
The Problem: A System Fueled by Ink and FedEx
The initial state of the transaction process was a slow-motion disaster. Every deal involved a stack of paper thick enough to stop a door, couriered between agents, buyers, sellers, and title companies. Data entry meant a junior associate staring at a purchase agreement and manually keying hundreds of fields into three different systems. The error rate for this manual transfer was a consistent 8%. That meant nearly one in ten deals had a typo in a name, an address, or a dollar amount that could derail a closing.
Closing timelines were dictated by courier schedules, not business logic. A missing signature on page 47 meant the entire package had to be sent back, adding a two-day delay. Compliance was an exercise in faith. We had rooms of filing cabinets holding the official record, making any audit request a multi-week scavenger hunt. The direct cost of paper, ink, and shipping alone was six figures annually. The indirect cost of delays and corrections was incalculable.
The Mandate: Gut the Process, Not Just Digitize It
Management’s request was simple: “make it paperless.” My interpretation was different: automate the logic, not just the documents. Simply replacing a signed piece of paper with a signed PDF is a marginal improvement. The real value is in treating the documents as structured data from the moment of inception. We needed to build a system that could ingest, parse, validate, and route information with minimal human touch.
The goal was to build a central nervous system for transactions. It had to ingest documents from multiple sources, rip the data out, logic-check it against our core business rules, and then push structured, validated data into our downstream systems. This wasn’t about scanning PDFs. This was about building a data pipeline where the documents were just the temporary transport medium.
Phase 1: Taming the Intake Monster
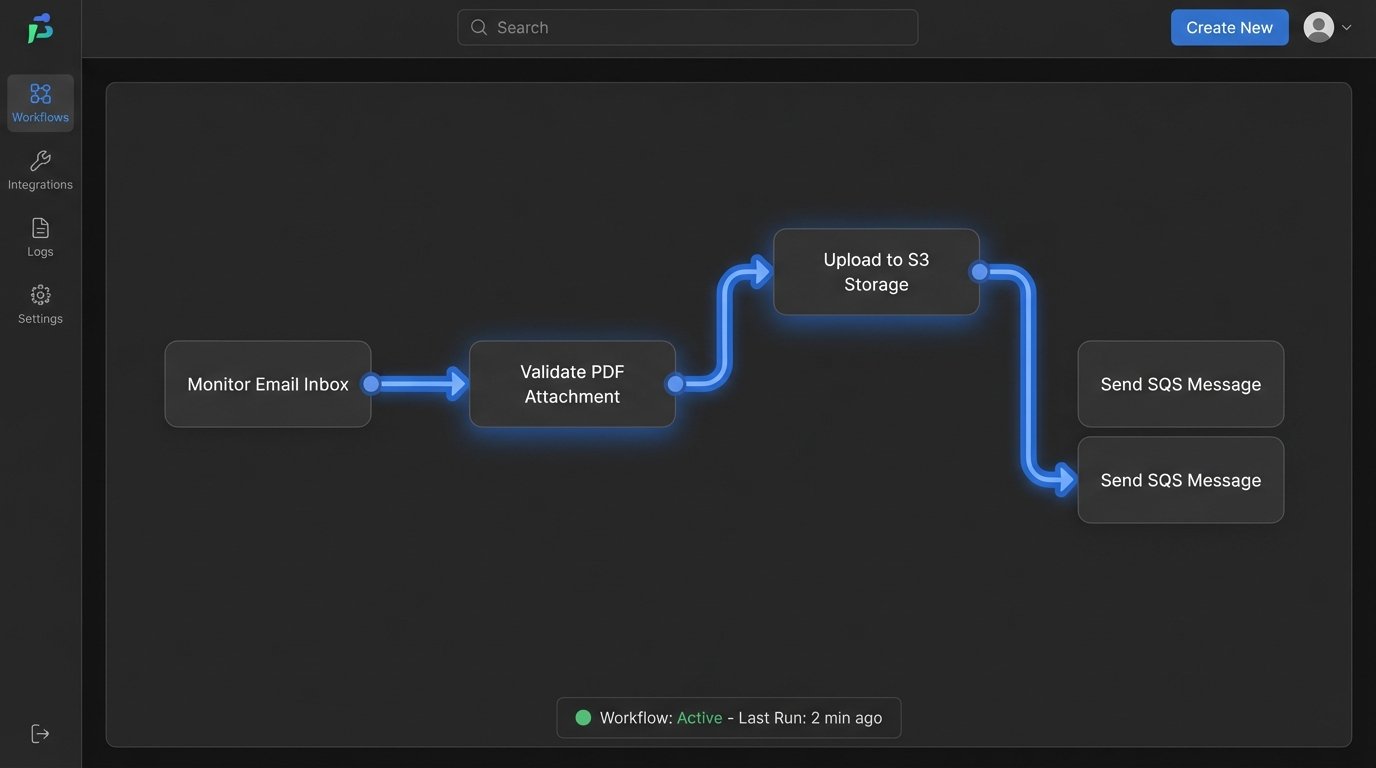
The first challenge was intake. We couldn’t just switch off the old process. We had to accommodate agents who still preferred to email scanned, barely legible PDFs. We built a multi-channel ingestion point. A new web portal for the tech-forward agents to input data directly, and a dedicated email inbox monitored by a script for the laggards. Every attachment landing in that inbox was immediately grabbed by a Python service.
This service first performed basic validation. Is it a PDF? Is it over a certain size? Is it password-protected? Simple checks to filter out the junk. The valid files were then dumped into an S3 bucket, triggering the next stage of the process via an SQS message. This decoupled architecture prevented a single bad email from jamming the entire pipeline. It was our first line of defense against chaos.
Phase 2: The OCR Gauntlet and Data Extraction
This is where the real fight began. We piped the PDFs from S3 into AWS Textract. We chose Textract over open-source options like Tesseract because its table and form extraction capabilities were better out of the box, saving us weeks of development pain. It wasn’t cheap, but the cost was justifiable compared to the engineering hours required to build and train a comparable custom model.
The raw JSON output from Textract is a firehose of text, coordinates, and confidence scores. It’s unusable on its own. We built another Python service whose only job was to parse this output. Using a library of predefined templates based on our most common forms, the service located key fields like “Buyer Name,” “Property Address,” and “Purchase Price.” For each field, we stored not just the extracted value, but the confidence score Textract provided.
Trying to map this unstructured OCR output to a rigid database schema is like trying to sync two clocks with a wet string. It’s a messy, unreliable process. Any field with a confidence score below 95% was flagged for human review. Critical financial fields were flagged regardless of score. This “human-in-the-loop” step was non-negotiable. We built a simple web interface where a small team could quickly validate the flagged data, correcting OCR errors before they could poison our downstream systems.
Phase 3: Building the Logic Core and System Integration
With clean, validated data, we could finally execute business logic. We used Apache Airflow to orchestrate the workflow. Each transaction became a DAG (Directed Acyclic Graph). One task would check if the purchase price fell within an expected range. Another would cross-reference the buyer’s name with our CRM to see if they were an existing client. Another would verify the property address against a public records API.
Each step was a pass or fail. A fail would trigger a notification to the transaction coordinator, specifying the exact error. For example, “Purchase price of $5,000,000 exceeds agent’s approval limit of $2,000,000.” This replaced the old method of a manager discovering the issue three days before closing.
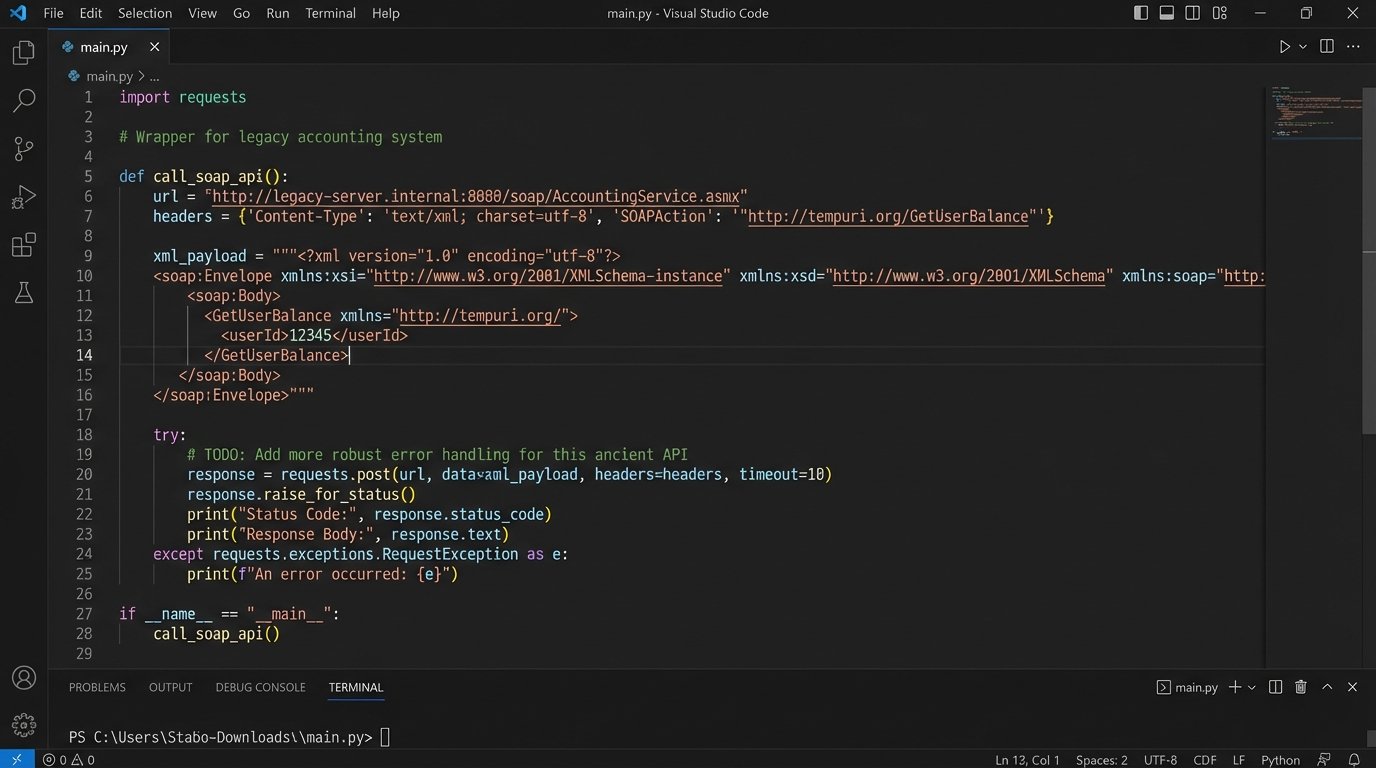
The integration part was brutal. Our core accounting system was a decade-old monolith with a poorly documented SOAP API. There was no SDK. We had to write our own client from scratch, reverse-engineering API calls using XML payloads that looked like they were written in 2003. We wrapped this entire mess in a cleaner internal REST API so that no other service would have to suffer through it directly. It was a containment strategy for bad technology.
Phase 4: Document Generation and E-Signature
Once all logic checks passed, the system moved to generate the final closing documents. We used a templating engine to inject the validated data into standardized document templates. This eliminated copy-paste errors entirely. The final packet, now a single, correctly ordered PDF, was then pushed to the DocuSign API.
Dynamically placing signature and date tabs was the trickiest part. The position of a signature block can change based on the number of buyers or the inclusion of optional addenda. We had to build a system that calculated the X/Y coordinates for each tab based on the final generated document’s structure. This required a lot of trial and error.
Here is a simplified look at the JSON payload we constructed to tell the API where to place a signature tab. The real version had more error handling and dynamic values, but this shows the core concept. We had to define the document, the recipient, and the exact placement of every single tab.
{
"emailSubject": "Signature Requested for 123 Main St",
"documents": [{
"documentBase64": "...",
"documentId": "1",
"fileExtension": "pdf",
"name": "PurchaseAgreement_123_Main_St.pdf"
}],
"recipients": {
"signers": [{
"email": "buyer@email.com",
"name": "John Doe",
"recipientId": "1",
"tabs": {
"signHereTabs": [{
"documentId": "1",
"pageNumber": "15",
"xPosition": "120",
"yPosition": "550"
}],
"dateSignedTabs": [{
"documentId": "1",
"pageNumber": "15",
"xPosition": "410",
"yPosition": "575"
}]
}
}]
},
"status": "sent"
}
This level of control was critical. We couldn’t rely on manual drag-and-drop templating within the e-signature platform. The automation had to control the entire lifecycle from data extraction to final signature placement.
The Results: Faster, Cheaper, and Auditable
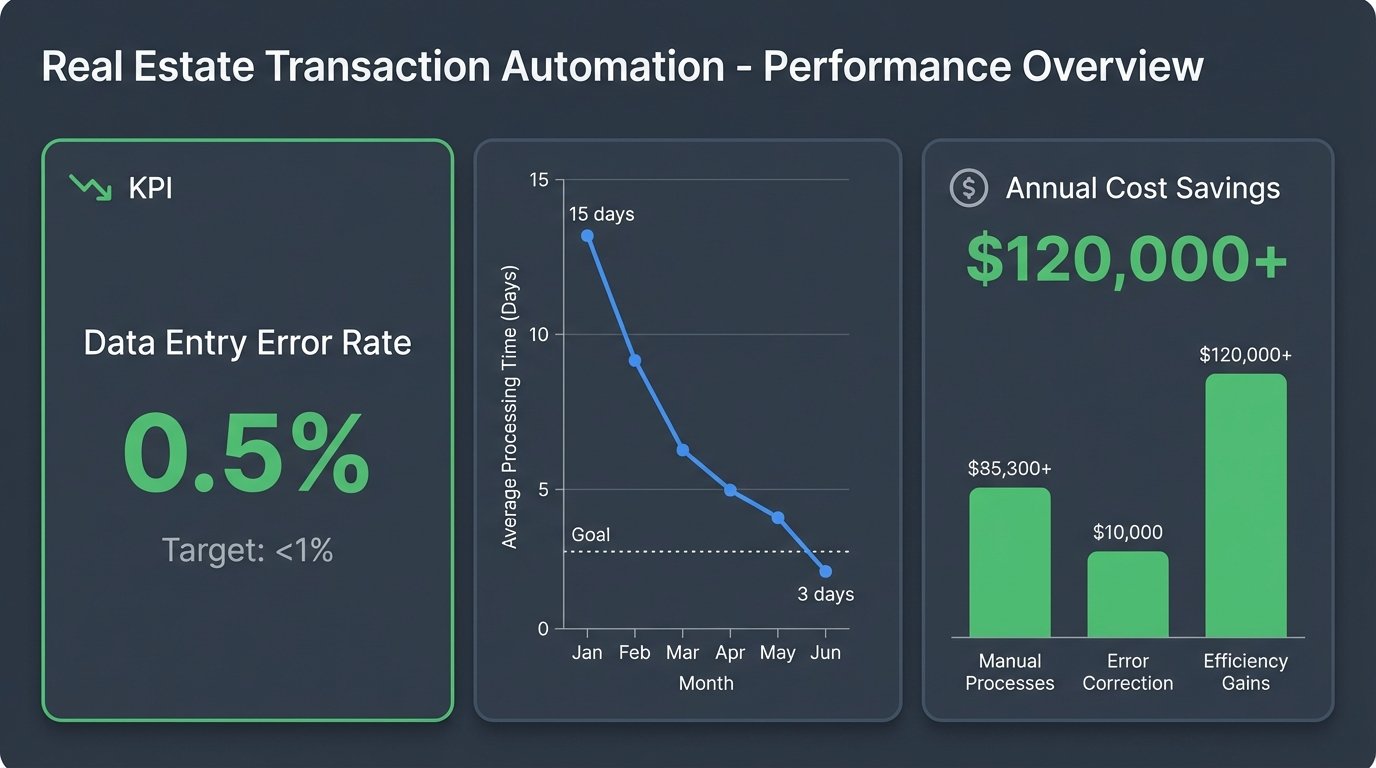
The numbers speak for themselves. The average transaction processing time, from contract receipt to having a fully executed package ready for closing, dropped from 15 days to 3 days. The manual data entry error rate of 8% fell to less than 0.5%, with the remaining errors being caught by the human-in-the-loop validators before they caused any damage.
We completely eliminated over $120,000 in annual courier and paper supply costs. The project paid for itself in 14 months, even factoring in the hefty OCR and e-signature API bills. The biggest win, however, was compliance. Every action in the system was logged. We could produce a complete audit trail for any transaction in minutes, not weeks. This turned audits from a dreaded event into a routine report generation.
What Still Keeps Me Up at Night
This system isn’t perfect. Our OCR process still struggles with handwritten notes in the margins of contracts, forcing manual intervention. We are completely dependent on the uptime of three major external APIs, creating a single point of failure that we can only mitigate, not eliminate. Our contract parsing logic is also brittle. A title company changing the format of their standard agreement by adding a new paragraph can break our field extraction templates.
The solution requires constant monitoring and maintenance. It’s not a “set it and forget it” machine. It’s a complex engine that needs regular tuning. The project proved that you can automate a deeply entrenched, paper-based process, but it also showed that the resulting system is a living thing with its own unique set of problems.