configuration, not compiled code. This is the difference between a system that adapts and one that breaks.
From Checklist to State Machine
The architectural solution is to stop thinking about task completion and start managing state transitions. A transaction is not a list of things to do. It is an entity that moves through various states: `New`, `Processing`, `DocsRequested`, `Underwriting`, `ClearedToClose`, `Funded`. An external event, like a document being uploaded or an API call completing, triggers a potential state change. The system’s only job is to validate and execute that transition.
This model decouples the task performers from the workflow logic. The appraisal service doesn’t need to know that its output triggers underwriting. It simply needs to publish an `APPRAISAL_COMPLETE` event containing the relevant data. An orchestrator, a central brain for the workflow, consumes this event and determines the correct next action based on the transaction’s current state and the dependency graph. This is event-driven architecture, not a glorified to-do list.
Trying to manage parallel operations with a linear checklist is like shoving a firehose of data through a needle. You create an artificial bottleneck where none needs to exist, throttling the entire system at the point of least concurrency.
The Architectural Fix: Webhooks over Polling
To feed events into a state machine, you need a mechanism to communicate task completion. The most common anti-pattern here is polling. A central system repeatedly queries external services, asking “Is the appraisal done yet?” every five minutes. This is a crude, brute-force method that burns API rate limits, wastes compute cycles, and still introduces latency between the actual completion and its discovery.
Polling is the strategy of the desperate. The correct approach is using webhooks.
When a task is completed, the service responsible makes a single, outbound HTTP POST request to a pre-defined endpoint on your orchestrator. This payload contains the event type, the transaction ID, and any relevant output data. The communication is instant and efficient. The orchestrator is not wasting resources checking for work. It is dormant until work is announced. This is the difference between a system that pulls information and one that has information pushed to it.
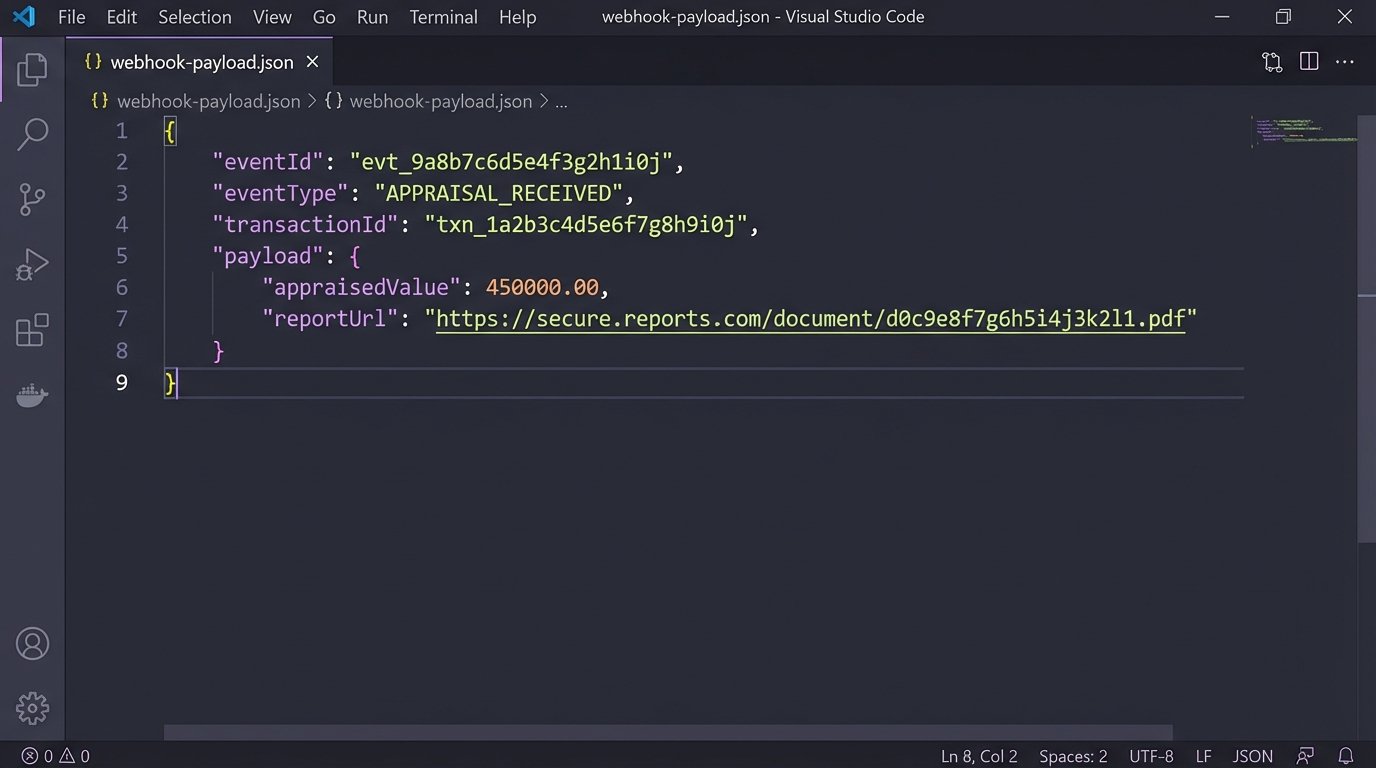
A Basic Webhook Payload Structure
The payload itself doesn’t need to be complex. It needs to be a contract. It should contain enough information for the orchestrator to act without having to make a callback to the originating service. Consistency here is critical. All your integrated services, internal or third-party, must adhere to this structure.
{
"eventId": "evt_1a2b3c4d5e6f",
"eventType": "APPRAISAL_RECEIVED",
"timestamp": "2023-10-27T10:00:00Z",
"sourceService": "AppraisalManagementPlatform",
"transactionId": "txn_z9y8x7w6",
"payload": {
"appraisedValue": 500000,
"inspectionDate": "2023-10-25",
"reportUrl": "https://example.com/reports/xyz.pdf"
}
}
This simple JSON object tells the orchestrator everything it needs. It knows which transaction to update, what just happened, and has the core data required to check for the next set of dependencies. No follow-up API call is needed to fetch the appraised value. It was injected directly into the event stream.
The Orchestrator: Building the Central Brain
The orchestrator is a service whose sole function is to listen for incoming webhooks, interpret the event, load the current state of the transaction, and execute the next logical steps based on the defined dependency graph. This is where the core business logic lives. It is not a monolithic application but a highly focused state transition engine.
Its logic cycle is simple:
- Ingest: Receive an event from the webhook endpoint.
- Validate: Check the event’s authenticity and structure.
- Fetch State: Load the current state of the specified `transactionId` from a database like Redis or DynamoDB.
- Apply Logic: Given the current state and the incoming event, consult the dependency graph to determine the next valid tasks.
- Dispatch: Trigger the new tasks via API calls, message queues, or other mechanisms.
- Update State: Persist the new state of the transaction.
You can build this yourself with a message queue and a serverless function, or use managed services. AWS Step Functions is a powerful tool for this, allowing you to define your DAG in JSON. Be warned, it is a wallet-drainer if your workflows are extremely chatty with many state transitions. For simpler graphs, a Lambda function triggered by an SQS queue is often more cost-effective, but requires you to manage the state persistence logic yourself.
Failure is Not an Option, It’s a Requirement
A perfect workflow diagram on a whiteboard means nothing at 3 AM when a third-party API is down. Your automation is only as good as its error handling. If a dispatched task fails, what happens? If the webhook call to your orchestrator times out, does the event get lost forever? Without robust failure handling, you have not built automation. You have built a fragile, high-speed time bomb.
Two patterns are non-negotiable. First, any outbound API call from your orchestrator must be wrapped in a retry mechanism with exponential backoff. A network blip shouldn’t kill a multi-day transaction. The system should wait and try again, automatically. Second, for events that consistently fail processing, you need a Dead-Letter Queue (DLQ). After a set number of failed retries, the problematic event is shunted to a separate queue for manual inspection. This isolates the failure, allowing other transactions to proceed unimpeded. The DLQ is the engineering equivalent of a triage station.
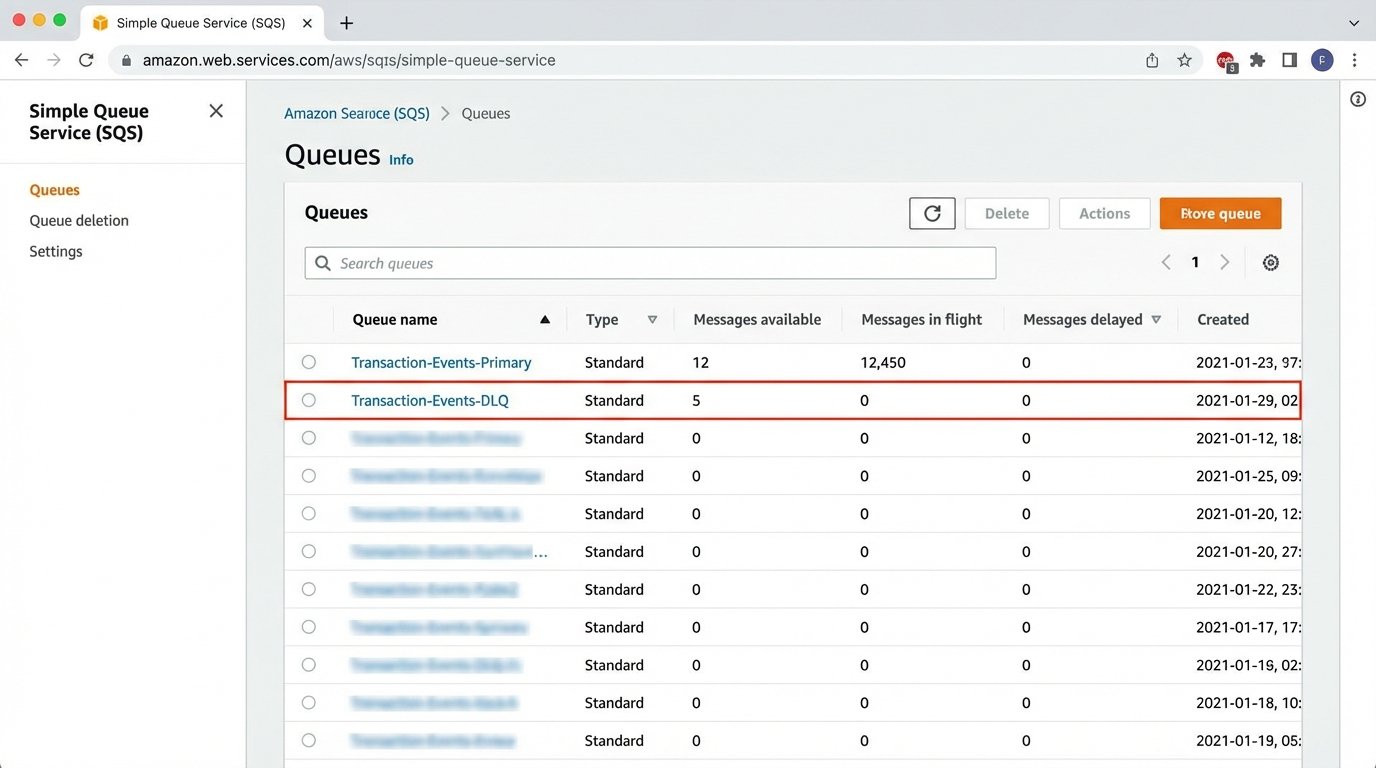
Ignoring these realities means your support team becomes the error handling logic, manually fixing broken states in the database. At that point, you’ve just shifted the manual work, not eliminated it.
The transition from a sequential checklist to an event-driven state machine is a fundamental shift in architecture. It forces a clear definition of dependencies and decouples services, allowing for true parallel processing. The initial build is more complex than a simple script, but it is the only viable path to creating a transaction processing system that is scalable, resilient, and not bottlenecked by a human checking their email.