
Most automated follow-up systems are built on a foundation of optimistic assumptions. They assume clean data, infallible APIs, and leads who behave predictably. This is a direct path to failure. The goal is not to build a perfect sequence. The goal is to build a resilient system that anticipates breakage, because production environments are designed to break things.
Stop Pretending All Leads Are Identical
The cardinal sin is routing every new lead, regardless of origin, through the same generic sequence. A lead who downloads a technical whitepaper has a different intent than one who hits the “Request a Demo” button. Treating them the same shows a fundamental misunderstanding of the sales pipeline and wastes the context you fought to capture.
Your entry point, whether it’s a web form or an API integration, must capture and pass this context. The `lead_source` is not optional metadata. It is the primary key for branching your automation logic. A lead from a webinar requires a follow-up that references the webinar content. A lead from a direct contact form expects a prompt, direct connection to a sales rep. Anything else is noise.
A properly structured lead object entering your system should look less like a simple email address and more like a dossier. Your first logic gate should be a switch statement based on the `source` property. No exceptions.
Enriching the Payload
Every piece of data you can collect at the source needs to be injected into the payload that triggers the automation. This includes UTM parameters from the URL, the specific page the form was submitted on, and any hidden fields you can populate. This data is ammunition for personalization. A generic “I saw you were on our site” is weak. A targeted “I see you downloaded our guide on Kubernetes cost optimization” forces a response.
Here is a minimal example of a JSON payload that provides actual context for an automation engine. If your payload is just an email and a name, you have already failed.
{
"email": "jane.doe@example.com",
"firstName": "Jane",
"lastName": "Doe",
"phone": "+15551234567",
"leadData": {
"source": "content_download_kubernetes_guide",
"medium": "paid_search",
"campaign": "q4_enterprise_focus",
"pageURL": "https://example.com/guides/kubernetes-cost-optimization",
"submissionTimestamp": "2023-10-27T10:00:00Z"
}
}
Your system has to be architected to parse this nested object and use its keys to make decisions. Anything less is just a glorified mailing list.
Your Timing is Predictable and Impersonal
An email that arrives exactly 0.5 seconds after a form submission is an obvious machine. It signals that the lead is just another row in a database, now entering a queue to be processed. This instantaneous feedback can feel efficient, but it destroys any illusion of a personal touch. The lead knows no human could have possibly read their request and responded that quickly.
Inject a synthetic delay. This delay should not be a static five minutes. Randomize it within a logical window, say three to seven minutes. This simple step mimics the natural latency of a human operator receiving a notification, opening it, and typing a reply. It is a small deception that has a disproportionate impact on perception.

The logic should also account for time zones and business hours. A lead submitting a form at 2 AM on a Saturday should not get a “personal” follow-up at 2:03 AM. The automation should have the intelligence to hold the message until 9:15 AM on Monday in the lead’s inferred time zone. This requires IP-based geolocation or a time zone field in your form, but it is necessary to maintain credibility.
The Machine Doesn’t Know When to Shut Up
This is the most common and damaging failure mode. A lead receives your first two automated emails, then replies with “I’m interested, but can we talk next week?” A badly designed system ignores this reply completely. It proceeds to send step three, four, and five of the sequence, asking if they are still alive and cluttering their inbox. This behavior transforms a warm lead into an irritated contact who now thinks your company is incompetent.
Your automation platform must be configured to listen for replies. This is not a “nice-to-have” feature. It is a mandatory component of a functioning system. The solution is to bridge your sending infrastructure with your CRM or automation engine. Use webhooks. Services like SendGrid, Mailgun, or Postmark can send a webhook payload to an endpoint you control every time an email is received at a specific address.
Architecting a Stop Trigger
The architecture looks like this:
- The automation sends emails from a dedicated, monitored address (e.g., `sales@your-company.com`).
- Your email provider is configured to POST a webhook to your API endpoint whenever a new email arrives at that address.
- Your endpoint receives the payload, parses the sender’s email (`from` address), and uses it to query your CRM or database.
- Once a match is found, your code updates the lead’s record. This could mean changing a status from “Nurturing” to “Responded” or adding a specific tag like `STOP_SEQUENCE`.
- Every step in your automation sequence must first check for this status or tag. If it exists, the sequence terminates immediately.
This creates a closed-loop system. The automation is no longer a blind fire-and-forget cannon. It is a system that reacts to external input, which is the only way to operate safely.
Ignoring the Plumbing: API Throttling and Failed Sends
You will get rate-limited. It is not a question of if, but when. Whether you are calling a CRM API to create a lead or a mail provider API to send a message, there are hard limits on how many requests you can make per second or per minute. A naive script that loops through 10,000 leads and fires off API calls in a tight loop will hit the ceiling fast. The API will start returning `429 Too Many Requests` errors, and your system will start silently dropping leads.
Building a system without retry logic is like trying to send a freight train’s worth of data through a garden hose. It will back up and fail catastrophically. You must implement an exponential backoff strategy for any critical API call.

When a `429` or a `5xx` server error is received, the code should not just fail. It should wait for a calculated period and then try again. The wait time should increase with each subsequent failure. For example: wait 1 second, retry. Fail again? Wait 2 seconds, retry. Fail again? Wait 4 seconds, and so on. This gives the API time to recover and prevents your script from launching a denial-of-service attack against your own provider.
Here is a simplified Python-esque pseudo-code for this logic:
function send_with_backoff(request):
max_retries = 5
base_delay_seconds = 1
for i in range(max_retries):
response = make_api_call(request)
if response.status_code == 200:
return "Success"
if response.status_code in [429, 500, 503]:
# Exponential backoff with jitter
wait_time = (base_delay_seconds * 2**i) + random.uniform(0, 1)
print(f"API error. Retrying in {wait_time:.2f} seconds...")
time.sleep(wait_time)
else:
# Handle non-transient errors (e.g., 400 Bad Request)
log_permanent_failure(request, response)
return "Permanent Failure"
log_final_failure(request)
return "Failed after max retries"
This logic prevents temporary network glitches or API load from causing permanent data loss. It is a fundamental part of building durable systems.
The Garbage In, Garbage Out Protocol
Your personalization is only as good as the data you feed it. A follow-up email that starts with “Hi ,” because the first name field was blank is a clear sign of amateur execution. This is not just about aesthetics. It erodes trust and signals that your internal processes are sloppy.
Data hygiene starts at the source: the form. Use front-end validation to catch obvious errors, but never trust it. All validation must be re-checked on the server side before the data is ever committed to your database. Strip whitespace. Check for invalid characters. For phone numbers, normalize them into a standard format like E.164 (`+15551234567`) before passing them to an SMS gateway. An SMS API will choke on `(555) 123-4567`.
Your templating engine needs fallbacks for every single personalization token. Never assume data will be present. A template snippet should look like `{{ first_name | fallback: ‘there’ }}` not `{{ first_name }}`. This ensures that even with missing data, the output is grammatically correct and does not expose your system’s failures to the end user.
Your Sequence is a Monolith Waiting to Collapse
Building a single, 20-step automation sequence that tries to handle every possible outcome is an architectural mistake. This monolithic design is brittle, impossible to debug, and inflexible. When a lead needs to be moved from one path to another, you end up with a tangled mess of conditional logic that no one understands. Inevitably, it breaks, and pinpointing the failure in a giant chain of events is a nightmare.
Deconstruct the monolith. Re-architect your automation around smaller, modular, and event-driven sequences. Instead of one “New Lead” sequence, you might have several:
- Sequence A (Initial Triage): Runs for all new leads. Its only job is to enrich the contact data, apply initial tags based on source, and then trigger the appropriate next sequence. It lasts for no more than one hour.
- Sequence B (Content Nurture): Triggered by the tag `source:whitepaper`. Sends two follow-ups related to the downloaded content.
- Sequence C (Sales Demo): Triggered by the tag `source:demo_request`. Immediately notifies a sales rep and sends a confirmation with a booking link.
- Sequence D (Re-Engagement): Triggered by a contact being inactive for 90 days. Sends a single check-in email.
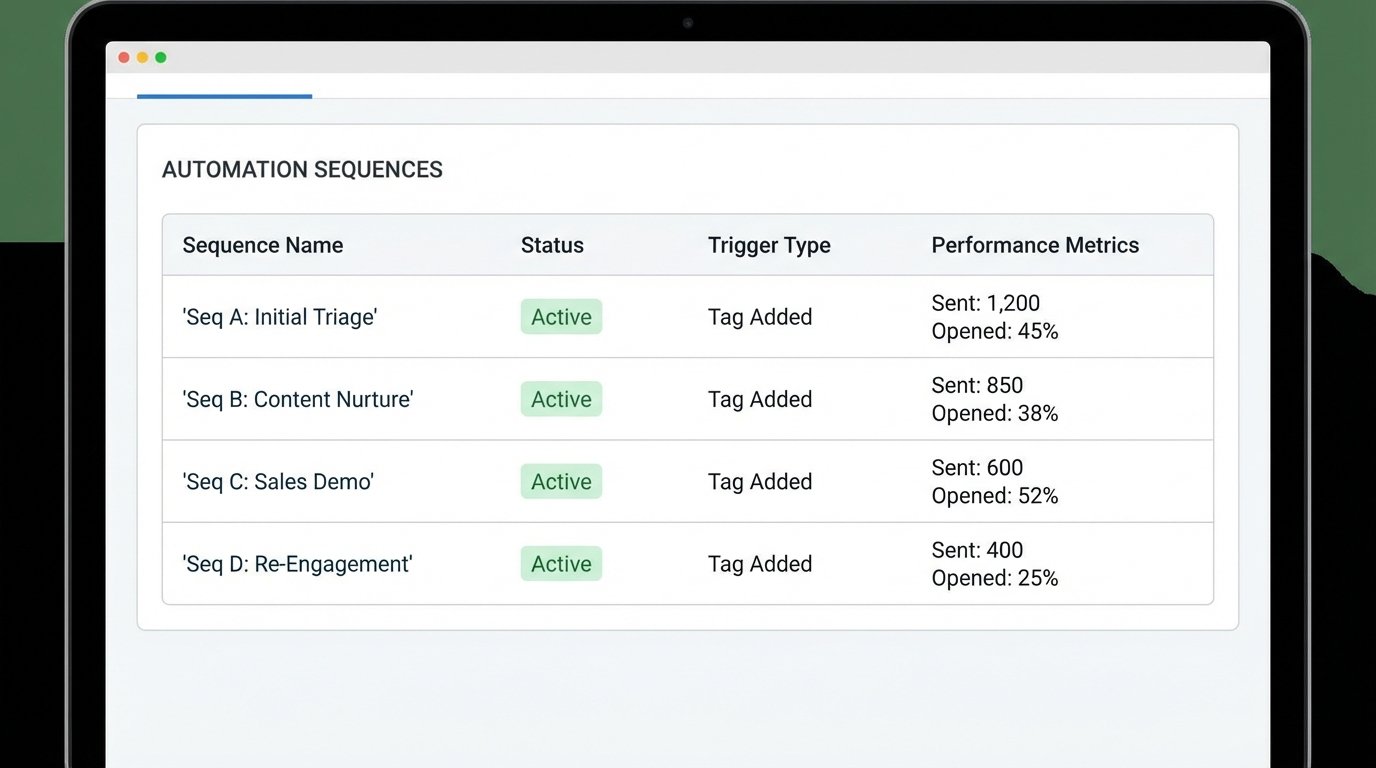
This approach is far more resilient. If the content nurture sequence has an error, it does not affect the high-priority sales demo flow. You can update, test, and deploy each module independently. Debugging becomes trivial. You are no longer hunting for a needle in a haystack. You are inspecting a specific, self-contained machine with a clearly defined purpose.
The system’s state is managed through tags or custom fields on the contact record, not by a lead’s position within a giant, opaque sequence. This makes the entire system more transparent and easier to manage manually when the automation fails, which it will.