Data drift between a Multiple Listing Service and a Customer Relationship Management system is not a possibility. It is an inevitability. Every hour they are disconnected, a chasm grows. Your CRM tells agents a property is active while the MLS shows it as pending. Your marketing automation fires emails about a property that had a price change yesterday. This is not a hypothetical problem. It’s a resource drain that manifests as wasted ad spend and agents calling on dead leads.
The standard, flimsy fixes are manual CSV imports or using off-the-shelf connectors that promise a “seamless” experience. Those connectors are black boxes. When they break, and they will, you have no visibility, no logs, and no control. You are left filing a support ticket while your data rots. The only durable solution is to build a dedicated API bridge that you control. It is not simple, but it is deterministic.
Deconstructing the Failure State
The core problem is attempting to synchronize two systems that were never designed to speak to each other. Each has its own schema, its own update cadence, and its own definition of what constitutes a single piece of data. Relying on a human to manually export and import data between them is a guaranteed failure point. The process is slow, error-prone, and forgotten the moment a key employee goes on vacation.
The MLS API Labyrinth
Accessing MLS data programmatically is a fractured experience. The older Real Estate Transaction Standard (RETS) is still depressingly common. It functions more like a glorified FTP server with a query language bolted on than a modern API. You are often forced to download massive datasets and then parse them locally to find the changes. It is sluggish and a massive resource hog on both ends.
The newer RESO Web API is a significant improvement, built on OData and REST principles. It offers standardized resources and filtering. Even so, implementations vary wildly between MLS providers. Authentication can be a project in itself, wrestling with OAuth2 flows, short-lived bearer tokens, and refresh logic. The documentation is frequently outdated, forcing you to discover endpoints and data fields through trial and error.
CRM API Constraints are Non-Negotiable
CRM APIs present their own set of walls. The most immediate one is rate limiting. A naive script that attempts to pull 50,000 listings from the MLS and push them all to the CRM will get its IP address blocked. You must respect the `X-Rate-Limit-Remaining` header, or you will be shut out. A typical limit might be 10 requests per second, a ceiling you hit very quickly during an initial data load.
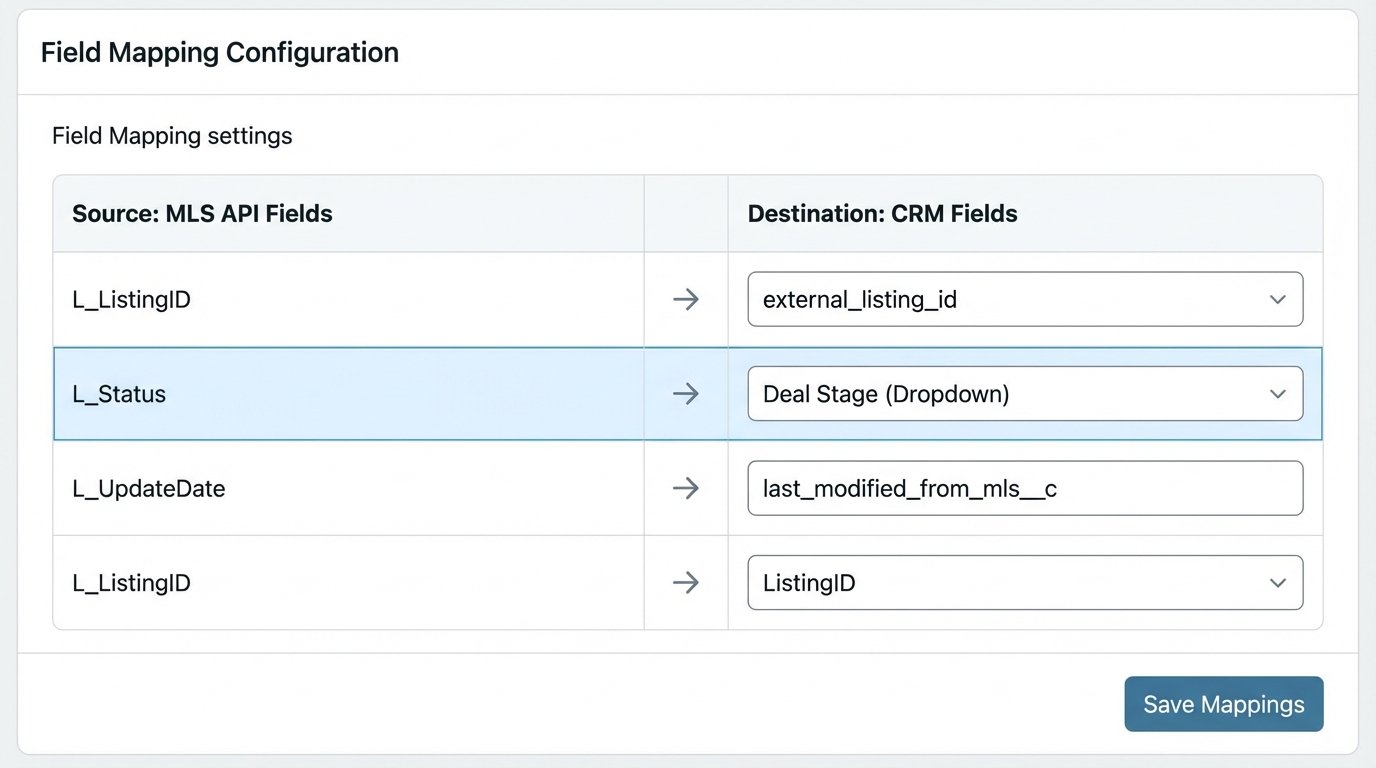
Field mapping is the next major headache. The MLS has hundreds of standardized fields like `L_ListingID`, `L_Status`, and `L_UpdateDate`. Your CRM has “Deals”, “Contacts”, and a mess of custom fields created by the sales team. You must write a rigid translation layer to map `L_Status` ‘A’ to the CRM deal stage “Active Listing”. Without this, you are just injecting unstructured garbage into your sales pipeline.
Architecting the Fix: A Stateful Middleware Bridge
A simple cron job running a Python script is not the answer. That is a stateless approach that fails to track what has already been synced. You end up re-processing the same records repeatedly, burning through API quotas and compute cycles. The correct architecture is a stateful middleware service. This is a dedicated application that sits between the MLS and the CRM. Its sole purpose is to manage the flow and transformation of data.
This service needs its own persistence layer. A simple Redis cache or a small PostgreSQL database works. This database does not store the full MLS dataset. It stores the mapping between the MLS record’s unique ID and the corresponding record’s ID in the CRM. It also stores the timestamp of the last successful sync for each record. This stateful knowledge is what allows you to build an efficient, delta-only synchronization process.
Sync Strategy: One-Way Flow is Your Default
The temptation to build a two-way sync is strong. It is also where most of these projects collapse. A two-way sync introduces complex conflict resolution problems. What happens if an agent updates the price in the CRM at the same time the price is updated in the MLS? Which is the source of truth? Last-write-wins is a crude strategy that often destroys valid data. Trying to force a two-way sync without a dedicated conflict resolution engine is like having two developers editing the same file on separate machines without version control. The final result is a corrupted mess.
Start with a one-way sync: MLS to CRM. The MLS is the undisputed source of truth for property data. The middleware polls the MLS for changes, transforms the data, and pushes it to the CRM. The flow is unidirectional and predictable. This handles 90% of the business requirements without the catastrophic risk of data corruption.
The Data Transformation Engine
This is the core of the middleware. It is a set of functions responsible for cleaning and reshaping the data from the MLS format into the structure the CRM expects. This is not a simple one-to-one field copy. It is a deliberate process of data sanitation.
You must perform three key operations:
- Mapping: Define a rigid dictionary or configuration file that maps source field names to destination field names. `MLS.ListingKey` becomes `CRM.external_listing_id`. This mapping must be meticulously maintained.
- Normalization: Standardize data formats. Convert all dates to ISO 8601. Strip HTML and non-ASCII characters from property descriptions. Force phone numbers into a consistent E.164 format.
- Enrichment: Sometimes you need to add data that does not exist in the source. For example, constructing a full property URL in the CRM using the listing ID and a predefined base URL.
Here is a simplified Python example of a mapping and transformation function. It is not production code, but it illustrates the logic.
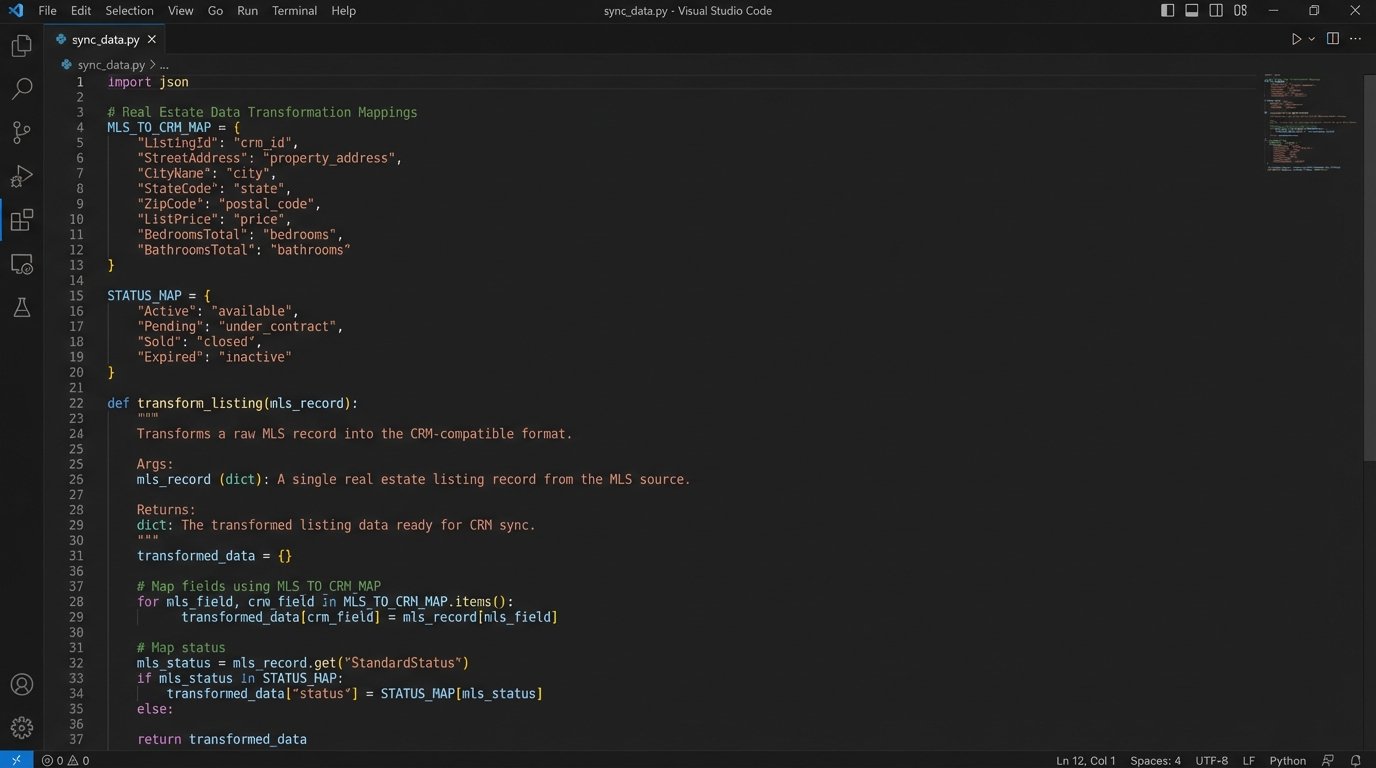
MLS_TO_CRM_MAP = {
'ListingKey': 'external_listing_id__c',
'ListPrice': 'amount',
'StandardStatus': 'deal_stage',
'ModificationTimestamp': 'last_modified_from_mls__c'
}
STATUS_MAP = {
'Active': 'Prospecting',
'Pending': 'Contract Sent',
'Closed': 'Closed Won',
'Expired': 'Closed Lost'
}
def transform_listing(mls_record):
"""
Transforms a raw MLS record into a CRM-ready dictionary.
Returns None if the record is invalid.
"""
crm_payload = {}
for mls_key, crm_key in MLS_TO_CRM_MAP.items():
if mls_key in mls_record:
# Specific transformation logic for status
if mls_key == 'StandardStatus':
crm_payload[crm_key] = STATUS_MAP.get(mls_record[mls_key], 'Unknown')
else:
crm_payload[crm_key] = mls_record[mls_key]
# Logic-check for essential fields
if not crm_payload.get('external_listing_id__c'):
# Log an error, this record is useless without a unique ID
return None
return crm_payload
This code explicitly defines the relationships and handles a specific business rule for mapping statuses. Every field with a potential mismatch needs this level of deliberate handling.
Implementation Details That Will Break Production
The high-level architecture is one thing. The gritty details are what determine if the system runs or crashes at 3 AM. Several areas require obsessive attention.
Idempotency is a Requirement, Not a Feature
Your data insertion and update logic must be idempotent. This means that if you send the same update payload five times in a row due to a network glitch or a retry loop, it has the exact same effect as sending it once. It should not create five duplicate records. The standard way to enforce this is to use the MLS listing’s unique identifier as an external key in your CRM. Your logic should always be “UPSERT”: update the record if this external key exists, otherwise insert a new one.
Webhooks Beat Polling
Polling is brute force. You ask the MLS API “anything new?” every five minutes. This is inefficient and slow to propagate changes. Many modern RESO Web APIs support webhooks. This inverts the model. The MLS tells you when a record changes by sending a notification to an endpoint you control. This is an event-driven approach. It is vastly more efficient and provides near real-time updates.
The architecture shifts significantly. Instead of a cron job, you have a persistent web server (like Flask or FastAPI) with an endpoint dedicated to receiving these webhooks. This endpoint receives the payload, validates its authenticity, and then queues a job to process the specific update. This is surgically precise compared to the sledgehammer of polling the entire database.
Error Handling and Observability
APIs fail. Networks drop packets. Your code must be built with this assumption. Every external API call must be wrapped in a retry mechanism, preferably with exponential backoff. A failed call should not terminate the entire sync process. It should be logged, and the system should move on to the next record.
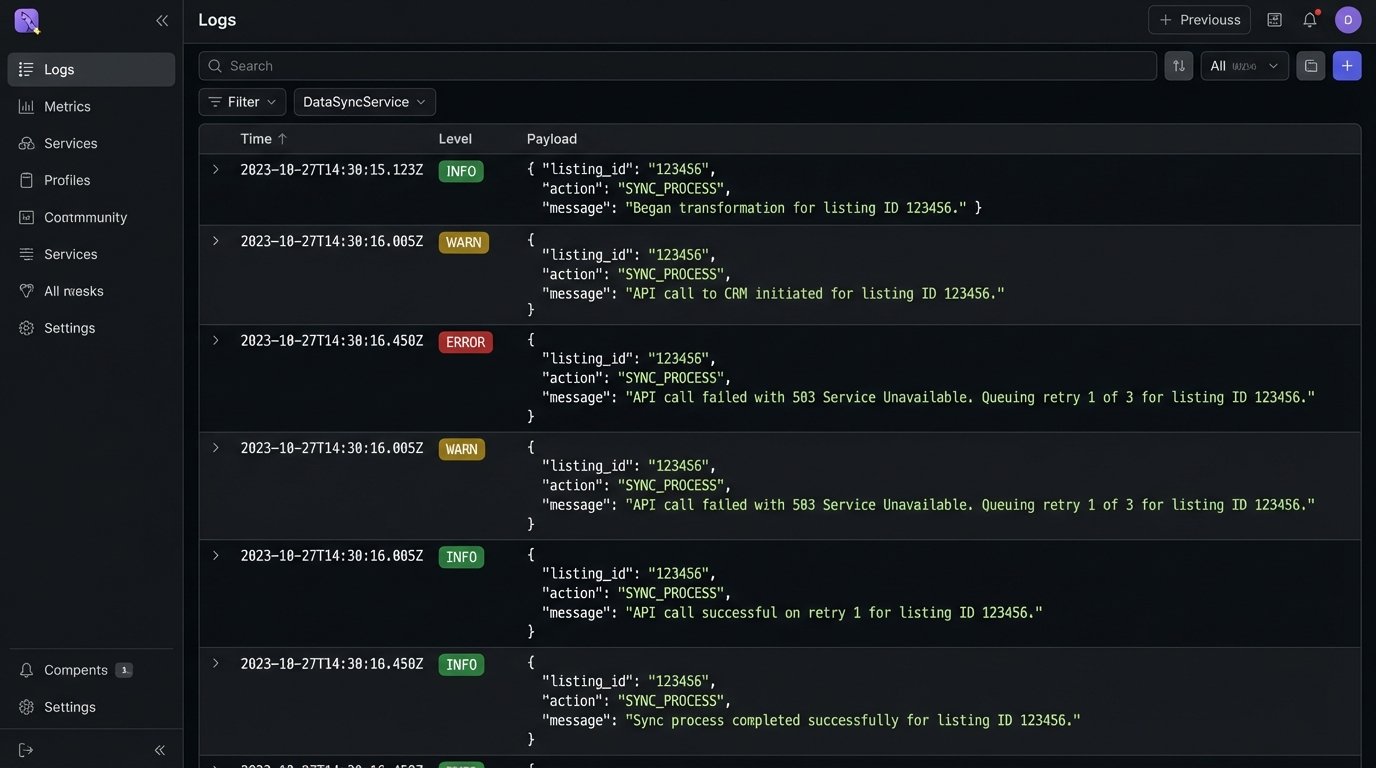
Logging cannot be an afterthought. You need structured logs (JSON format is ideal) for every stage of the process.
- Received webhook from MLS for Listing ID 12345.
- Began transformation for Listing ID 12345.
- API call to CRM to update Deal ID 67890 initiated.
- API call failed with 503 Service Unavailable. Queuing retry 1 of 3.
- API call successful on retry 1.
Without this level of granularity, debugging is impossible. You are flying blind. When an agent claims their listing is out of date, you must be able to trace its entire lifecycle through your system logs to identify the exact point of failure.
Building this bridge is a serious engineering effort. It is not a task for an intern or a low-code platform. It requires infrastructure, monitoring, and ongoing maintenance as the source and destination APIs evolve. The alternative, however, is to accept data chaos as a standard business practice. The cost of building a stable, observable integration is high. The cost of operating a business on bad data is higher.