
Forget the newsletters and the top-ten listicles. That information is processed, delayed, and curated for mass consumption. By the time a “trend” hits a blog, the engineers who built it are already working on its replacement. The real signal is buried in raw, unstructured data sources: API changelogs, SEC filings, patent applications, and GitHub commit histories. Staying updated isn’t a passive activity. It requires building a system to aggressively extract and filter this information before anyone else bothers to write an article about it.
This is not a guide for managers. This is a schematic for building an automated intelligence pipeline. The goal is to get notified about a significant technology shift the day it’s committed to a repository, not the day a journalist decides it’s newsworthy. We will treat trend-watching as a data engineering problem because that’s what it is.
Step 1: Isolate Primary Signal Sources
Your first task is to bypass the content marketers and go directly to the source code of business and legal strategy. The signal-to-noise ratio is abysmal, but the signals you do find are pure. We are not looking for opinions. We are looking for documented, legally filed, or coded intent.
API & Developer Changelogs
A company’s API is a direct reflection of its strategy. New endpoints, deprecated fields, or authentication changes telegraph product shifts long before a press release. Target the developer portals of major MLS providers, CRE data aggregators like CoStar, and residential platforms like Zillow. Most have a changelog page buried somewhere. These are frequently updated without any public announcement.
Your script will need to periodically fetch and hash the content of these pages to detect changes. Don’t trust their RSS feeds; they are often an afterthought.
U.S. Patent & Trademark Office (USPTO) Filings
Patents are a direct window into a company’s R&D pipeline, years in advance. The data is public but deliberately difficult to parse. You need to construct precise queries to target relevant filings. Focus on patent applications, not just granted patents, as they show forward-looking intent.
- Query Structure: Combine classification codes (e.g., G06Q 50/16 for real estate) with assignee names (“Zillow, Inc.”) and keywords (“machine learning,” “asset tokenization”).
- Data Extraction: The bulk data is available in XML format. You will need to build a parser to strip out the abstract and claims sections, which contain the technical meat.
This is a noisy data source, but finding one patent for an “automated underwriting engine using federated learning” from a major player is worth more than a hundred blog posts.
SEC Filings (10-K & 8-K)
Publicly traded real estate technology companies are legally required to disclose risks and strategic shifts. The 10-K (annual) and 8-K (unscheduled material events) filings are goldmines. Ignore the financial tables. Search the text for terms like “acquisition,” “technology,” “platform integration,” and “capital expenditure for software.”
A sudden mention of investing heavily in “cloud infrastructure” or acquiring a small AI firm in an 8-K filing is a five-alarm fire drill of a signal.
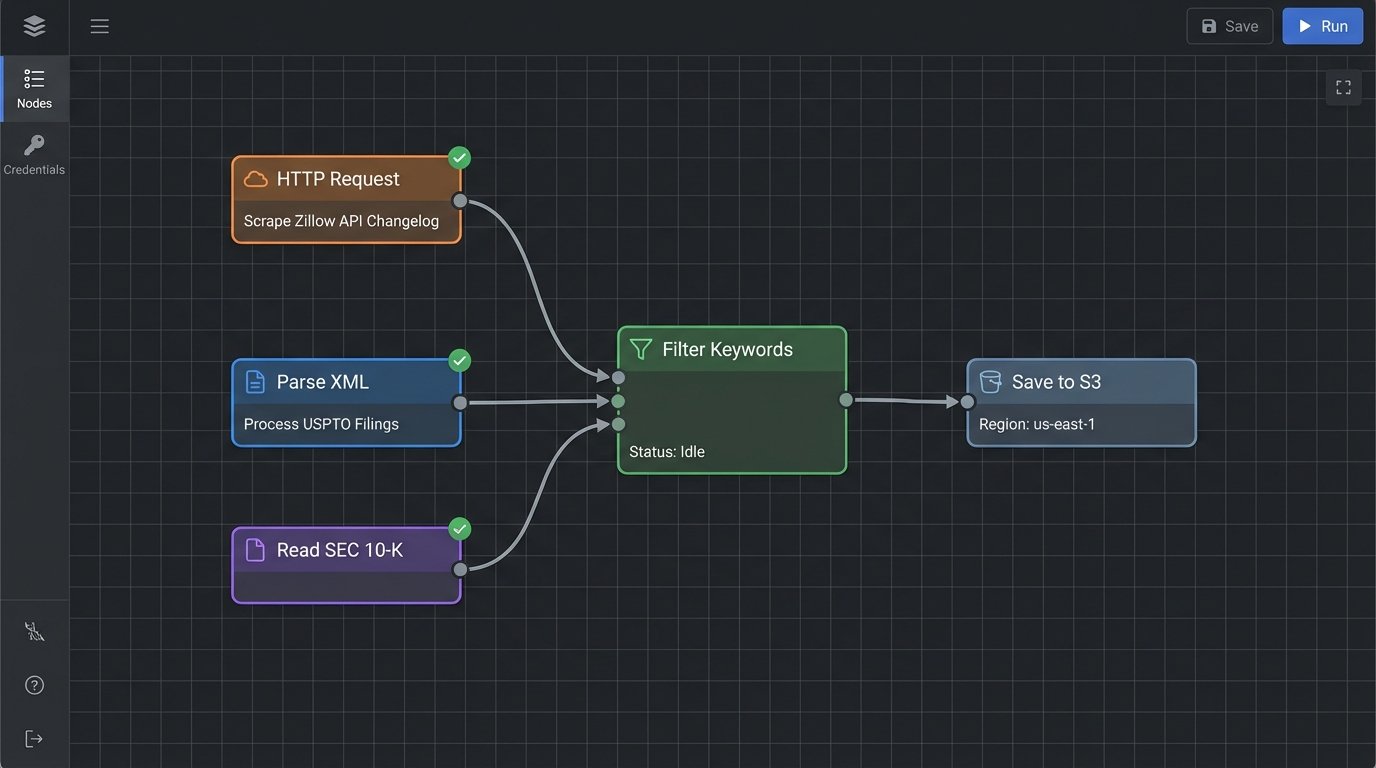
Step 2: The Aggregator Architecture
We need a simple, cheap, and effective machine to fetch, store, and process this data. Over-engineering this is a common failure mode. A serverless architecture is the logical choice because the workload is intermittent. We don’t need a 24/7 server burning money to run a script for five minutes every hour.
The architecture is straightforward: a scheduler triggers a cloud function that executes our collection scripts. The function pulls data from the target sources, performs a basic transformation, and dumps the result into a storage service. Amazon S3 or Google Cloud Storage works fine for this. For slightly more structured needs, a NoSQL table in DynamoDB or Firestore can store state, like the last seen hash of a changelog page.
This entire setup should cost pennies per month. If it costs more, you’ve built it wrong.
Step 3: Scraper Implementation Logic
Scraping is a brittle process. A frontend developer changing a CSS class name can break your entire pipeline. Your code must be defensive, with robust error handling and logging. Assume the target site will change without notice. Assume the connection will fail. Assume the data will be malformed.
The following Python script is a minimal example for fetching a hypothetical changelog. It uses `requests` for the HTTP call and `BeautifulSoup` to parse the HTML. The key is not the code’s complexity but its explicit purpose: find a specific element, extract its content, and hash it for future comparison.
import requests
from bs4 import BeautifulSoup
import hashlib
import boto3
import os
# --- Configuration ---
URL_TO_SCRAPE = "https://developers.example-proptech.com/changelog"
# This is a brittle selector. It WILL break.
CSS_SELECTOR_FOR_CONTENT = "div.changelog-entries"
BUCKET_NAME = os.environ.get("S3_BUCKET_NAME")
STATE_FILE_KEY = "changelog_hash.txt"
def get_prior_hash(s3_client):
"""Fetches the last known hash from S3."""
try:
obj = s3_client.get_object(Bucket=BUCKET_NAME, Key=STATE_FILE_KEY)
return obj['Body'].read().decode('utf-8')
except s3_client.exceptions.NoSuchKey:
print("No prior hash found. This must be the first run.")
return None
def store_new_hash(s3_client, new_hash):
"""Stores the new hash back into S3."""
s3_client.put_object(Bucket=BUCKET_NAME, Key=STATE_FILE_KEY, Body=new_hash)
print(f"Stored new hash: {new_hash}")
def handler(event, context):
"""Lambda handler function."""
s3 = boto3.client('s3')
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
try:
response = requests.get(URL_TO_SCRAPE, headers=headers, timeout=15)
response.raise_for_status() # Will raise an HTTPError for bad responses (4xx or 5xx)
except requests.exceptions.RequestException as e:
print(f"Error fetching URL: {e}")
# Logic to send a failure alert could go here
return
soup = BeautifulSoup(response.text, 'html.parser')
content_div = soup.select_one(CSS_SELECTOR_FOR_CONTENT)
if not content_div:
print("Error: Could not find the content element with the specified selector.")
# Logic to send a selector failure alert
return
current_content = content_div.get_text().strip()
current_hash = hashlib.sha256(current_content.encode('utf-8')).hexdigest()
prior_hash = get_prior_hash(s3)
if current_hash != prior_hash:
print(f"Change detected! New hash: {current_hash}")
# --- TRIGGER ALERTING MECHANISM HERE ---
# For example, send to Slack, SNS, etc.
# subject = "PropTech Changelog Update Detected"
# message = f"A change was detected on {URL_TO_SCRAPE}. Check the source."
# send_alert(subject, message)
store_new_hash(s3, current_hash)
else:
print("No changes detected.")
return {'status': 'OK'}
This script is a skeleton. A production version needs more sophisticated error handling, logging to a service like CloudWatch, and a dead-man’s switch to alert you if the script itself fails to run. Keeping a scraper alive is like trying to shove a firehose through a needle; it requires constant pressure and adjustment.
Step 4: Processing and Filtering
The raw scraped data is mostly noise. The next step is to force-filter it against a dictionary of keywords that are relevant to your operational context. This is not a static list. It must be maintained and pruned weekly. Your initial list should contain technology markers, business concepts, and competitors.
- Technology Tier 1: “API v3”, “GraphQL”, “gRPC”, “beta”, “deprecation”
- Technology Tier 2: “AI”, “machine learning”, “LLM”, “computer vision”, “geospatial”
- Business Concepts: “tokenization”, “iBuyer”, “fractional ownership”, “acquisition”, “partnership”
For each piece of scraped content, you run a check. If content contains a keyword, it passes the filter. If not, it’s discarded. A more advanced approach involves simple diffing. For changelogs or commit messages, store the previous version and compute a line-by-line diff. The alert should contain only the added or modified lines, not the entire document.
Step 5: Alerting on Actionable Signals
An email inbox is where data goes to die. Do not send alerts to email. The signal must be injected directly into your team’s workflow, which for most of us is a chat application like Slack or Microsoft Teams. These platforms are built around webhooks, which provide a simple HTTP endpoint for receiving structured data.
The alert should be dense with context. It needs to include the source, the detected keywords, a direct link to the source, and the changed text itself. The goal is to allow a recipient to judge the importance of the signal in under five seconds without leaving the chat client.
Example Slack Payload
A simple POST request to a Slack webhook URL with a JSON payload is all that’s required. You can format the message with their Block Kit UI framework to make it more readable.
def send_slack_alert(webhook_url, source_url, changed_text):
"""Sends a formatted alert to a Slack channel."""
message = {
"blocks": [
{
"type": "header",
"text": {
"type": "plain_text",
"text": ":warning: New PropTech Signal Detected"
}
},
{
"type": "section",
"fields": [
{"type": "mrkdwn", "text": f"*Source:*\n<{source_url}|Link>"},
]
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"*Detected Change:*\n{changed_text[:2500]}..."
}
}
]
}
try:
requests.post(webhook_url, json=message, timeout=10)
except requests.exceptions.RequestException as e:
print(f"Failed to send Slack alert: {e}")
This function creates a clean, structured notification. The engineer who sees this can immediately assess its relevance and decide whether to investigate further.
Step 6: Maintenance is Not Optional
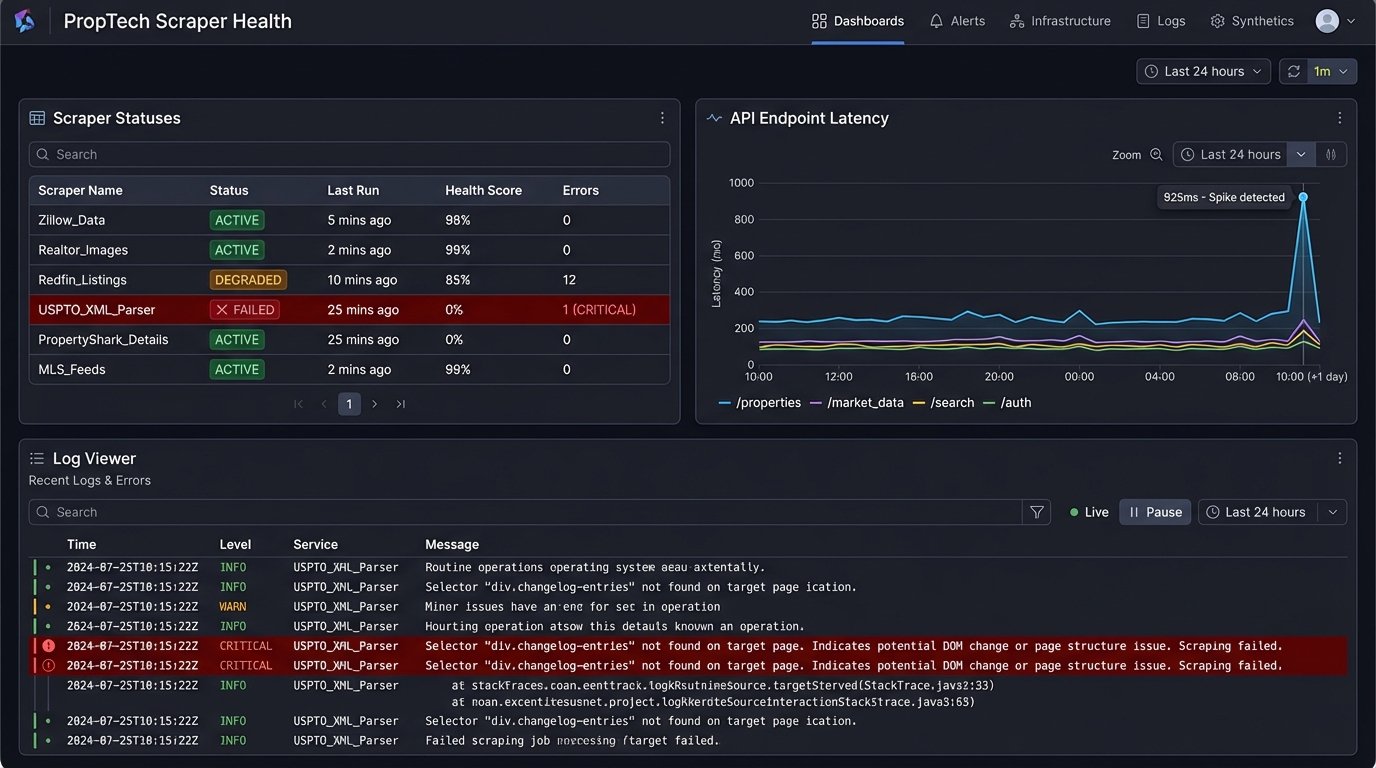
This system is not a finished product. It is a living tool that requires care. You must build health checks that verify not only that the scraper ran, but that it returned the data you expected. A scraper that runs successfully but returns an empty payload because of a changed CSS selector is a silent failure, the most dangerous kind.
Schedule a quarterly review of your data sources. Are they still relevant? Have new companies emerged that need to be added to the target list? Is your keyword dictionary full of obsolete terms? A system like this that goes unmaintained for six months is worse than having no system at all, because it provides a false sense of security.
Extending the Engine for Higher Fidelity Signals
Once the basic pipeline is stable, you can bolt on more sophisticated processing modules to improve signal quality. These are not necessary to start, and can be a massive time-sink if you’re not careful.
Job Board Monitoring
A company’s hiring patterns are a clear tell of their strategic direction. Scraping the job boards of key PropTech firms for specific engineering roles reveals their internal tech stack and priorities. If a company suddenly posts ten openings for “Senior Data Scientist – Natural Language Processing,” you can infer they are building a new product based on text analysis. This is a far stronger signal than any marketing announcement.
Venture Capital Investment Tracking
Following the money is the oldest trick in the book. You can programmatically track SEC Form D filings, which disclose new venture capital rounds. By parsing these filings for companies in the real estate sector, you can see which sub-domains are getting funded. The APIs for this data are often wallet-drainers, but the raw SEC EDGAR database is free if you are willing to build the parser yourself.
Relying on headlines means you’re already behind the curve. The actionable intelligence is in the raw, operational data. You have to build the machinery to dig it out and pipe it to where you can see it. This isn’t about being passively informed. It’s about engineering a preemptive information advantage.