
The marketing departments of real estate tech vendors want you to believe we’re in a golden age of automation. They peddle AI-powered CRMs and chatbot lead generators as if they’ve solved the industry’s core inefficiencies. This is a fabrication. Most automation in this sector is a thin veneer of convenience plastered over a foundation of rotting, fragmented data and manual processes.
We are not building smart systems. We are building faster ways to manage chaos.
The Original Sin: MLS Fragmentation
Every conversation about real estate data automation must begin with the Multiple Listing Service. There are over 500 of them in the U.S. Each is a sovereign data kingdom with its own access rules, fee structures, and, most critically, its own data schema. The Real Estate Standards Organization (RESO) has been pushing for standardization for years, but adoption is sluggish and inconsistent. For engineers, this isn’t a simple data integration project. It’s a political and technical quagmire.
You’re not just hitting one API. You’re building bespoke connectors for dozens of them, each with unique authentication quirks and rate limits designed to make your life difficult. The old RETS protocol, based on XML, is still surprisingly common. It’s slow, cumbersome, and forces you to download entire data sets just to check for updates. The RESO Web API is a significant improvement, using OData and JSON, but its implementation varies wildly from one MLS to the next. One MLS might provide robust metadata endpoints, while another gives you cryptic field names that require a human-to-human phone call to decipher.
Trying to normalize data from five different MLS systems is like shoving a firehose through a needle. You spend 80% of your development cycle on data mapping and transformation logic, writing endless conditional statements to handle cases where one MLS calls a field `ListPrice` and another calls it `ListingPrice`. All this work just to get a baseline of usable data before you can even think about building an actual feature.
It’s a wallet-drainer in man-hours and a constant source of production fires.
A Taste of the Pain: The RESO Promise vs. Reality
The RESO Web API promises a standardized way to query property data. A typical query to get active residential listings might look simple enough on paper. You structure an OData filter to pull properties with a specific status and type. The idea is that this query should work across any RESO-compliant MLS.
That assumption will get you burned. One provider might return nested JSON objects for media links, while another returns a comma-separated string in a single field. One might enforce a strict limit of 100 results per page, while another allows 1000, forcing you to write pagination logic that adapts to the server’s mood. Error handling becomes a nightmare of parsing non-standard error messages that are often just raw server stack traces.
Here’s a conceptual Python snippet using `requests` to illustrate a basic query. The code itself is trivial. The complexity is hidden in the `normalize_listing_data` function, which is where 90% of your project’s logic and bugs will live. It becomes a massive switch-case block tailored to the idiosyncrasies of each MLS provider you support.
import requests
# This is the idealized version. Reality is much uglier.
MLS_API_BASE_URL = "https://api.some-mls-provider.org/v1/"
ACCESS_TOKEN = "your_secret_token_here"
def get_active_listings(city):
headers = {
"Authorization": f"Bearer {ACCESS_TOKEN}"
}
# OData filter for active, residential properties in a specific city
odata_filter = f"StandardStatus eq 'Active' and PropertyType eq 'Residential' and City eq '{city}'"
params = {
"$filter": odata_filter,
"$top": 100 # Max results per page
}
try:
response = requests.get(f"{MLS_API_BASE_URL}Property", headers=headers, params=params)
response.raise_for_status() # Force an exception for bad status codes
raw_data = response.json().get('value', [])
normalized_data = [normalize_listing_data(listing) for listing in raw_data]
return normalized_data
except requests.exceptions.RequestException as e:
print(f"API call failed: {e}")
# Here you'd have logic to handle rate limits, auth failures, etc.
return None
def normalize_listing_data(listing_data):
# This function is where the real "fun" begins.
# It becomes a brittle, thousand-line monster of conditional logic.
normalized = {
'id': listing_data.get('ListingKey'),
'price': listing_data.get('ListPrice') or listing_data.get('ListingPrice'), # Example of field name variance
'address': f"{listing_data.get('UnparsedAddress', '')}",
'status': listing_data.get('StandardStatus')
# ... and so on for 100+ other fields.
}
return normalized
This normalization layer is a permanent, high-maintenance fixture in your architecture. It’s a tax you pay for the industry’s failure to agree on anything meaningful.
The Transaction Black Hole: Unstructured PDFs
If the data acquisition side is broken, the transaction management side is a complete disaster. The entire process, from purchase offer to closing, runs on a river of PDF documents. Purchase agreements, addendums, inspection reports, title commitments, and closing disclosures are emailed back and forth. The “automation” here is typically a platform like DocuSign, which does little more than collect digital signatures on a static image of a document.
The critical data within these documents remains locked away. What was the final sale price? What were the seller concessions? Were there any inspection contingencies? To get these answers, someone has to manually open the PDF, read it, and key the data into another system. This is slow, expensive, and riddled with human error. We have built systems that perfectly archive evidence of a transaction without understanding a single bit of the information contained within.
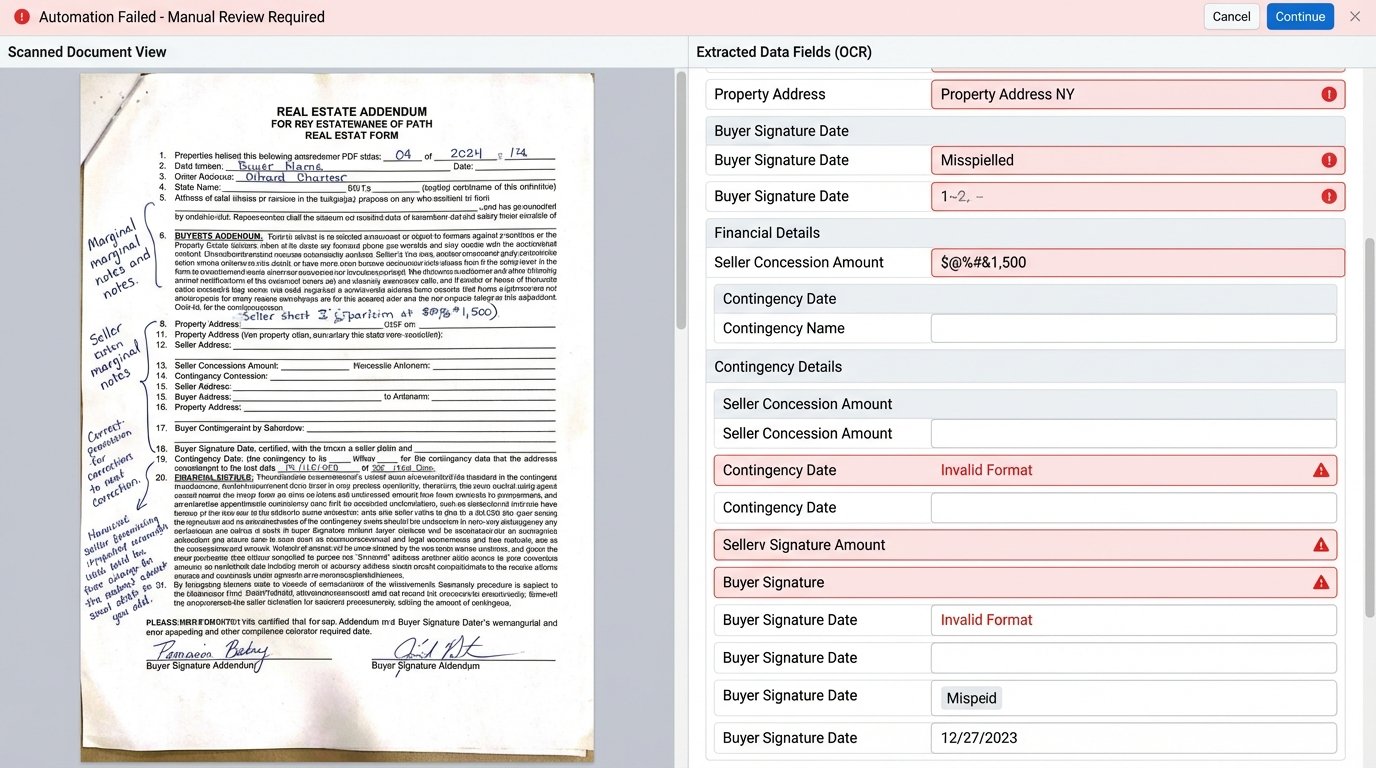
Optical Character Recognition (OCR) is often proposed as the solution. It is not. OCR is a brittle, probabilistic tool that works reasonably well on clean, machine-generated text. A scanned, faxed, or coffee-stained addendum with handwritten notes in the margin will shatter its logic. You end up with a high-cost, low-accuracy process that still requires a human to verify every single field. You’ve just replaced data entry with data correction, which is hardly progress.
The lack of a standardized, machine-readable format for transaction documents is the single greatest bottleneck to true automation in real estate.
Misguided Priorities: The Cult of the Lead-Gen Bot
Instead of fixing the foundational data problems, the industry pours capital into front-end gimmicks. The primary focus is on “lead engagement” and “agent productivity.” This translates to automated email drips, SMS bots, and AI-powered CRMs that promise to nurture leads automatically. These tools operate on the periphery of the core business process.
An AI chatbot on a brokerage website that can schedule a showing is not intelligent automation. It’s a glorified calendar form. A CRM that sends a pre-written “Happy Birthday” email is not building a relationship. It’s a cron job. These systems create an illusion of activity while doing nothing to address the structural rot in the data pipeline or the transaction workflow. We’re spending millions to optimize the window dressing on a building with a cracked foundation.
This focus is a direct result of misaligned incentives. It’s easier to sell a flashy chatbot with a slick UI than it is to sell a robust data ingestion and warehousing project. One shows immediate, visible results to a non-technical sales manager, while the other is expensive, complex, and solves problems they don’t even know they have.
The result is a fragile ecosystem of tools that fail the moment they encounter a non-standard situation.
A Sane Path Forward: Building the Plumbing
The only way out of this mess is to do the unsexy work. It involves ignoring the latest AI trends and focusing on building a solid, internal data infrastructure. This is a multi-year engineering effort, not a weekend plugin installation.
1. Internalize Your Data
Stop building your applications directly on top of third-party APIs. Treat the MLS and other external sources as hostile, unreliable inputs. Your first job is to build a resilient ingestion pipeline that pulls data from these sources into your own data warehouse. Use a message queue like RabbitMQ or Kafka to decouple the ingestion process from the normalization and storage process. This architecture allows you to handle provider outages, rate limits, and schema changes without bringing your entire system down.
Once the data is in your control, you clean it. You normalize it. You store it in a consistent, well-documented schema in a performant database like PostgreSQL or a data warehouse like BigQuery. Your applications should then query this clean, internal source of truth. This move alone eliminates a massive chunk of latency and unreliability from your stack.
2. Model Transactions as State Machines
A real estate transaction is not a collection of documents. It’s a process. A workflow. It should be modeled as such in your system. A transaction is a finite state machine that moves from `Draft Offer` to `Submitted` to `Accepted` to `Inspections` to `Pending` to `Closed` or `Cancelled`.
Each state transition should be a discrete, auditable event triggered by a specific action. The “Inspection Cleared” event can only happen when the transaction is in the `Inspections` state. This programmatic enforcement of logic prevents the chaotic, out-of-order operations that plague manual, document-driven workflows. It forces structure onto the chaos. Instead of asking “What does the PDF say?”, the system becomes the source of truth for the transaction’s current state.
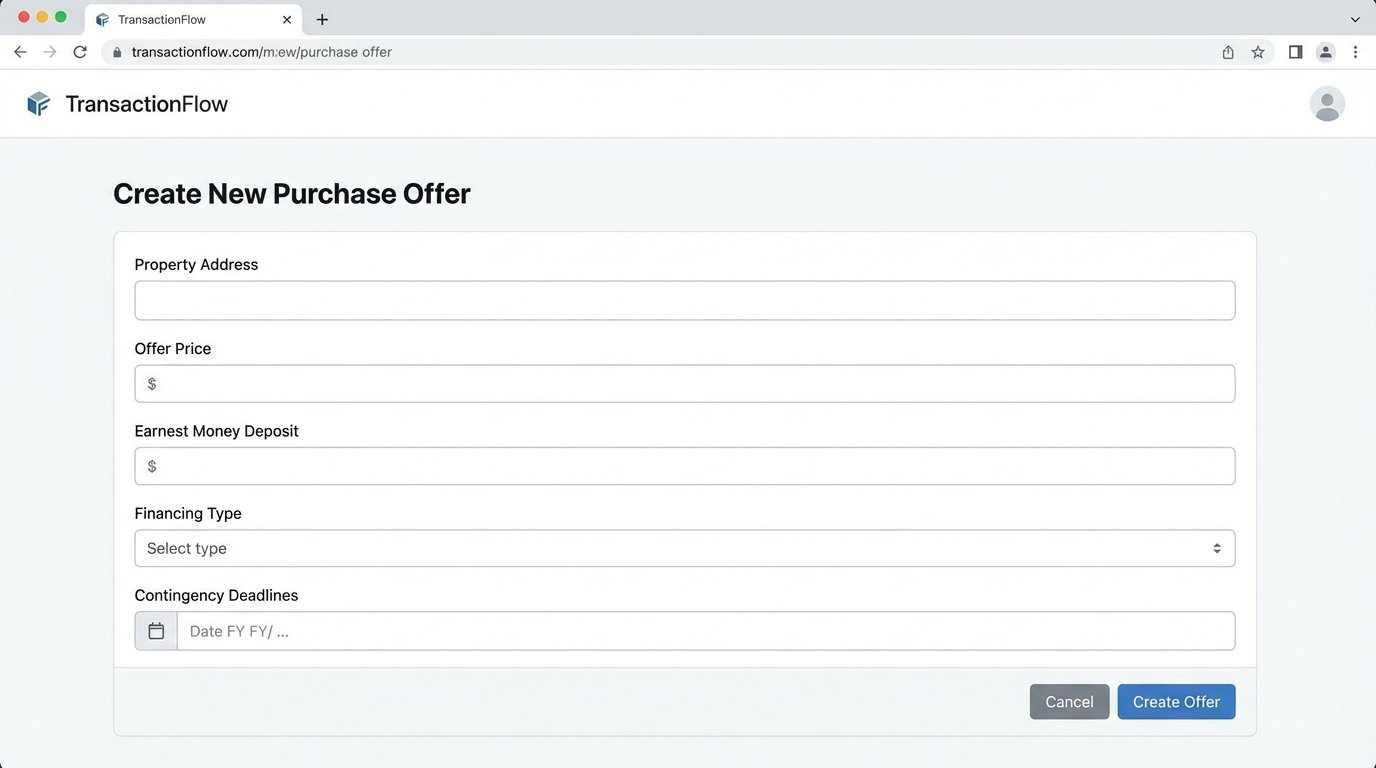
3. Push for Structured Data at the Source
Instead of trying to parse unstructured PDFs after the fact, the long-term solution is to create systems that capture structured data at the moment of creation. When an agent drafts a purchase offer, they should be using a form-based application, not a Word template. Each field, from the offer price to the contingency deadlines, is captured as a discrete data point and stored in a database. The PDF document that gets sent for signatures should be a *rendering* of this structured data, not the source itself.
This is a massive shift in thinking and requires convincing agents to change their workflows. It is a hard sell. But it is the only way to build a truly automated, data-driven transaction process. Every dollar spent on OCR technology is a dollar not spent on building the correct data capture tools.
The future of real estate automation will not be defined by the company with the smartest chatbot. It will be defined by the company that builds the most reliable and comprehensive data pipeline. It’s about owning your data, structuring your workflows, and having the engineering discipline to build the boring, essential plumbing that everyone else is ignoring.