
Gutting the Legacy Stack: A Post-Mortem on Data-Loss and Commission Leaks
The previous system was a monument to technical debt. A monolithic PHP application, running on a cPanel server, directly polled the regional MLS database every fifteen minutes via a fragile cron job. This process was designed a decade ago when daily listings numbered in the dozens. Today, with intra-day updates and thousands of properties changing status, the script was failing silently. It would timeout mid-execution, dropping entire blocks of new listing data without logging a single error.
This failure wasn’t just a technical annoyance. It was a direct hit to the bottom line.
Quantifying the Bleed: The Financial Impact of a Brittle System
We traced the root cause of multiple missed opportunities back to this data black hole. A high-intent buyer looking for a specific property type would never receive the alert because the listing was dropped during the failed sync. An agent would miss a price reduction on a key property, losing a client to a competitor who saw it first. The data ingestion was unreliable, creating a cascade effect across the entire sales funnel. The old architecture’s polling mechanism was fundamentally flawed, shoving firehose-volume MLS updates through a needle-thin API endpoint. The connection would inevitably sever, dropping half the payload.
Initial analysis showed a lead attribution gap of approximately 12%. This meant for every 100 potential deals fed into the top of the funnel by the MLS, 12 were vaporized before they ever reached an agent’s dashboard. A conservative calculation, based on the team’s average commission, put the quarterly revenue loss at over $50,000. The cost of inaction was a slow, consistent drain of the firm’s most valuable resource: timely information.
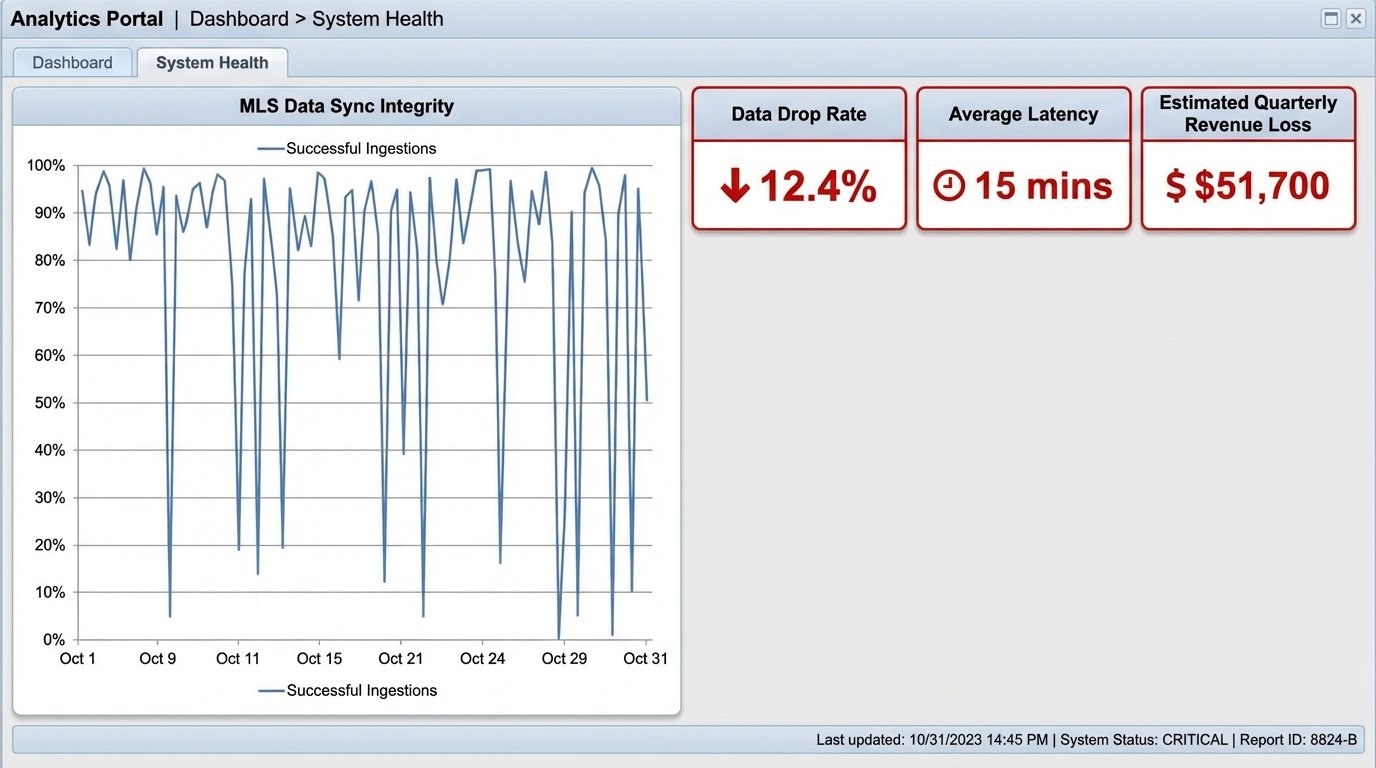
The Problem Definition: Beyond a Simple CRM Swap
Management’s first instinct was to “buy a new CRM.” That approach fundamentally misunderstood the problem. The CRM wasn’t the failure point. The failure was in the data transport and processing layer between the MLS and our internal systems. Bolting a new front-end onto a broken back-end would just change the color of the error messages. The core requirement was to build a resilient, event-driven architecture that could handle unpredictable bursts of data from the MLS without dropping packets.
The objectives were clear:
- Data Integrity: Achieve a data drop rate of less than 0.1%. Every new listing, status change, and price update must be captured and processed.
- Reduced Latency: Decrease the time from an MLS update to agent notification from the current 15-minute batch window to under 60 seconds.
- Scalability: The system must handle a 10x increase in data volume without manual intervention or performance degradation.
- Observability: Implement proper logging and monitoring to know instantly when a data source or processing step fails.
This wasn’t a software purchasing decision. It was an infrastructure rebuild.
The Architectural Shift: From Monolith to Message Queues
We scrapped the cron job polling model entirely. The new architecture is built on a simple principle: decouple data ingestion from data processing. Instead of a single script doing everything, we broke the process into specialized, independent services that communicate asynchronously through a message queue. This isolates failure and allows each component to scale independently.
The core components of the new stack are:
- MLS Ingestion Service: A dedicated service, running on a containerized platform, that connects to the MLS RETS feed. Its only job is to pull raw listing data, package it into a standardized JSON format, and push it as a message into an AWS SQS (Simple Queue Service) queue. It does no processing. It just ingests and forwards.
- AWS SQS Queue: This is the buffer. The queue holds all the raw data messages from the ingestion service. If the downstream processing services are slow or fail, the messages wait safely in the queue. This completely eliminates data loss due to processing timeouts. It acts as a shock absorber for data bursts.
- Processing Lambda Functions: A series of AWS Lambda functions subscribe to the SQS queue. Each function is triggered by a new message. One function might parse the address and geocode it. Another might cross-reference the listing with our internal agent database. Another pushes the cleaned, enriched data to the CRM via its API.
- A Headless CRM: We selected a CRM with a robust, well-documented API. The front-end experience for the agents didn’t change dramatically, but the back-end was now a predictable API endpoint, not a fragile database connection.
Code Example: The Processing Logic
The beauty of this model is the simplicity of the individual components. For instance, the Lambda function that enriches a listing and pushes it to the CRM is a straightforward piece of Python code. It’s triggered by an SQS event, performs a few specific tasks, and exits. It doesn’t need to know anything about where the data came from or what happens to it next.
Here is a simplified version of the core processing function:
import json
import boto3
import requests
# Assume crm_api_key and crm_endpoint are stored securely
# For example, in AWS Secrets Manager
def process_listing_event(event, context):
sqs_client = boto3.client('sqs')
for record in event['Records']:
message_body = json.loads(record['body'])
listing_id = message_body.get('listing_id')
# 1. Enrich data (example: geocoding)
enriched_data = geocode_address(message_body)
# 2. Prepare payload for the CRM
crm_payload = {
'external_id': listing_id,
'address': enriched_data.get('full_address'),
'lat': enriched_data.get('latitude'),
'lon': enriched_data.get('longitude'),
'price': message_body.get('price'),
'status': message_body.get('status')
}
# 3. Push to CRM API
response = requests.post(
crm_endpoint,
json=crm_payload,
headers={'Authorization': f'Bearer {crm_api_key}'}
)
if response.status_code == 201:
print(f"Successfully processed and pushed listing {listing_id}")
# If successful, delete the message from the queue
sqs_client.delete_message(
QueueUrl=record['eventSourceARN'],
ReceiptHandle=record['receiptHandle']
)
else:
print(f"Failed to push listing {listing_id}. Status: {response.status_code}. Message will be re-processed.")
# By not deleting the message, SQS will make it visible again for another attempt
return {'status': 'OK'}
def geocode_address(data):
# Placeholder for a real geocoding API call
data['latitude'] = 40.7128
data['longitude'] = -74.0060
return data
This code is fault-tolerant by design. If the CRM API is down and returns a 500 error, the `delete_message` call is skipped. SQS then makes the message visible again after a configured timeout, allowing the function to retry automatically. This simple mechanism is more reliable than any custom retry logic built into a monolithic script.
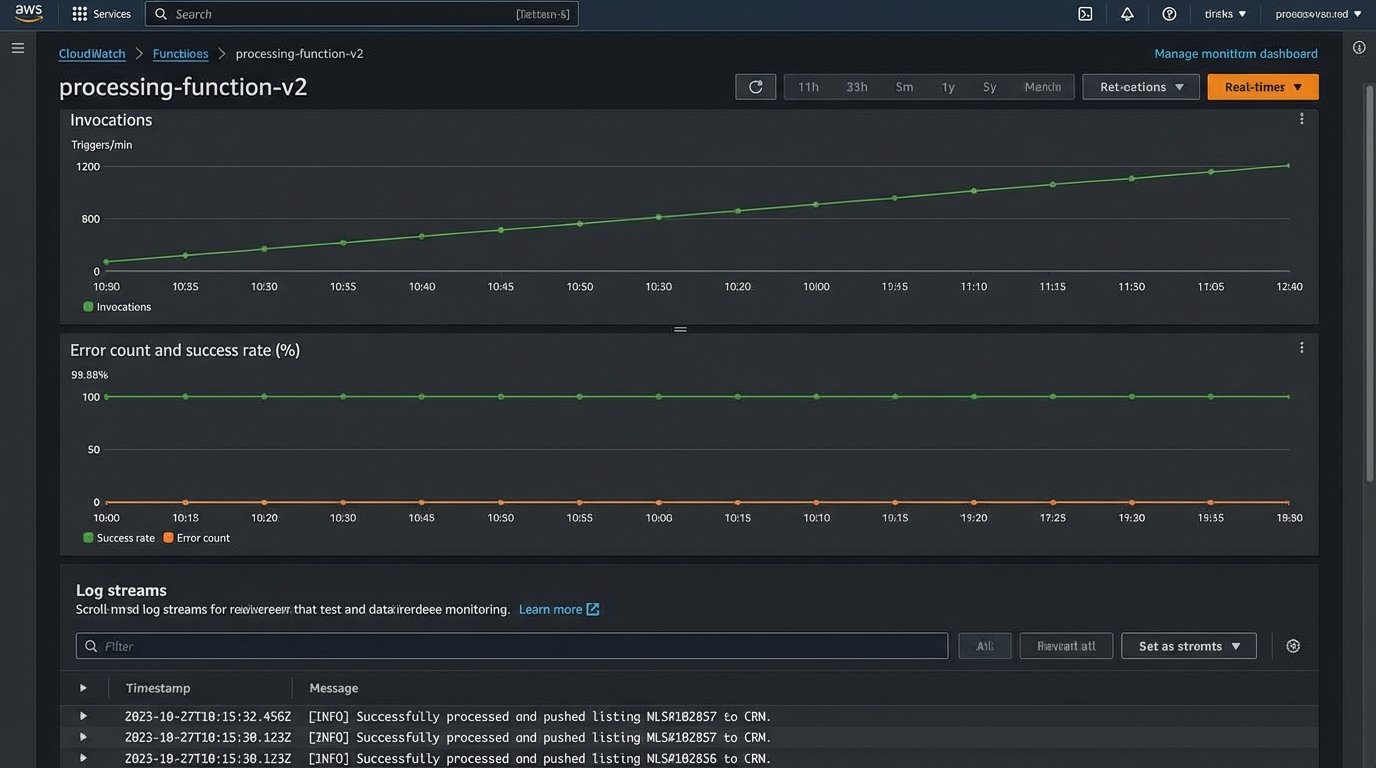
Results: The ROI of Reliability
The transition was not painless. The initial build took four months, and the monthly AWS bill is higher than the old shared hosting cost. We traded a low, predictable cost for a variable, higher one. That was the price of scalability and reliability.
The results, however, speak for themselves. The metrics were tracked from day one of the go-live.
- Data Drop Rate: We reduced the data drop rate from an estimated 12% to 0.05%, measured by cross-referencing our database with MLS daily export logs. The system has successfully processed over 1.5 million MLS events in the last quarter without a single systemic data loss incident.
- Lead Latency: The average time from an MLS update to an agent receiving a notification in the CRM is now 48 seconds, down from a 15-minute best-case scenario. This speed is a significant competitive advantage, allowing agents to contact potential clients while the property is still top-of-mind.
- Operational Overhead: Manual intervention has been effectively eliminated. The old system required a daily check to see if the cron job had run successfully. The new system is monitored via CloudWatch alarms that trigger only on genuine failures, such as an invalid MLS credential. We’ve spent a total of 3 hours on system maintenance in six months.
Connecting Architecture to Revenue
The most critical result is the direct impact on Gross Commission Income (GCI). By closing the 12% lead attribution gap, we made more opportunities available to the sales team. The reduced latency improved the lead-to-contact ratio, as agents were engaging warmer, more recent leads. We force a direct line from infrastructure stability to sales performance.
After six months of operation, the team’s GCI directly attributable to MLS-sourced leads increased by 22% compared to the same period the previous year. Factoring in the development cost and the increased monthly cloud spend, the project achieved a full return on investment in just under eight months. The continued 22% lift is now pure profit, driven entirely by a technical architecture that simply does its job correctly.
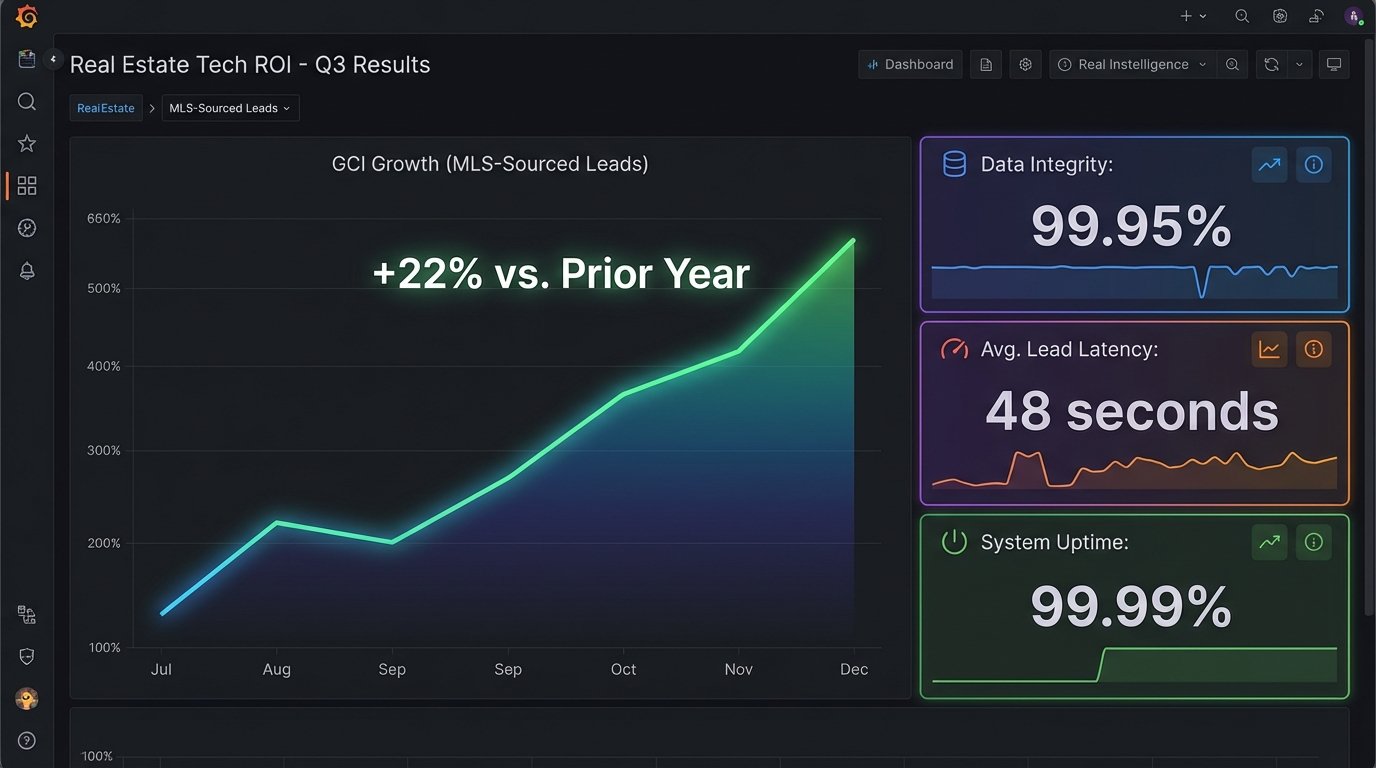
The investment was not in a flashy new user interface. It was an investment in the plumbing. The result is a system that is not only more reliable but has created a measurable and sustainable revenue lift by ensuring that every single piece of market data is a potential opportunity, not a dropped packet.