
The Lie of the Single Source of Truth
Your inventory count is wrong. The marketing department is burning money advertising a product that the warehouse management system marked as out-of-stock two hours ago. The CRM shows a new enterprise customer just signed, but the billing platform has no record of the account. This isn’t a series of isolated glitches. These are the symptoms of a systemic failure. The root cause is data existing in disconnected islands, or silos.
Each department, from sales to logistics, bought the “best-in-class” software for their specific function. They were sold a dream of efficiency. The reality is a collection of walled gardens. The data in one system is invisible or, worse, completely contradictory to the data in another. Getting them to communicate requires manual exports to CSV files, late-night data entry, and a fleet of engineers writing brittle, point-to-point scripts that snap if an API so much as changes a field name.
This approach does not scale. It fractures.
Diagnosing the Architectural Failure
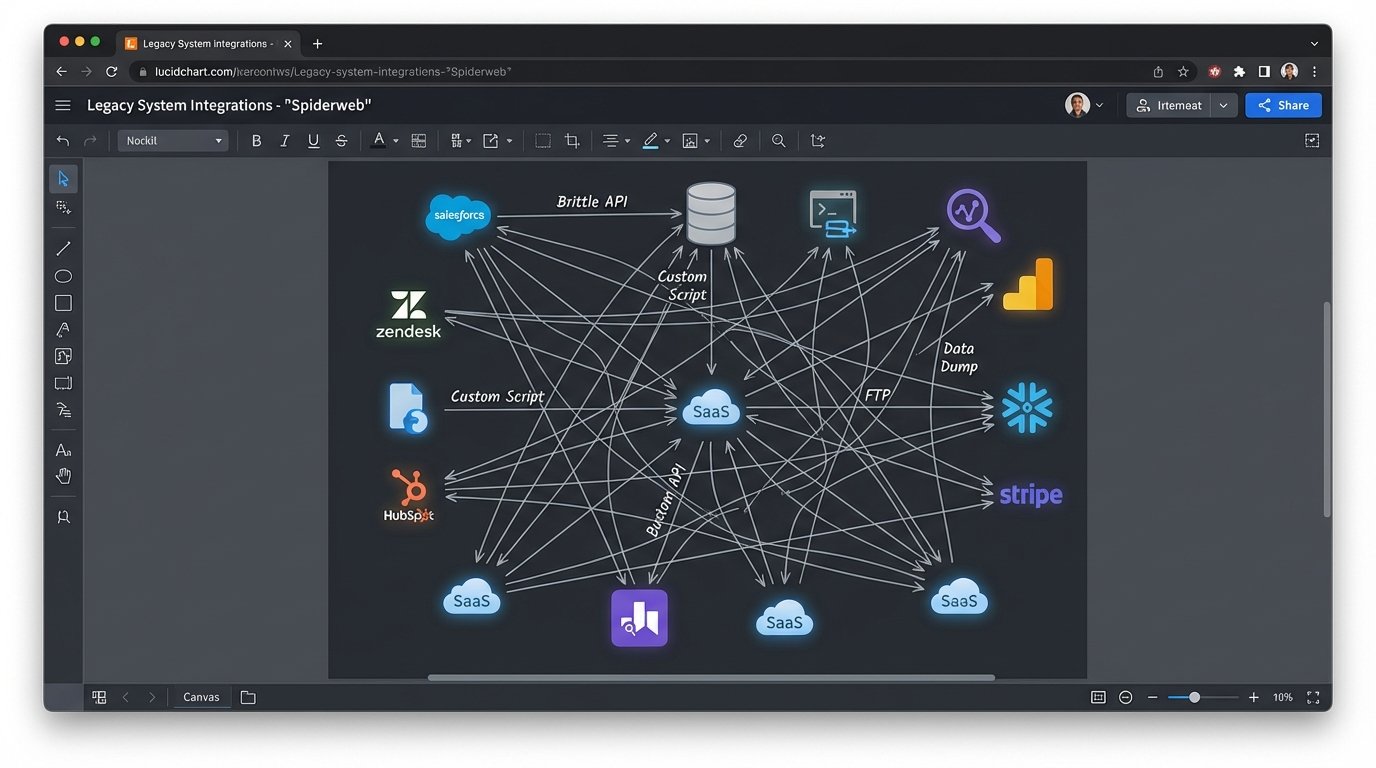
The default solution for most teams is to build direct API integrations. Sales needs data from marketing, so an engineer writes a script to pull from the marketing analytics platform and push it to the CRM. Then finance needs data from the CRM, so another script is written. This creates a spiderweb of dependencies. Each connection is a potential point of failure, and debugging a single failed transaction means tracing a signal through a dozen different systems, each with its own logging format and authentication quirks.
This point-to-point architecture is a short-term fix that creates long-term debt. Modifying one system, like upgrading the CRM, requires checking and potentially rewriting every single script that connects to it. The system becomes rigid. Engineers spend their time patching old connections instead of building new functionality. Innovation grinds to a halt under the weight of this self-inflicted complexity.
You’ve built a house of cards, and every API update is a gust of wind.
Forcing Communication: The Hub-and-Spoke Model
A more durable architecture involves a central data hub. Instead of systems talking directly to each other, they all talk to a central message broker or bus. This is the hub-and-spoke model. A system like Salesforce doesn’t need to know how to format data for your proprietary warehouse system. It just needs to know how to publish a generic “New Order Created” event to the central hub. Other systems then subscribe to the events they care about.
This decouples your services. The warehouse system can go down for maintenance without affecting the CRM’s ability to accept new orders. The orders simply queue up in the message broker, waiting for the warehouse system to come back online and process them. This broker acts as a buffer, absorbing shocks and smoothing out the inconsistencies between different services’ uptime and processing speeds.
Common tools for this job are RabbitMQ, Apache Kafka, or cloud-native services like AWS SQS/SNS or Google Pub/Sub. The choice depends on your required throughput and persistence guarantees. Kafka is a wallet-drainer to manage but offers a persistent, replayable log of events, which is critical for analytics and system recovery. SQS is simpler but operates as a pure queue. There is no perfect choice, only a correct one for the specific problem.
You’re building a central nervous system, not a tangled web.
The Data Transformation Layer
Connecting systems is only half the battle. The data itself is the real problem. The marketing platform calls a customer a “Lead” with an `email_address` field. The CRM calls them a “Contact” with an `email` field. The billing system calls them a “Client” with a `billing_email` field. A direct data transfer would fail. You need a dedicated transformation layer to mediate these differences.
This layer, often implemented as a series of serverless functions or a dedicated microservice, sits between the message broker and the destination systems. Its sole job is to ingest a message in one format, strip it down, remap its fields according to a predefined schema, and then forward it to the correct recipient in the format it expects. This is where the hard logic lives.
Forcing a canonical data model is the goal. Your organization must agree on what a “customer” object looks like, with standardized field names and data types. This is often a political fight, not a technical one. The transformation layer is the code that enforces this political agreement. It rejects malformed data and logs errors, preventing bad data from poisoning downstream systems.
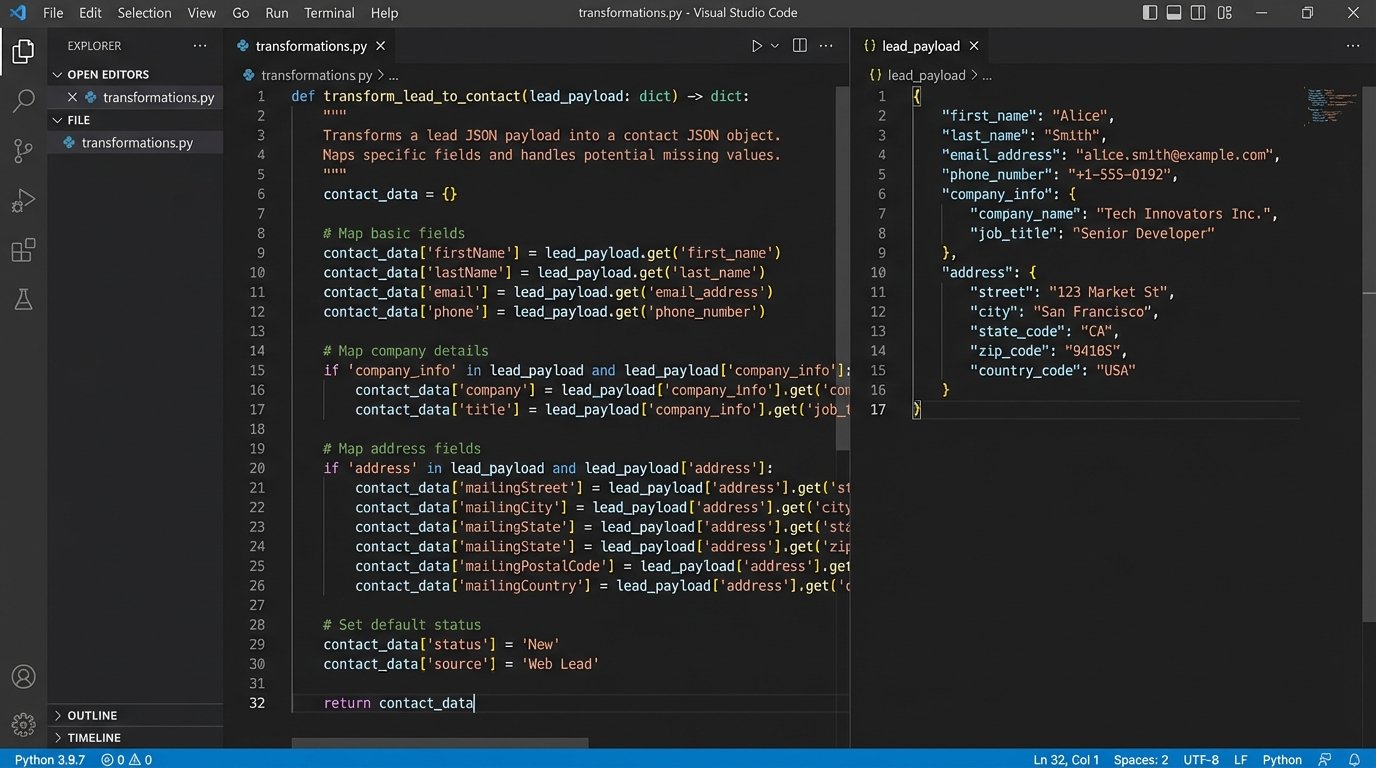
A simple Python function can illustrate this mapping logic. It’s not complex code, but its position in the architecture is critical.
def transform_lead_to_contact(lead_payload):
# Basic validation to reject garbage data early.
if not lead_payload.get('email_address') or not lead_payload.get('company_name'):
raise ValueError("Payload missing required fields for transformation.")
# The actual mapping from one system's schema to another.
contact_payload = {
'firstName': lead_payload.get('first_name', ''),
'lastName': lead_payload.get('last_name', ''),
'email': lead_payload.get('email_address'),
'company': lead_payload.get('company_name'),
'leadSource': 'Marketing Platform A',
'custom_fields': {
'lead_score': lead_payload.get('score', 0)
}
}
return contact_payload
This logic isolates the mess. When the marketing platform adds a new field, you only update this one function, not ten different point-to-point scripts.
Practical Implementation and Failure Scenarios
Theory is clean. Production is a mess. Building this kind of integrated system requires a deep focus on error handling and idempotency. What happens when your transformation function fails because of a temporary network hiccup? The message broker should be configured with a dead-letter queue (DLQ). After a certain number of failed processing attempts, the message is shunted to the DLQ for manual inspection by an engineer. This prevents a single malformed message from blocking the entire processing pipeline.
Idempotency is the principle that making the same request multiple times produces the same result as making it once. If your CRM subscriber goes down and comes back up, the message broker might redeliver the “New Order Created” event. Your system must be smart enough to recognize that order ID and not create a duplicate. This can be handled by checking for the existence of a record with a unique transaction ID before creating a new one.
Failure to design for idempotency is how you end up double-billing customers and shipping duplicate orders.
Monitoring and Observability
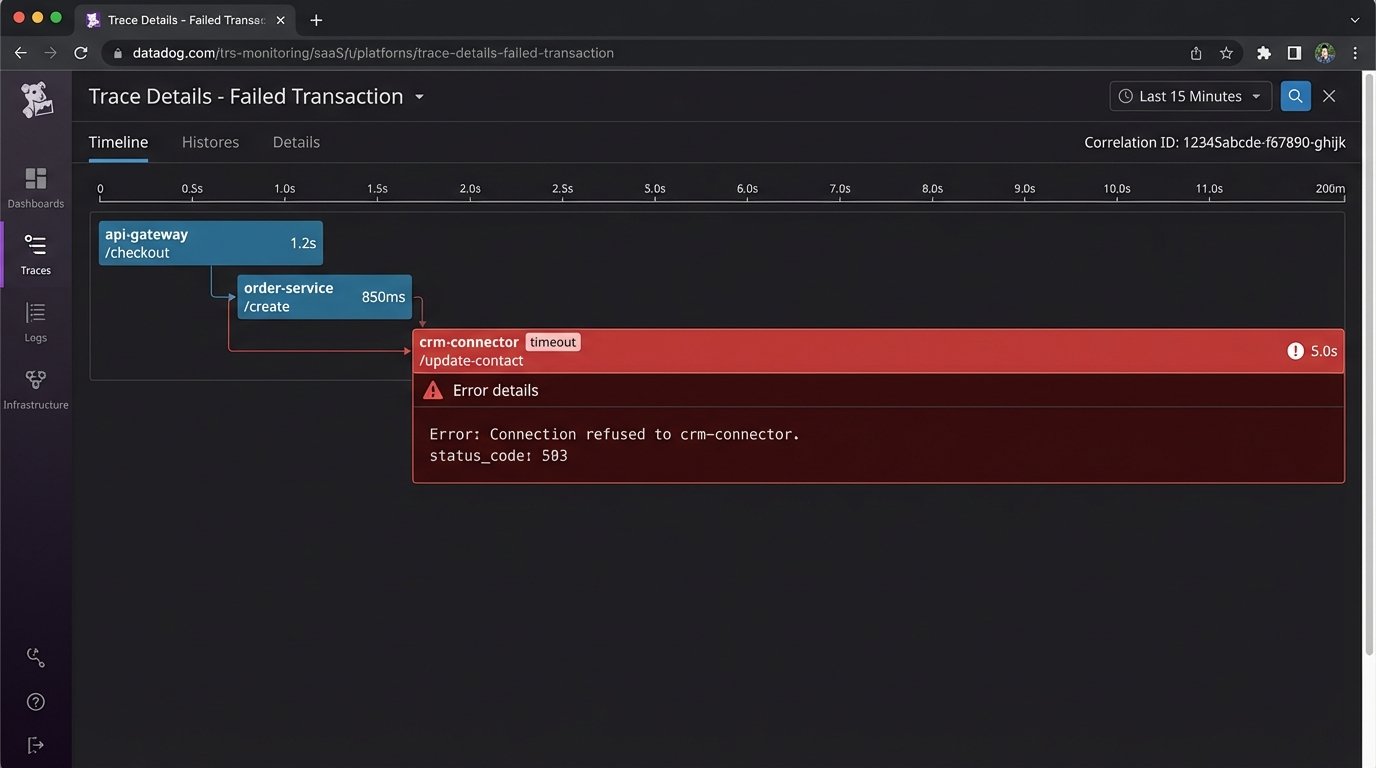
A decoupled system is harder to debug than a monolith. You cannot simply read a single log file to trace a request. A transaction might pass through five different services before it’s complete. This requires structured logging and distributed tracing. Each service must log events with a shared correlation ID that ties them all back to the original request.
Tools like Datadog, New Relic, or open-source solutions like Jaeger are essential. They ingest logs and traces from all your services and stitch them together, giving you a visual map of a request’s journey through the system. Without this, you are flying blind. You will spend hours trying to figure out why a message that was published successfully never made it to its final destination.
This isn’t an optional add-on. It’s a fundamental requirement for operating a distributed architecture.
The Real Cost of Connection
Connecting everything is not a one-time project. It is a fundamental shift in how you build and maintain software. It requires upfront investment in infrastructure, whether that’s managing your own Kafka cluster or paying for cloud services. The message broker itself becomes a critical piece of infrastructure, a single point of failure that requires its own monitoring, scaling, and maintenance plan.
The biggest cost is often organizational. It forces different teams to agree on shared data models and API contracts. It demands a level of cross-team collaboration that may not exist. A marketing team cannot just change a field name in their platform’s API output without breaking the contract and causing downstream failures. This requires discipline and communication.
Breaking down data silos is less about writing code and more about breaking down organizational silos. The technology just forces the conversation.