
The Old System Was Leaking Value
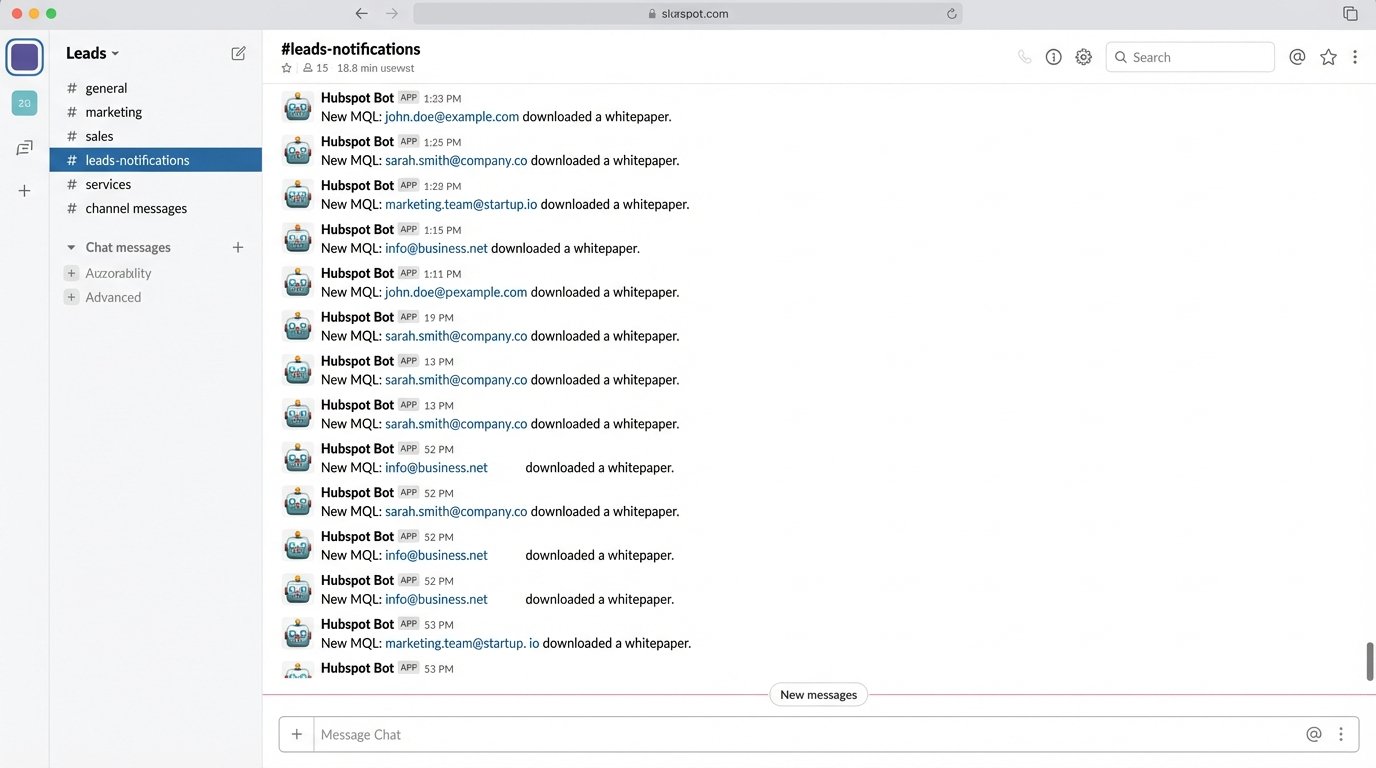
Our lead pipeline was a joke. Marketing celebrated MQLs based on PDF downloads, while the sales team chased ghosts. The core problem was a disconnected stack built on hope and Zapier automations that broke if someone looked at them sideways. We had Hubspot for marketing, Salesforce for sales, and product usage data locked away in a production Postgres database that the data science team guarded like a dragon.
Every “lead” was an island of information, and bridging the gaps required manual CSV exports and VLOOKUPs. It was slow, error-prone, and fundamentally dishonest about user intent.
The system forced sales reps to operate blind. They received a notification that “john.doe@example.com downloaded the Q3 whitepaper” with zero context. Did John’s company already have three open support tickets? Was his team actively using a competing product? Did he log into our free trial two minutes ago and trigger five key activation events? Nobody knew. The data existed, but it was in separate, locked rooms.
This technical debt created a political one, with marketing and sales pointing fingers while revenue targets were missed.
Defining the Failure Point
The central failure was our definition of a “lead.” It was event-based, not behavior-based. A single action, like a form submission, triggered a sequence of clumsy hand-offs. We were measuring digital body language one twitch at a time instead of interpreting the whole conversation. This is like trying to understand a novel by reading one random word from each page.
The result was a firehose of low-quality alerts that trained the sales team to ignore them. We weren’t just inefficient; we were actively burning our most expensive resource, a salesperson’s time, on garbage data.
Gutting the Old Plumbing
We didn’t need to optimize the old system. We needed to throw it in the dumpster. The goal was to build a single, unified view of a customer that tracked their entire journey, from anonymous website visitor to power user. This required a completely different architecture, one that treated data as a fluid asset, not a static record locked in an application silo.
The new stack had to do three things exceptionally well: ingest data from anywhere, model it centrally, and push actionable intelligence back into the tools our teams already used.
Component One: The Universal Data Collector
First, we had to stop letting our applications hold data hostage. We used Segment to act as a universal data collector. We ripped out the native tracking scripts for Google Analytics, Hubspot, and our various ad platforms. We replaced them with a single Segment tracking plan. All website clicks, form fills, and backend server events were piped through one API.
This immediately decoupled our data collection from our marketing tools. We could now send the same clean, validated event stream to any destination without writing new code on the front end. It’s the data equivalent of installing a central circuit breaker panel instead of wiring every appliance directly into the grid.
Component Two: The Central Brain
All that clean data from Segment was routed directly into a Snowflake data warehouse. Storing raw event data is cheap. The real cost, and the real value, comes from compute. Having everything in one place gave us the power to join website behavior with product usage data and Salesforce records to build a complete identity profile.
This is where the heavy lifting happened. We used dbt to transform the raw, event-level data into clean, aggregated models. We built tables for `users`, `accounts`, `daily_product_activity`, and more. dbt let us write modular, testable SQL, turning the messy art of data transformation into a disciplined engineering practice. No more 500-line SQL queries passed around in a text file.
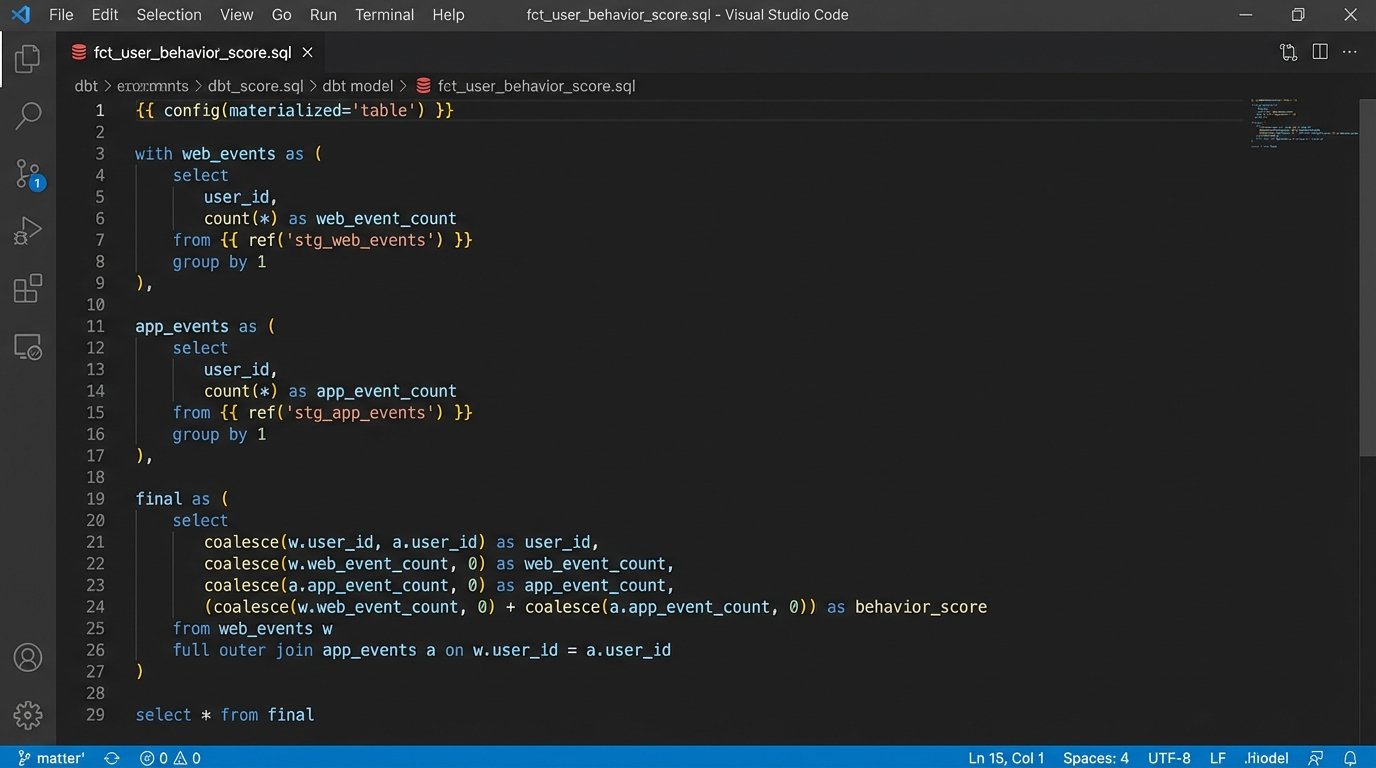
Here is a simplified example of a dbt model that calculates a user’s weekly activity score. It joins web events with in-app actions to create a single metric.
{{
config(
materialized='table'
)
}}
with user_web_events as (
select
user_id,
count(case when event_name = 'pricing_page_viewed' then 1 end) as pricing_views,
count(case when event_name = 'demo_requested' then 1 end) as demo_requests
from {{ ref('stg_segment_web_events') }}
where event_timestamp >= current_date - 7
group by 1
),
user_app_activity as (
select
user_id,
count(distinct session_id) as active_sessions,
count(case when event_name = 'project_created' then 1 end) as projects_created
from {{ ref('stg_segment_app_events') }}
where event_timestamp >= current_date - 7
group by 1
)
select
u.user_id,
u.email,
coalesce(w.pricing_views, 0) as weekly_pricing_views,
coalesce(w.demo_requests, 0) as weekly_demo_requests,
coalesce(a.active_sessions, 0) as weekly_active_sessions,
coalesce(a.projects_created, 0) as weekly_projects_created,
-- The actual scoring logic was more complex, but this shows the principle
(coalesce(w.pricing_views, 0) * 5) +
(coalesce(w.demo_requests, 0) * 50) +
(coalesce(a.active_sessions, 0) * 2) +
(coalesce(a.projects_created, 0) * 20) as behavior_score
from {{ ref('dim_users') }} u
left join user_web_events w on u.user_id = w.user_id
left join user_app_activity a on u.user_id = a.user_id
This model forces a single source of truth for user activity. The definition of a “behavior score” is right there in the SQL, version-controlled in Git. Marketing and sales can argue about the weighting, but they can no longer argue about the data itself.
Component Three: Closing the Loop with Reverse ETL
Having a brilliant lead score sitting in a data warehouse is useless. Nobody on the sales team is going to write SQL queries to find their next call. The final, critical component was a reverse ETL tool. We used Hightouch to pipe the output of our dbt models back into the tools where work gets done.
Every 15 minutes, Hightouch would sync our `behavior_score` from Snowflake directly to a custom field on the Contact object in Salesforce. We also synced fields like `last_seen_in_product` and `weekly_active_sessions`. We were not just sending leads. We were enriching existing records with near real-time intelligence.
This is the piece most companies miss. They build a fantastic data warehouse but fail to build the last-mile delivery system. It’s like refining crude oil into gasoline but having no gas stations. Reverse ETL is the fleet of tanker trucks that gets the fuel to the engines of the business.
The New Alerting System
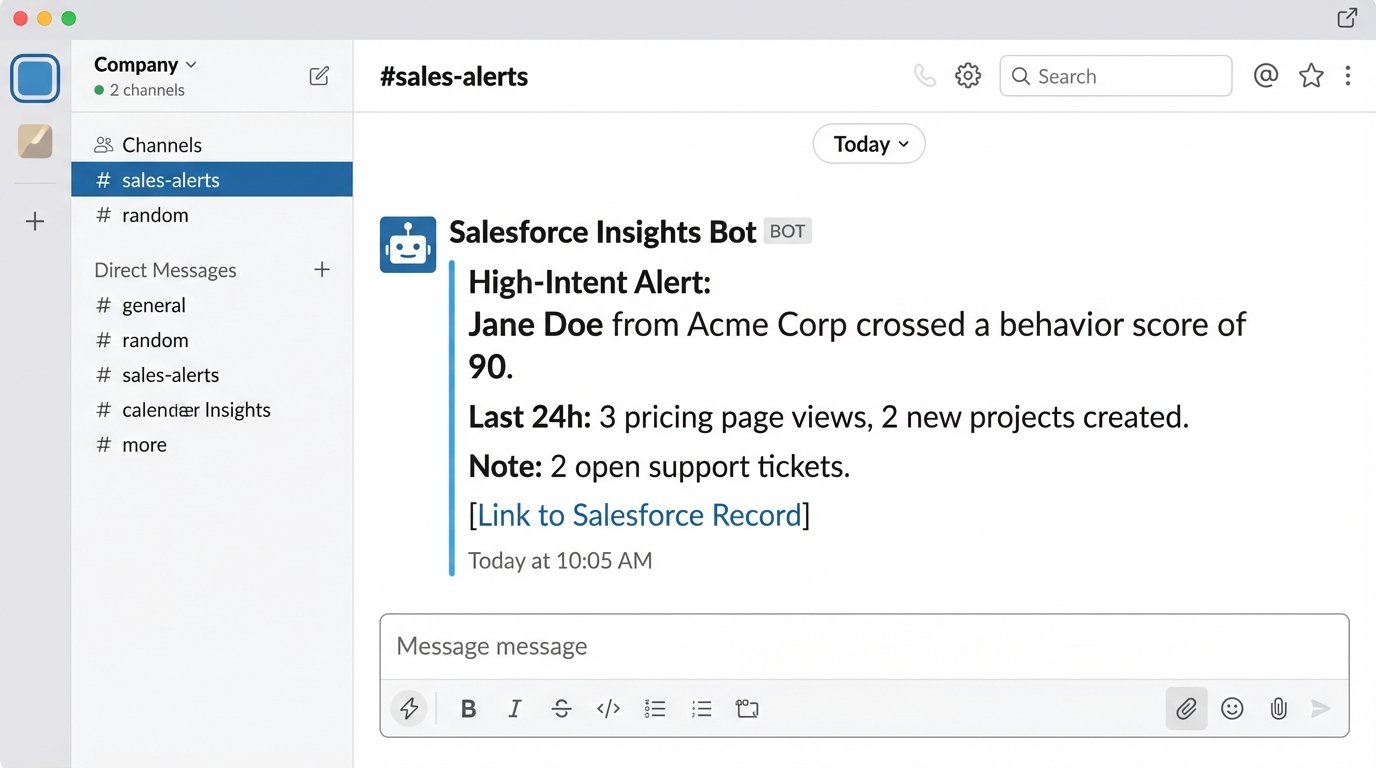
With this new plumbing in place, we could finally build intelligent alerts. Instead of a “new lead” notification, we configured Salesforce to trigger alerts based on changes in the behavior score. When a contact’s score crossed a certain threshold, a targeted Slack message was sent to the account owner.
The message didn’t just say “call this person.” It said: “Jane Doe from Acme Corp just crossed a behavior score of 90. In the last 24 hours, she viewed the pricing page 3 times and created 2 new projects. This account has 2 open support tickets. Here is the link to her Salesforce record.”
This is context. This is actionable intelligence. This is the difference between a lead and a task.
The Results: More Than Just a Number
The headline number is that we tripled the volume of sales-qualified leads within two quarters. But that’s a vanity metric. The real impact was on efficiency and revenue. The lead-to-opportunity conversion rate increased by 210% because the leads were based on actual product intent, not a flimsy PDF download.
Sales reps were no longer wasting the first ten minutes of a call asking discovery questions the data already knew. They could open the conversation with “I see you’re using our project creation feature. How is that working for your team?” The quality of conversations improved overnight.
The Uncomfortable Truth About Cost
This stack is not cheap. Snowflake, Segment, and Hightouch are serious enterprise tools with price tags to match. The monthly bill for this infrastructure is a five-figure number. It is a wallet-drainer, no question. But the return was immediate and substantial.
We calculated that the system paid for itself if it sourced just two enterprise deals per quarter. It sourced five in the first quarter it was fully operational. The cost is high, but the cost of operating blind and having sales and marketing in a state of civil war was much higher.
The System is a Garden, Not a Building
The biggest trade-off is the maintenance burden. This is not a “set it and forget it” machine. The lead scoring model requires constant tuning as our product evolves and we learn more about user behavior. The dbt models need to be maintained and expanded. Data quality issues still crop up and require investigation.
We had to hire a dedicated analytics engineer to own this stack. You cannot hand this system off to a marketing team. It requires an owner who understands data modeling, SQL, and API integrations. Anyone who tells you a system this powerful runs itself is trying to sell you something.
Copying this tech stack without copying the operational discipline and engineering talent to run it is a recipe for building a very expensive, very confusing mess. The tools are just enablers. The real work was in changing our entire philosophy, from chasing MQLs to identifying genuine buying intent through behavioral data analysis.