
The Problem: A Cesspool of Marketing Acronyms and API Inconsistencies
The real estate tech ecosystem is a fragmented mess. Agents are told to build a “stack” from dozens of vendors, each with its own proprietary language designed for sales, not for interoperability. The result is a pile of tools that actively resist integration. A “Hot Lead” in one CRM is a “Prospect with High Engagement” in another, and a “7-Star Contact” in a third. These are not technical terms. They are marketing slogans embedded directly into data models.
This creates a fundamental failure in data integrity. An agent cannot compare performance metrics between two systems because the underlying definitions are fluid. They spend thousands on tools that promise efficiency but deliver data chaos. The problem extends beyond the user interface and directly into the API layer, where the inconsistency is codified. You pull a contact record from two different systems and get two completely different object structures for what is logically the same entity.
We see JSON payloads where an address is a single, unformatted string. Another system provides a structured object with separate fields for street, city, and zip. This lack of a common data model makes simple automation a nightmare. Trying to sync data between these platforms using off-the-shelf connectors like Zapier becomes an exercise in futility, filled with brittle, multi-step filters and formatters that break the moment a vendor pushes a minor API update. This isn’t a user training issue. It’s a systems integration failure.
The Fix Architecture: Building a Jargon Normalization Engine
The solution is not another glossary or a training manual. The solution is to build a translation and normalization engine that acts as a middleware layer. This system’s sole purpose is to ingest data from various sources, strip the vendor-specific terminology, and map everything to a rigid, standardized internal schema. It is a sanitation pipeline for data that forces a single source of truth, regardless of how many vendors are plugged into it.
This engine is constructed from three primary components that work in sequence. Each part has a specific function: get the data, clean the data, and present the data in a format a human can actually use for decision-making. The entire architecture is designed to abstract away the chaos of the source systems.
Component 1: The Ingestion Layer
First, you need connectors to pull data from the source APIs. This means dealing with a circus of authentication protocols. You will handle OAuth2 for modern CRMs, simple API keys for older platforms, and bearer tokens for others. Each connector must be built to handle the specific rate limits and pagination logic of its target API. Documentation is often outdated or outright wrong, so a significant amount of this work is trial-and-error discovery against live endpoints.
The goal here is simple acquisition. The connector fetches the raw, unfiltered data and dumps it into a staging area, usually a message queue or a temporary database table. It does not attempt to interpret the data yet. Its only job is to get the data inside your environment reliably, with robust logging to track API failures, timeouts, and rate limit exceptions.
Here is a typical, messy JSON object you might pull from a hypothetical real estate CRM. Notice the vague field names and inconsistent data types.
{
"contact_id": "c_98765f",
"lead_first_name": "Jane",
"lead_last_name": "Doe",
"info": "Came from Zillow inquiry on 123 Main. Seems hot.",
"contact_quality_score": "9.2",
"last_contacted_unixtime": 1678886400,
"property_interest": ["pid_abc1", "pid_def2"],
"full_address": "456 Oak Avenue, Anytown, USA 12345"
}
Component 2: The Parsing and Mapping Core
This is where the actual work happens. The engine takes the raw JSON from the ingestion layer and forces it into a predefined, canonical data model. This model is your internal standard for what a “contact” or a “property” object should look like. You define it once, and every piece of data from every source system is hammered into this shape. The process involves a mapping dictionary, a configuration file that acts as a Rosetta Stone between vendor fields and your internal schema.
For example, the mapping logic would specify that `lead_first_name` from CRM A and `FirstName` from CRM B both map to your canonical `contact.firstName` field. It would translate `contact_quality_score` into a standardized `engagement_metric` field, possibly converting a string to a float in the process. This is the brute-force translation that removes all ambiguity. It is the core of the entire system, functioning like a universal data adapter that takes dozens of incompatible inputs and produces one standard output.
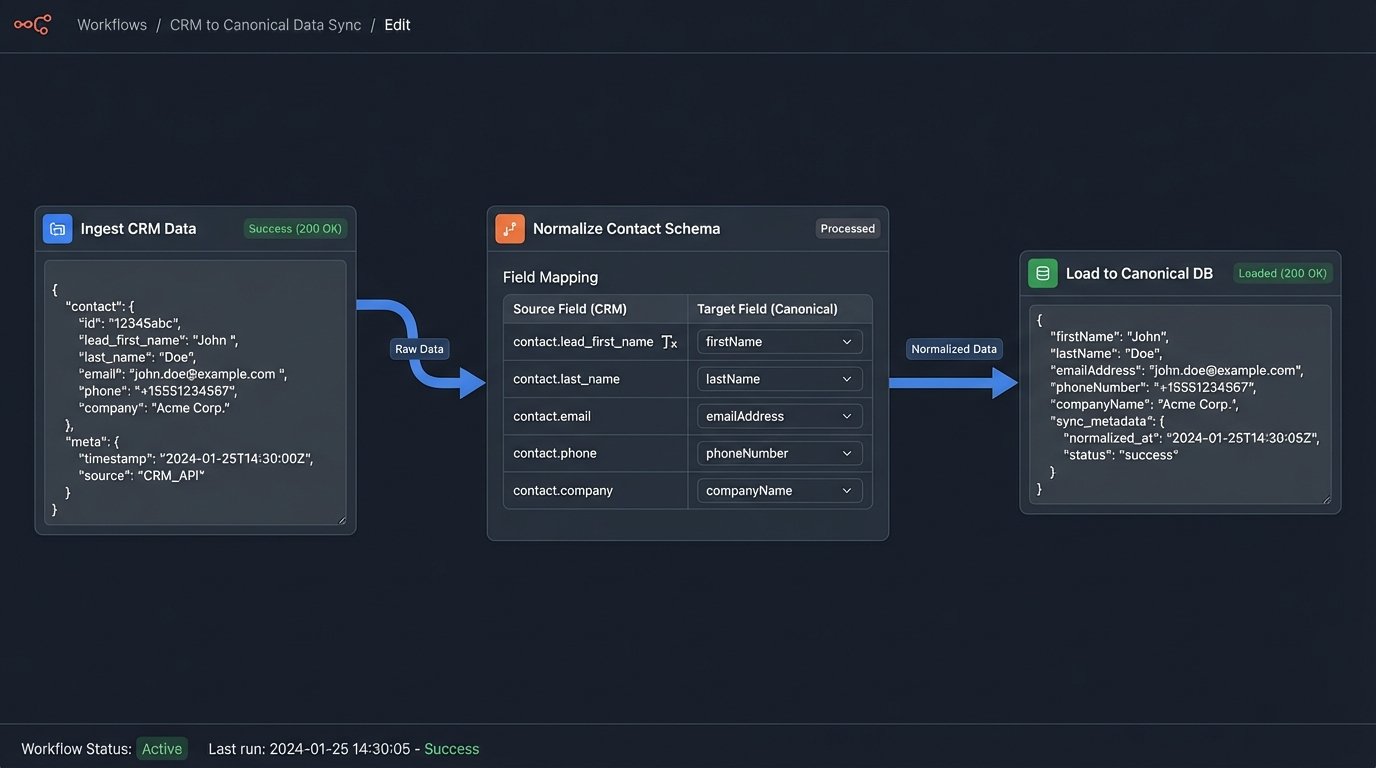
This component also handles data type coercion and basic validation. It ensures that a date is always in ISO 8601 format, an address is always a structured object, and required fields are never null. Any record that fails this validation gets flagged and shunted to an error queue for manual review. You do not let bad data pollute your clean system.
Component 3: The Presentation Layer
Once the data is normalized, it needs to be stored in a production database and exposed to the end-users, the agents. This is typically done through a simple, internal dashboard or by feeding the clean data back into a single, designated CRM that acts as the primary user interface. The agents never see the raw data from the source systems. They only ever interact with the clean, standardized version.
The result is clarity. Instead of five different “lead scores” with opaque calculations, the agent sees one `Engagement Score` with a clear, documented definition. Lead sources are not listed as “Zillow Premier Agent” or “Realtor.com Connection,” but are normalized to a simple `Source: Portal` with `SourceDetail: Zillow`. This allows for true apples-to-apples comparison of lead source effectiveness and agent follow-up performance.
Practical Implementation: A Step-by-Step Breakdown
Building this engine requires a disciplined approach. It is not a single piece of software but a series of connected scripts and services that execute in a specific order. The complexity lies not in the code itself, but in the detailed mapping and rigorous schema definition.
Step 1: Defining the Canonical Schema
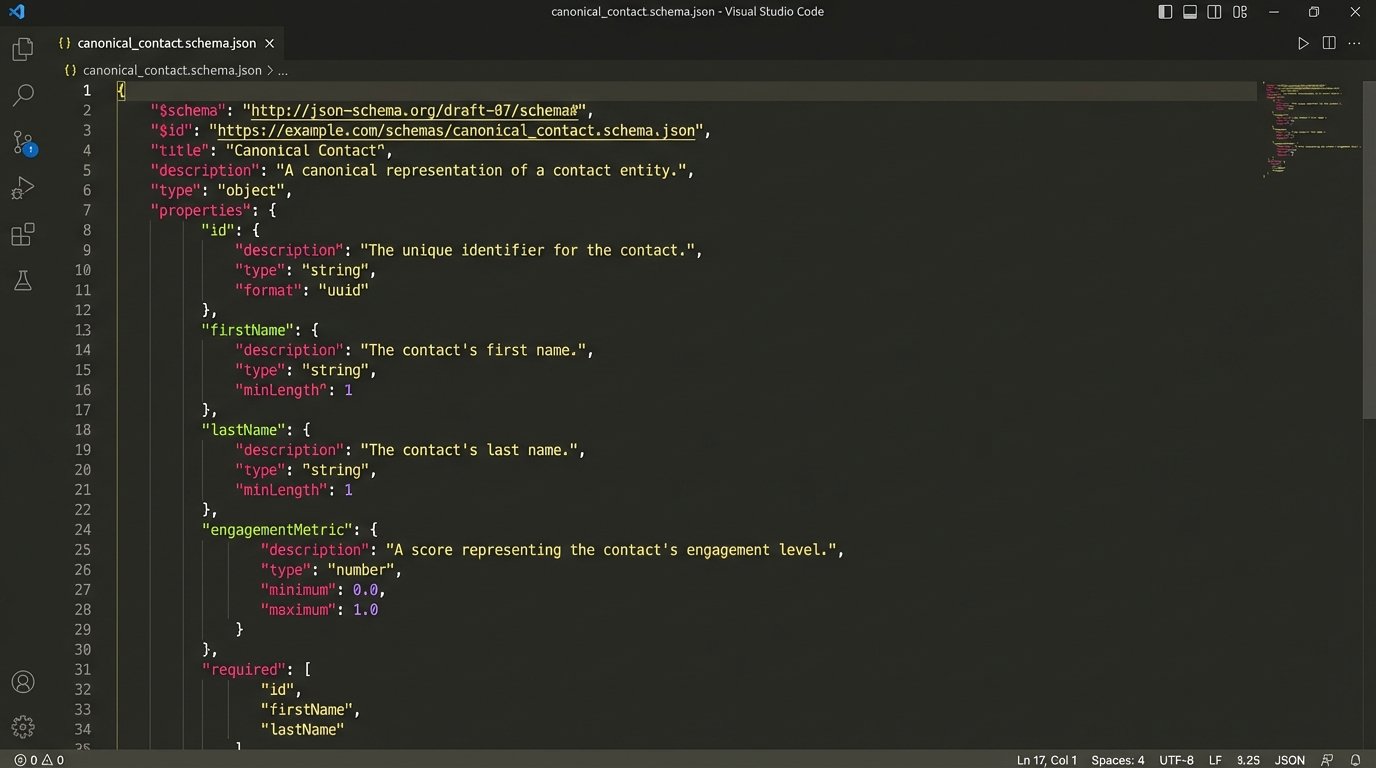
Before writing a single line of code, you must define your internal data model. This is the most critical step. You must decide what are the core entities in your business (Contact, Property, Listing, Transaction) and what specific attributes each entity must have. This schema should be documented using a format like JSON Schema to enforce structure and data types.
A canonical schema for a `Contact` object forces standardization. Every field has a clear purpose and a strict data type. This is your single source of truth.
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "CanonicalContact",
"type": "object",
"properties": {
"id": { "type": "string", "format": "uuid" },
"firstName": { "type": "string" },
"lastName": { "type": "string" },
"email": {
"type": "array",
"items": {
"type": "object",
"properties": {
"address": { "type": "string", "format": "email" },
"isPrimary": { "type": "boolean" }
},
"required": ["address", "isPrimary"]
}
},
"engagementMetric": { "type": "number", "minimum": 0, "maximum": 100 },
"sourceSystem": { "type": "string" },
"sourceSystemId": { "type": "string" },
"createdAt": { "type": "string", "format": "date-time" }
},
"required": ["id", "lastName", "sourceSystem", "sourceSystemId"]
}
Step 2: Building the API Connectors
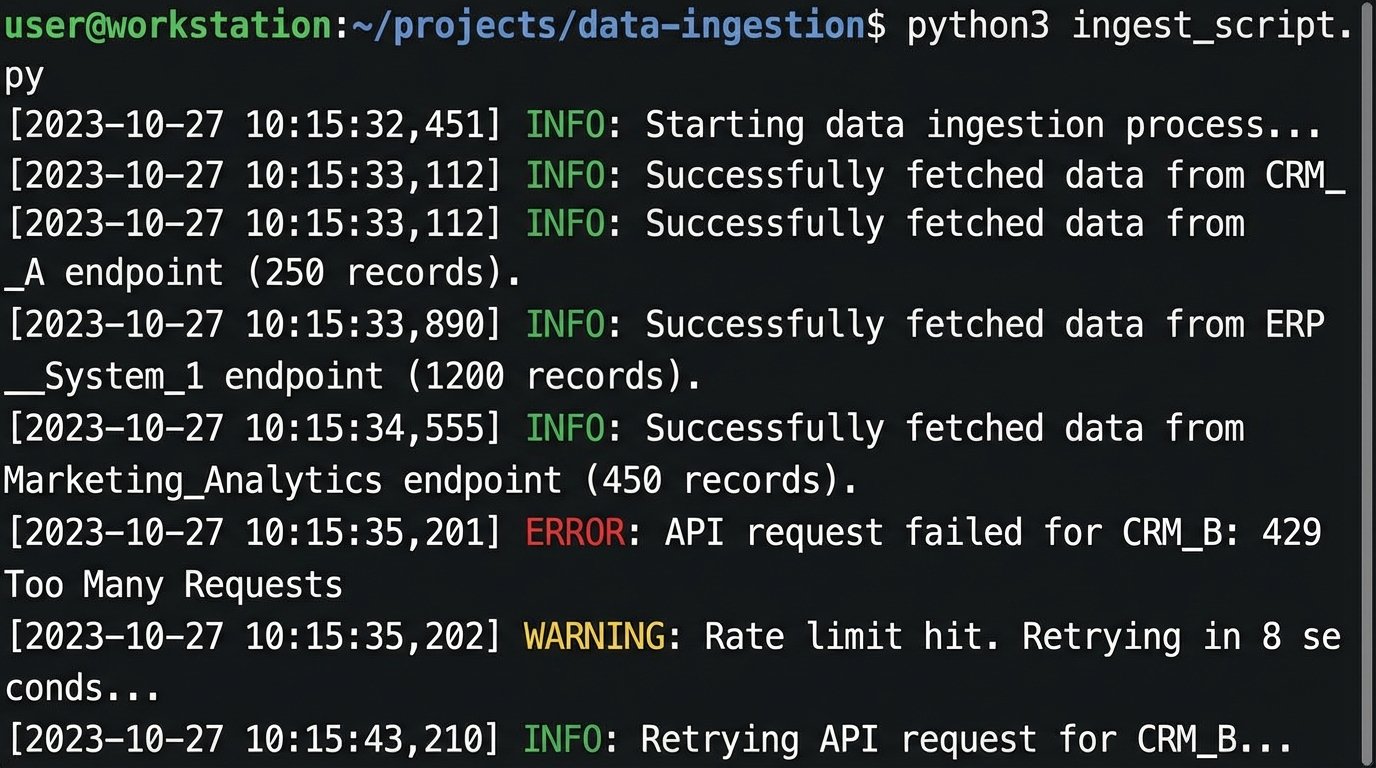
With a schema defined, you can build the connectors. Python is a solid choice for this, using libraries like `requests` for HTTP calls and `Pydantic` for data validation against your schema. A key part of each connector is its error handling logic. APIs will fail. They will hit rate limits. Your code must anticipate this. Implement an exponential backoff strategy for retrying failed requests, especially for 429 (Too Many Requests) and 5xx server error responses.
This is not a place for complex logic. The connector’s job is to fetch and pass through. All transformation happens later. This separation of concerns makes the system much easier to debug when a specific vendor’s API inevitably breaks.
import requests
import time
def fetch_data_from_crm(api_key, page_number):
url = f"https://api.somecrm.com/v2/contacts?page={page_number}"
headers = {"Authorization": f"Bearer {api_key}"}
max_retries = 5
base_delay = 1 # in seconds
for attempt in range(max_retries):
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status() # Raises an exception for 4xx/5xx errors
return response.json()
except requests.exceptions.RequestException as e:
if response.status_code == 429:
delay = base_delay * (2 ** attempt)
print(f"Rate limit hit. Retrying in {delay} seconds...")
time.sleep(delay)
else:
print(f"Request failed: {e}. Attempt {attempt + 1} of {max_retries}.")
if attempt == max_retries - 1:
raise # Re-raise the last exception
return None
Step 3: The Mapping Logic
The mapping can be managed in a simple configuration file, like YAML or JSON. This decouples the transformation logic from the application code, making it easier for non-developers to update mappings as APIs change. The parser reads this configuration and applies the transformations dynamically.
Each mapping entry specifies the source system, the path to the source field, and the path to the target field in your canonical model. It can also include rules for data type conversion or value mapping.
{
"crm_a_mappings": {
"contact_id": "sourceSystemId",
"lead_first_name": "firstName",
"lead_last_name": "lastName",
"contact_quality_score": {
"target": "engagementMetric",
"transform": "toFloat"
}
},
"crm_b_mappings": {
"id": "sourceSystemId",
"fName": "firstName",
"lName": "lastName",
"activity_rating": {
"target": "engagementMetric",
"transform": "scale",
"params": [0, 10, 0, 100] // Scale from 0-10 range to 0-100
}
}
}
The Unavoidable Trade-Offs and Failure Points
This architecture is effective, but it is not magic. It comes with its own set of operational costs and challenges. Anyone promising a perfect, maintenance-free integration system is selling a fantasy. The reality is a series of calculated compromises.
Data Fidelity vs. Speed. A highly detailed canonical model preserves more information but requires more complex transformation logic. This slows down data synchronization. A simpler, flatter model is much faster to process but inevitably loses some of the nuanced data from the source system. You have to decide if capturing a niche custom field from one CRM is worth the added processing time for every record.
Maintenance Overhead. This is the biggest hidden cost. API vendors change their schemas. They deprecate endpoints. They do this with little to no warning. When they do, your connectors and mapping logic will break. This system is not a one-time project. It requires ongoing monitoring and maintenance from at least one engineer. It is a recurring operational expense, not a capital investment.
The “Garbage In, Garbage Out” Principle. Your normalization engine can standardize formats, but it cannot fix fundamentally bad data. If an agent enters a contact’s name in all lowercase in one system and as an email address in another, the engine cannot magically intuit the correct name. Fixing data quality requires a separate, and often more complex, entity resolution and data cleansing process. This pipeline only sanitizes the structure, not the content.
Adoption Hurdles. The final barrier is human. Agents who have spent years looking at a “Hotness Score” from their preferred CRM may resist a new, standardized “Engagement Metric.” The technical solution is only half the battle. The other half is forcing adoption and demonstrating that the standardized view provides more value than the familiar but chaotic collection of vendor-specific reports.
From Jargon to Actionable Intelligence
The entire point of this architecture is to force clarity. It rips away the marketing language embedded in software and exposes the underlying data. This enables a brokerage to build a unified view of their entire business, from lead generation to transaction closing. It makes it possible to calculate true ROI on technology and marketing spend.
This approach transforms a collection of disconnected data silos into a coherent data asset. It allows for genuine business intelligence instead of a folder full of conflicting CSV exports. Building this is less about clever code and more about the brute-force discipline of standardizing chaos.