Lead Scoring Algorithms: Moving Beyond the Guesswork
Manual lead review is a process designed for failure at scale. It injects human bias, latency, and inconsistency into the one pipeline that cannot afford it. Sales teams claim they can “feel” a good lead, but that intuition doesn’t parse a million events per day from your website, email server, and product analytics. The entire model is a bottleneck waiting to happen. The only logical path forward is to let the machine do the initial triage.
We build systems that prioritize leads based on demonstrated behavior, not a salesperson’s gut feeling after a 15-second glance at a contact form. An algorithm that weights a pricing page visit higher than a blog comment isn’t magic. It’s just a structured, repeatable form of logic that doesn’t get tired or have a bad quarter. We are replacing subjective guesswork with a system that can be measured, debated, and tuned.
Deconstructing the Manual Process
Before building a new system, we must first map the failure points of the old one. The manual qualification queue is where promising leads go to die. It’s a system that fundamentally breaks under its own weight as a company grows.
The Latency Tax
Every minute a lead waits for a human to review it, its value decays. A prospect who just downloaded a whitepaper is at peak interest. An hour later, they are in another meeting, thinking about a different problem. The manual queue imposes a latency tax on every single inbound signal. An automated scoring system can process that signal in milliseconds, routing a high-value lead to a sales rep before they’ve even closed the browser tab.
Bias as a Systemic Flaw
Human reviewers operate on heuristics and biases. A lead from a Fortune 500 company gets immediate attention, while one from an unknown domain might sit for days, even if that user shows ten times the behavioral engagement. An algorithm is agnostic. It only processes the event stream you feed it, weighting a webinar attendance from a small company the same as one from an enterprise, assuming you configure it correctly.
Core Architecture of an Automated Scorer
Building a lead scoring engine requires three primary components: an event ingestion pipeline, a logic core to perform the calculations, and a data store to persist the scores. Getting any one of these wrong introduces a point of failure that invalidates the entire system.
The Event Bus is Non-Negotiable
You cannot build a real-time scoring system on batch jobs and CSV imports. You require a central nervous system for user actions. An event bus, like Kafka or AWS Kinesis, is the correct tool. It provides a durable, ordered stream of events that multiple services can consume. Every user action, from a page view to an email open, gets published as a structured event. This decouples the event producers (your website, your email platform) from the consumers (the scoring engine).
This is the foundation. If you try to build this with a mess of ad-hoc webhooks pointing at a monolithic application, you will spend your time debugging dropped data instead of refining your scoring model.
The Scoring Model: Start Simple
The logic itself should begin as a simple additive model. Do not start with machine learning or predictive analytics. Start with a weighted checklist. A user’s score is the sum of the values of the actions they have performed. This model is transparent, easy to debug, and simple for the sales team to understand.
- Page View (Blog Post): +1 point
- Page View (Pricing Page): +5 points
- Email Opened: +2 points
- Email Link Clicked: +3 points
- Form Submission (Contact Us): +15 points
- Webinar Attended (Live): +10 points
This configuration lives in a database table or a simple config file, not hardcoded in the application. You will be asked to change these values constantly.
Choosing a Data Store
The computed score needs to live somewhere. The primary debate is speed versus integration cost. A key-value store like Redis is extremely fast for reads and writes, making it ideal for the scoring worker to fetch the current score, add the new value, and write it back. The downside is that it creates another data silo that you must bridge to your main CRM.
The alternative is writing the score directly to a custom field on the contact or lead object in your CRM. This simplifies the architecture by keeping the score next to the lead data. The performance penalty is severe. You are now subject to the CRM’s API rate limits and processing latency for every single scoring event.
Implementation Details
The architecture is a blueprint. The actual implementation involves wiring up data sources, writing the core processing logic, and pushing the final result to the end users.
Capturing Behavioral Data
Web behavior is typically captured with a client-side JavaScript snippet. A tool like Segment or Snowplow simplifies this by providing a common API to track events and route them to various destinations, including your event bus. For server-side events like email opens or unsubscribes, you configure webhooks in your marketing automation platform to send a POST request with a JSON payload to an ingestion endpoint you control.
A typical webhook payload for an email click might look like this. The job of your ingestion service is to parse this and put a standardized event onto the bus.
{
"event": "click",
"email": "test.user@example.com",
"timestamp": "2023-10-27T10:00:00Z",
"campaign_id": "q4-promo-2023",
"url": "https://www.yourcompany.com/pricing"
}
The Scoring Worker
A serverless function is the standard tool for the job. It’s a stateless piece of code that triggers whenever a new message appears on the event bus. This approach is cost-effective because you only pay for compute time when events are being processed. It also scales automatically under heavy load.
The function’s logic is straightforward:
- Parse the incoming event to identify the user and the action.
- Fetch the user’s current score from the data store. If no score exists, start at zero.
- Look up the point value for the action from your scoring configuration.
- Add the new points to the current score.
- Write the new total score back to the data store.
This entire transaction must be atomic. Failures between steps can lead to inconsistent data.
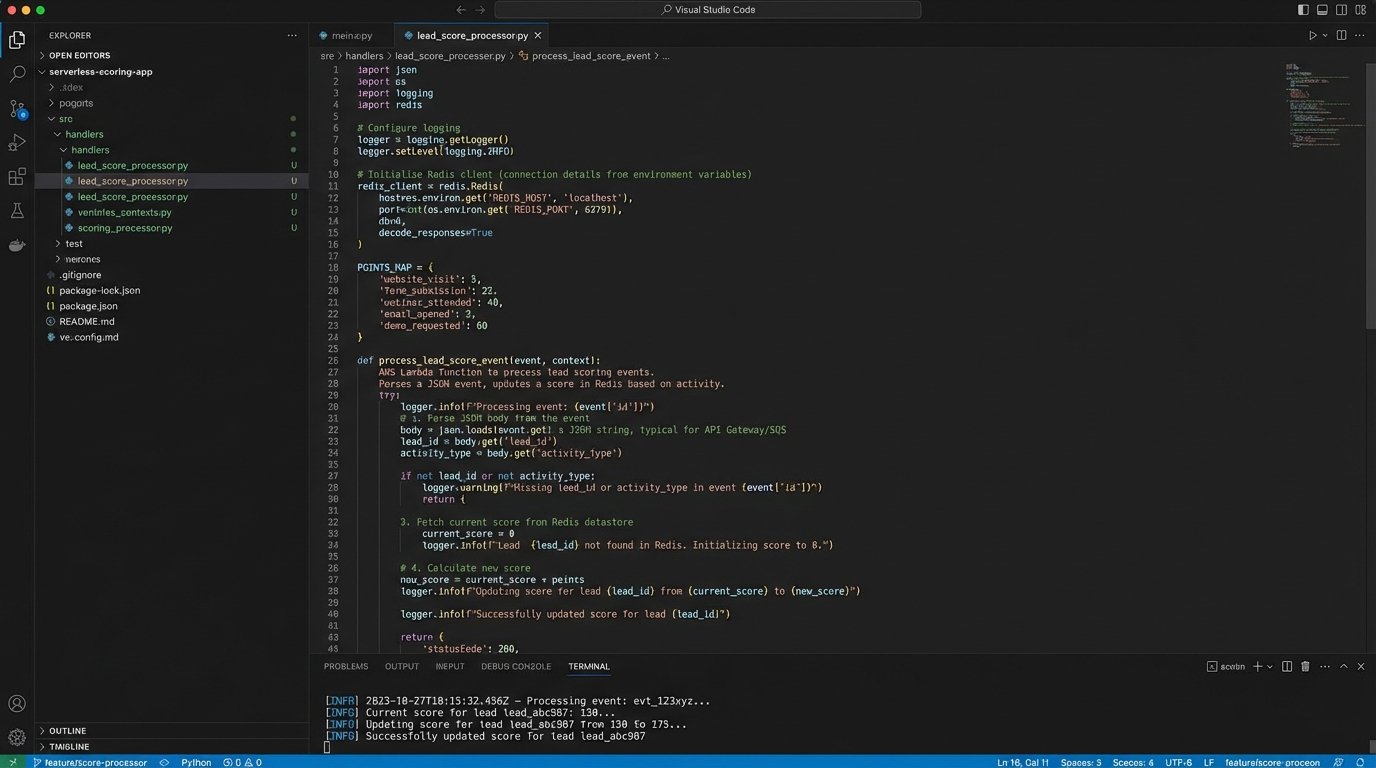
Sample Processing Logic in Python
This is a simplified example of what a scoring function might contain. It shows how to map an event to a score and update a user’s record. The `datastore` objects are abstractions for whatever database you choose.
# A simple dictionary to hold scoring rules. In production, this comes from a database.
SCORING_RULES = {
'viewed_pricing_page': 5,
'attended_webinar': 10,
'unsubscribed': -20
}
def process_lead_score_event(event):
"""
Processes a single user event to update their lead score.
"""
user_email = event.get('email')
event_type = event.get('type')
if not user_email or not event_type:
# Malformed event, drop it.
return
# Get the point value for this event type, default to 0 if not found.
points_to_add = SCORING_RULES.get(event_type, 0)
if points_to_add == 0:
# No action needed for this event type.
return
# Fetch the user's current score.
current_score = datastore.get_score(user_email) or 0
# Calculate the new score.
new_score = current_score + points_to_add
# Persist the new score.
datastore.set_score(user_email, new_score)
# Push the updated score to the CRM.
crm_api.update_contact_score(user_email, new_score)
print(f"Processed event '{event_type}' for {user_email}. Score is now {new_score}.")
Notice the inclusion of CRM API calls. This step is a common point of failure due to network issues or API limits. It must have retry logic with exponential backoff.
Beyond Simple Addition
A simple additive model will get you 80% of the way there. The remaining 20% requires handling the dimension of time and more nuanced user signals.
Score Decay
A lead’s engagement is ephemeral. A burst of activity three months ago is less relevant than a single pricing page view today. A score decay mechanism is needed to reflect this. A simple approach is a nightly cron job that reduces every lead’s score by a small amount, like 1%. This ensures that only actively engaged leads remain at the top of the list. More complex models might apply decay based on the age of each individual event, but this adds significant computational overhead.
Negative Scoring
Not all behaviors are positive. An unsubscribe action is a powerful negative signal. A visit to the “Careers” section of your website indicates their intent may not be related to buying your product. These events should subtract points from a lead’s score. Implementing negative scoring prevents sales from wasting time on prospects who are actively disengaging or have identified themselves as poor fits.
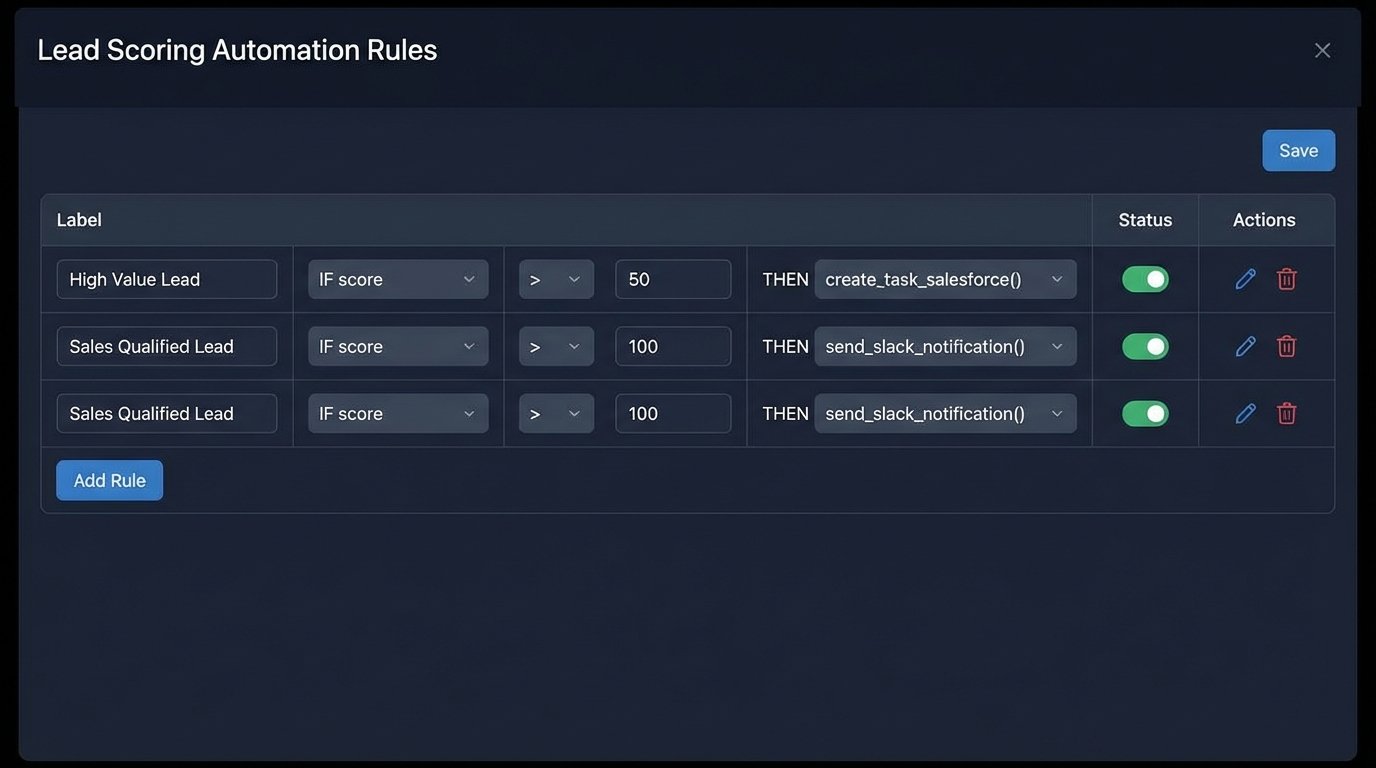
Actionable Thresholds
A score is useless without a corresponding action. The final piece of the system is a set of rules that trigger based on score thresholds.
- Score 25-49 (Engaged): Add to a “Warm Leads” marketing nurture campaign.
- Score 50-99 (Sales Ready): Create a task in the CRM for a Sales Development Rep (SDR) to review and contact.
- Score 100+ (High Intent): Send a real-time notification (e.g., Slack) to the assigned account owner for immediate follow-up.
These thresholds are the primary tuning mechanism for the business. They must be easily adjustable by a sales operations manager, not a developer.
Operational Hazards
Launching a scoring system is not the end of the project. Maintaining it is the real work. These systems are brittle and susceptible to data quality issues.
The Identity Resolution Problem
The biggest technical challenge is identity resolution. A user might browse your website anonymously, then sign up for a webinar with a personal email, and finally submit a contact form with their corporate email. Your system needs a way to merge these separate identities into a single profile. Failing to do this results in fragmented scores and a completely inaccurate picture of a lead’s true engagement level.
Monitoring and Governance
The system needs a dashboard. You must monitor event throughput, API error rates from your CRM integration, and the overall distribution of scores. An anomaly, like a sudden drop in events from your website, could indicate a broken tracking script. Sales reps will also attempt to manually override scores for their pet leads. These overrides must be logged and audited. The automated score should be the source of truth, with manual changes being the rare exception that proves the rule.
Validating the Model
The only metric that matters is the correlation between a high lead score and a closed-won deal. Periodically, you must export all lead scores at the moment they converted to an opportunity, and then map that against your win rates. If leads with a score of 80 are not converting at a higher rate than leads with a score of 30, your weighting model is wrong. The scoring rules are not sacred. They are a hypothesis waiting to be invalidated by data. You must analyze the results and tune the point values. This feedback loop is what separates a useful automation from a vanity project.