Mistakes to Avoid When Using ChatGPT for Real Estate Content
Connecting a large language model to your content pipeline without proper architecture is not innovation. It is a managed denial-of-service attack against your own brand reputation. The core failure is treating the API as a magic content box instead of a probabilistic text generator that requires deterministic inputs and aggressive post-processing. Your goal is not to generate text. Your goal is to generate leads and close deals, and unverified, generic content actively works against that objective.
We are not here to discuss the ethics or the future of work. We are here to talk about production systems. These are the critical engineering mistakes that turn a promising automation project into a liability that burns cash and erodes client trust.
1. The “Fire and Forget” Prompting Fallacy
The most common failure is the single, simple prompt. An engineer throws a listing address and a vague instruction like “Write a description” at the API and pipes the result directly into a CMS. This approach guarantees generic, soulless copy that ignores the property’s unique selling points and your agency’s brand voice. The model has no context, so it invents some, usually based on the most stereotyped marketing language imaginable.
This is lazy engineering, and it produces garbage.
A production-grade system uses prompt chaining and context injection. The initial prompt should not be to write the final copy. It should be to analyze the raw data from the MLS feed. Subsequent prompts build on that analysis, layering in neighborhood data, agent persona, and target buyer demographics. Each step refines the output, constraining the model’s creativity and forcing it toward a factually-grounded, strategically-aligned result.
Your first prompt asks the model to extract key features into a structured format. Your second prompt takes that structure and asks it to identify the likely buyer. Only on the third or fourth call do you ask for the final prose.
2. Ignoring Data Source Contamination
ChatGPT’s knowledge base is a swamp of generalized, often outdated information. It has no access to your live MLS feed, local zoning updates, or recent school district performance reports. Asking it about market conditions in a specific subdivision is an invitation for hallucination. The model will confidently state falsehoods that can create legal exposure and destroy a buyer’s trust when they discover the truth.
Never trust the model’s internal knowledge for hyperlocal facts.
The correct architecture is Retrieval-Augmented Generation (RAG). You are not asking the model what it knows; you are giving it the information it needs and asking it to process it. This involves taking your private, trusted data sources, such as MLS exports, community guides, and internal market analyses, and making them accessible to the model at runtime. We strip the raw data, embed it into a vector database, and perform a similarity search based on the specific property being described.
This retrieved context is then injected directly into the prompt. The model is explicitly instructed to source its facts *only* from the provided data. Trying to build a content system without a RAG pipeline is like trying to navigate a city with a map of the wrong continent. It is professionally irresponsible.
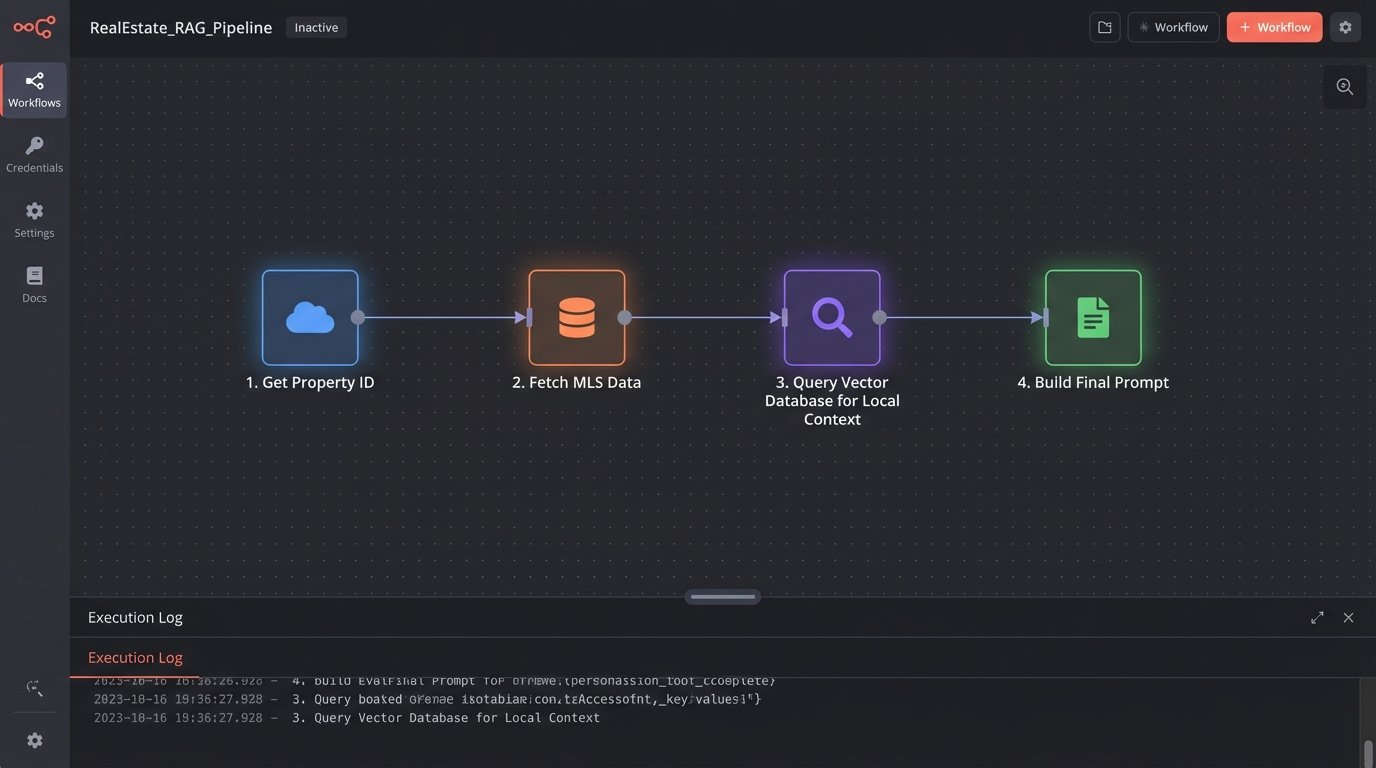
A conceptual Python snippet shows how you might structure this. This is not production code; it is a blueprint for the logic. It assumes you have functions to handle the API calls and vector database lookups.
def generate_listing_description(property_id: str, mls_data: dict, vector_db_client):
# Step 1: Extract raw property features
raw_features = mls_data.get(property_id, {})
if not raw_features:
return "Error: Property data not found."
# Step 2: Retrieve relevant hyperlocal context from Vector DB
neighborhood = raw_features.get("neighborhood")
context_query = f"Key features and amenities for {neighborhood}"
hyperlocal_context = vector_db_client.search(query=context_query, limit=5)
# Step 3: Engineer the final prompt with injected context
prompt_template = f"""
**Instructions:**
- You are a real estate copywriter for a luxury brokerage.
- Write a compelling property description.
- Source all factual claims EXCLUSIVELY from the 'PROPERTY DATA' and 'LOCAL CONTEXT' sections below. Do not add outside information.
- The target audience is high-net-worth individuals seeking privacy and modern amenities.
**PROPERTY DATA:**
{raw_features}
**LOCAL CONTEXT:**
{hyperlocal_context}
**Description:**
"""
# Step 4: Call the LLM API and return the result
# response = call_llm_api(prompt_template)
# return response.text
return prompt_template # Returning template for demonstration
3. Tolerating Generic, AI-Flagged Output
The default tone of a general-purpose model is a perfectly smooth, perfectly boring corporate voice. It uses predictable sentence structures and overuses weak adjectives. This type of content is an immediate red flag for any discerning client and performs poorly for SEO because it lacks authority and unique insight. It reads like it was written by a committee that agreed on nothing.
If you can’t tell it from your competitor’s content, it’s worthless.
You must engineer a specific voice and tone into the system prompt. This is a non-negotiable instruction set that precedes every user prompt. Define the agent’s persona, the agency’s brand values, the target audience’s sophistication level, and provide stylistic rules. Use few-shot examples, providing 2-3 high-quality, human-written examples of the desired output within the prompt itself. This gives the model a concrete pattern to emulate, drastically reducing the chances of it reverting to its default blandness.
Treating the system prompt as an afterthought is a rookie error.
4. Overlooking Structured Data Generation
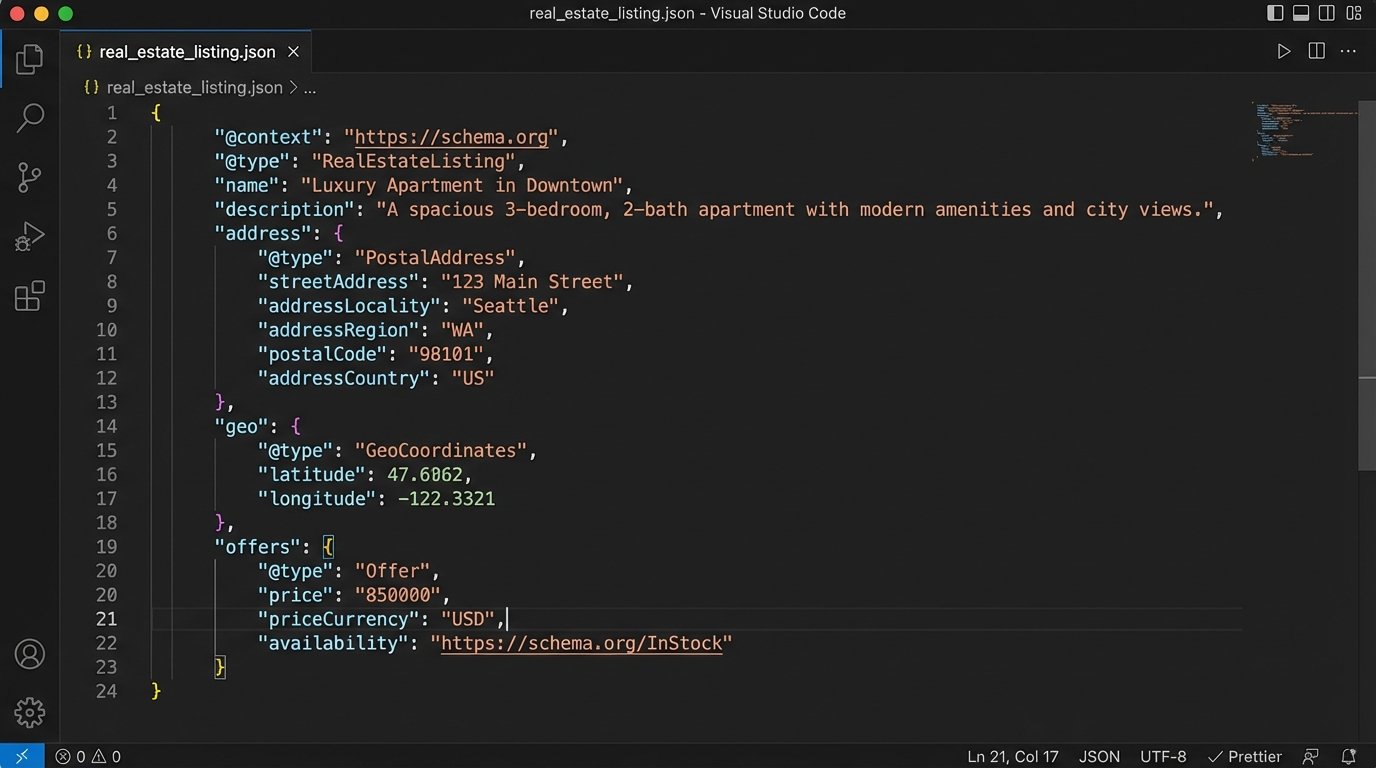
Most teams stop at generating paragraph text for blog posts or property descriptions. This misses a massive opportunity to automate the generation of high-value structured data. Search engines depend on structured data like JSON-LD to understand the content of a page. Generating this manually is tedious and error-prone. An LLM, when properly instructed, can do it flawlessly.
You are leaving SEO value on the table by only asking for prose.
Force the model to return its output in a specific format. By adding instructions like “Return your response as a valid JSON object only, with no other text or explanation,” you can transform the LLM from a copywriter into a data structuring engine. Use it to generate Schema.org markup for `RealEstateListing`, create Markdown tables for property comparisons, or even draft social media posts tailored for different platforms from a single set of facts.
This is about building an asset generation pipeline, not just a word generator. Pushing unstructured text blobs around your system is inefficient. Manipulating structured objects is the foundation of scalable automation. Forcing the LLM to provide a JSON output is like making it do the data-entry work for your other downstream systems. It is a fundamental shift from simple text generation to true workflow integration.
5. No Validation or Kill-Switch Layer
Automating content generation and pushing it live without a human or algorithmic validation step is reckless. The model can and will hallucinate facts, misinterpret data, or generate text that inadvertently violates Fair Housing guidelines. A single bad output pushed to your website can create legal nightmares or simply make you look incompetent. The damage from one error can negate the efficiency gains of a thousand successful generations.
Hope is not a production strategy.
Every piece of generated content must enter a validation queue. It should be saved as a “draft” in your CMS, clearly flagged as AI-generated. A human, typically a junior agent or marketing coordinator, must fact-check critical details: address, price, square footage, number of beds and baths. You must also implement an algorithmic check. A simple script can scan the output for problematic keywords or phrases related to protected classes under Fair Housing laws (“family-friendly,” “perfect for couples,” “walking distance to St. Mary’s”).
Your system needs a kill-switch. If your validation layer detects a spike in errors or the LLM API starts returning garbage, you need a mechanism to instantly halt the entire content pipeline. This prevents a systemic failure from polluting your entire website with bad data. Without this, you are flying blind.
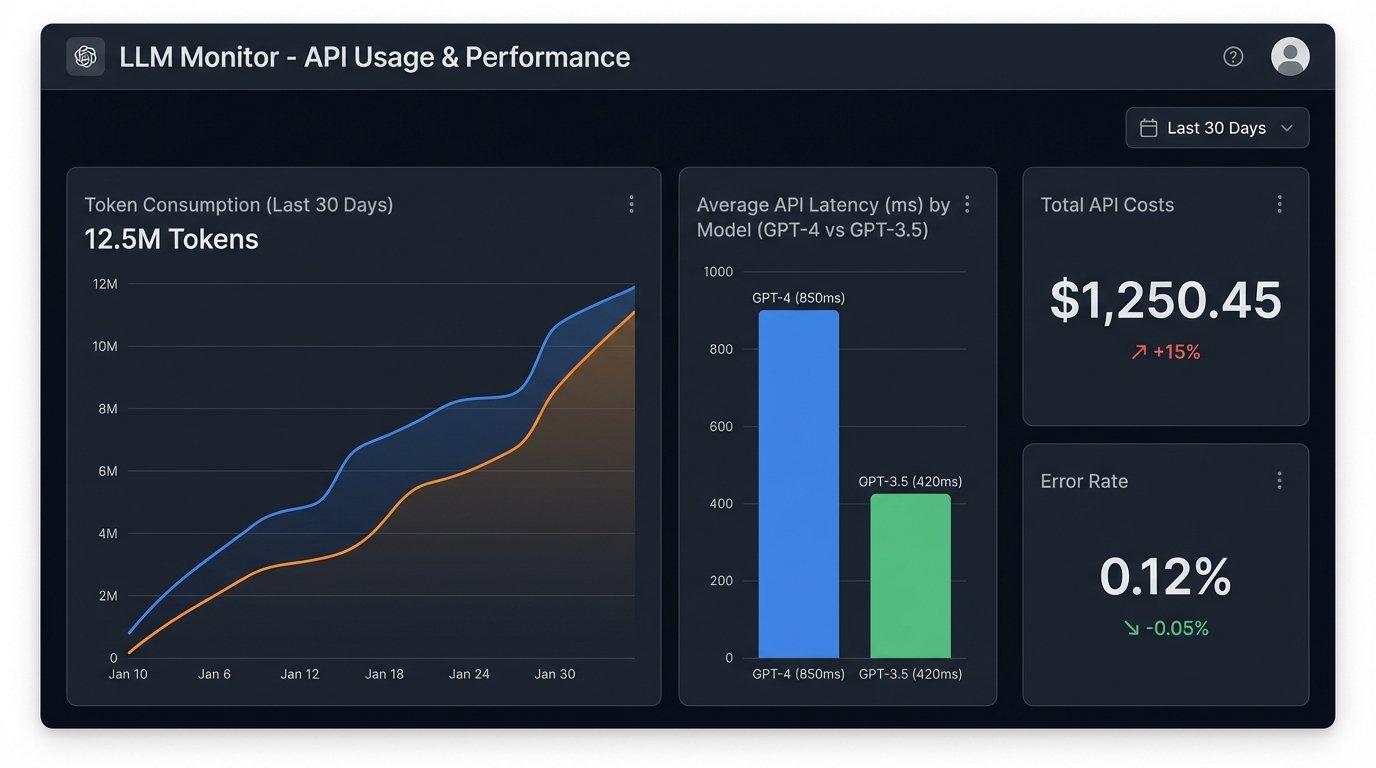
6. Neglecting Cost and Latency Guardrails
Making thousands of API calls to a model like GPT-4 for routine tasks is a fantastic way to burn through your budget. Complex prompts and long completions increase both cost and latency. If you are integrating this into a user-facing part of your application, slow API response times will kill the user experience. If it is a backend process, it will create bottlenecks.
Efficiency is a feature, not an optimization.
Implement aggressive caching. Hash the core property data and the prompt structure. If an identical request comes through, serve the cached response instead of hitting the API again. Listings do not change that frequently. There is no reason to regenerate a description multiple times a day. Secondly, use the right model for the job. Use a powerful model like GPT-4 for the final, creative prose generation, but use a cheaper, faster model like GPT-3.5-Turbo or a specialized open-source model for intermediate steps like data extraction and analysis.
Failing to monitor your token consumption and API latency is financial malpractice. Set up dashboards and alerts. Know your burn rate and your average generation time. If you cannot measure it, you cannot control it.