
Stop Asking AI to Predict the Housing Market
The pitch is always the same. Feed terabytes of market data into a neural network and it will spit out next year’s median home price for a given zip code. This is a fantasy sold to people who have never spent a weekend trying to sanitize a single county’s property tax dataset. The core problem with using AI to forecast housing prices isn’t the sophistication of the models. The problem is the data is, and always has been, a complete mess.
Predictive accuracy is a function of data integrity. Nothing else matters.
The Data Ingestion Nightmare
We start with the Multiple Listing Service, or MLS. It’s not one database. It’s a Balkanized collection of over 500 regional databases, each with its own schema, its own update frequency, and its own definition of “active listing.” Some systems update instantly via a RETS feed. Others dump a CSV file onto an FTP server once a day, if you’re lucky. Trying to stitch this together into a coherent national view is the first gate of engineering hell.
You have to build custom parsers for each feed. You have to write logic to de-duplicate listings when an agent posts the same property to two different MLS systems. You have to map dozens of different ways to describe a property’s status. ‘Active,’ ‘Pending,’ ‘Under Contract,’ ‘Active Contingent.’ They all mean something different, and the definitions vary by region. Forgetting to account for one of these statuses can poison your entire dataset with stale information.
Then you layer in public records data from county assessor and recorder offices. This is supposedly the ground truth for sales history, property taxes, and ownership. The reality is that this data can lag by weeks or even months. A sale that closes in March might not appear in the county record until May. By then, your model’s “real-time” input is already a historical artifact.
Worse, the data quality is atrocious. Addresses are non-standardized. One record says “123 Main St,” another says “123 Main Street,” and a third says “123 E Main St.” You have to force these into a single canonical format before you can even think about joining them to your MLS data. This requires geocoding services, which cost money and are rate-limited. It’s a slow, expensive data-scrubbing operation before you’ve written a single line of machine learning code.
Consider a simple data cleaning task in Python using pandas. You pull in a raw data export and try to standardize a ‘price’ column. It looks simple enough.
import pandas as pd
import numpy as np
# Simulated raw data with common issues
data = {'address': ['123 Main St', '456 Oak Ave', '789 Pine Dr.'],
'price': ['$750,000', '625k', 'Listed at $810000']}
df = pd.DataFrame(data)
def clean_price(price_str):
if isinstance(price_str, str):
# Strip non-numeric characters
price_str = price_str.replace('$', '').replace(',', '').replace('Listed at', '').strip()
# Handle 'k' for thousands
if 'k' in price_str.lower():
price_num = float(price_str.lower().replace('k', '')) * 1000
else:
price_num = float(price_str)
return price_num
return np.nan # Return null for bad data
df['price_cleaned'] = df['price'].apply(clean_price)
# The output seems fine for this small sample.
# But what about edge cases? 'Call for price', 'Price reduced!', or just empty strings?
# A production pipeline needs dozens of rules to handle this one column.
That little code block only handles three variations. In the wild, you will find hundreds. Your cleaning function becomes a brittle stack of conditional logic that needs constant maintenance. This is where most projects die. Not in the tuning of hyperparameters, but in the mundane, thankless work of data sanitation.
Feature Engineering is a Fool’s Errand
Once you have a semi-clean dataset, the next temptation is to engineer features. The obvious ones are easy. Square footage, number of bedrooms, days on market. But what about the features that actually move a market? A change in local zoning laws that allows for duplex construction. A major corporation announcing a new headquarters nearby. The quality of the local school district.
These are not columns in a database. They are unstructured text in news articles, city council meeting minutes, and corporate press releases. Extracting and quantifying this information is a massive NLP challenge. You can build sentiment analysis models to gauge public opinion, but they are noisy and easily fooled by sarcasm or complex language. You can use Named Entity Recognition to find mentions of specific locations or companies, but context is everything.
An article mentioning “layoffs” and “Amazon” in the same paragraph could be a negative signal for the Seattle market. Or it could be a national story with no local impact. Your model has no way to distinguish between the two without a deep, human-like understanding of the text. Building that kind of model is a multi-year research project, not a quarterly business objective.
The effort required to build and maintain the pipelines for these “alternative” data sources is astronomical. You are shoving a firehose of unstructured data through the needle of a structured model. The signal-to-noise ratio is terrible, and the infrastructure costs will drain your budget before you ever get a working prototype.
It’s far more effective to stick to the core, verifiable facts of the transaction data, even if it feels less sophisticated.
The Black Box and the Stakeholder
Let’s assume you solve all the data problems. You build a complex LSTM or Transformer model, and it achieves a low Mean Absolute Error on your backtest. It predicts a 3% decline in prices in a specific metropolitan area over the next quarter. A stakeholder asks you a simple question: “Why?”
If you are using a deep learning model, you don’t have a good answer. You can use techniques like SHAP or LIME to get feature importance scores, but these are post-hoc explanations. They don’t tell you the causal logic inside the model. The true answer is “Because a complex set of matrix multiplications resulted in this output.” This is not an acceptable basis for making a nine-figure investment decision.
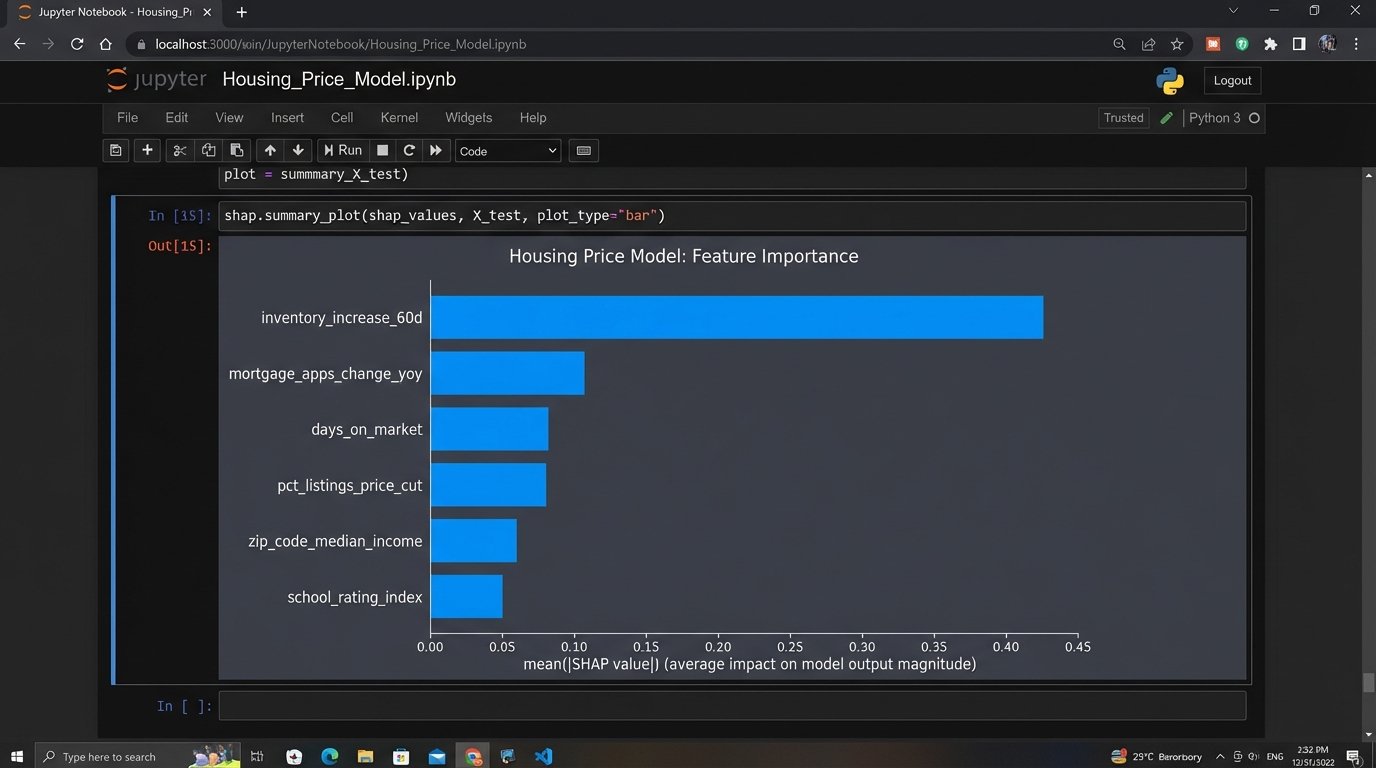
Explainability is not a “nice-to-have.” It is a fundamental requirement for any system that allocates capital. This is why simpler models often win in production environments. A gradient boosted tree, like XGBoost or LightGBM, can give you a clear hierarchy of which features drove the prediction. You can tell a story with the output. “The model is predicting a decline primarily because inventory in this price bracket has tripled in the last 60 days while mortgage applications have fallen by 20%.”
That is an actionable insight. It’s a thesis that can be debated, checked, and validated against other sources. A black box gives you a number. An interpretable model gives you an argument.
A More Defensible Approach: Nowcasting and Anomaly Detection
The obsession with forecasting is a misallocation of resources. Predicting the future is impossible. What is possible is building a high-fidelity, real-time picture of the present. This is often called “nowcasting.” Instead of trying to predict the median price six months from now, focus on accurately measuring the velocity of the market today.
Build pipelines that track leading indicators with minimal lag.
- Inventory Velocity: Track the number of new listings, pending listings, and sold listings on a daily basis, segmented by price tier and property type.
- Pricing Pressure: Monitor the percentage of listings with price reductions versus price increases. A spike in reductions is a powerful leading indicator of a softening market.
- Demand Signals: Ingest data on mortgage applications, tour requests from portals like Zillow, and agent activity metrics.
The goal is to build a dashboard, not a crystal ball. This system doesn’t give you a single price prediction. It gives you a suite of metrics that allow a human expert to see the market changing before it shows up in the lagging government statistics.
The machine learning task then shifts from forecasting to anomaly detection. Your models should not be trying to predict a specific value. They should be trying to identify when a specific market is behaving in a way that deviates significantly from its historical patterns or from comparable markets. For example, an algorithm can flag a suburban zip code where inventory is rising at three times the rate of its neighbors. This doesn’t predict a crash. It provides a targeted alert that tells an analyst exactly where to focus their attention.
This is a support tool for human intelligence, not a replacement for it.
Building the Plumbing First
A successful system is 90% data engineering and 10% data science. You must build robust, self-healing data pipelines before you even think about model selection. This means obsessive focus on the unglamorous backend work.
- Schema Enforcement: Your data ingestion process must strictly enforce a predefined schema. If an upstream source adds or removes a column, the pipeline should fail loudly rather than silently passing corrupted data downstream.
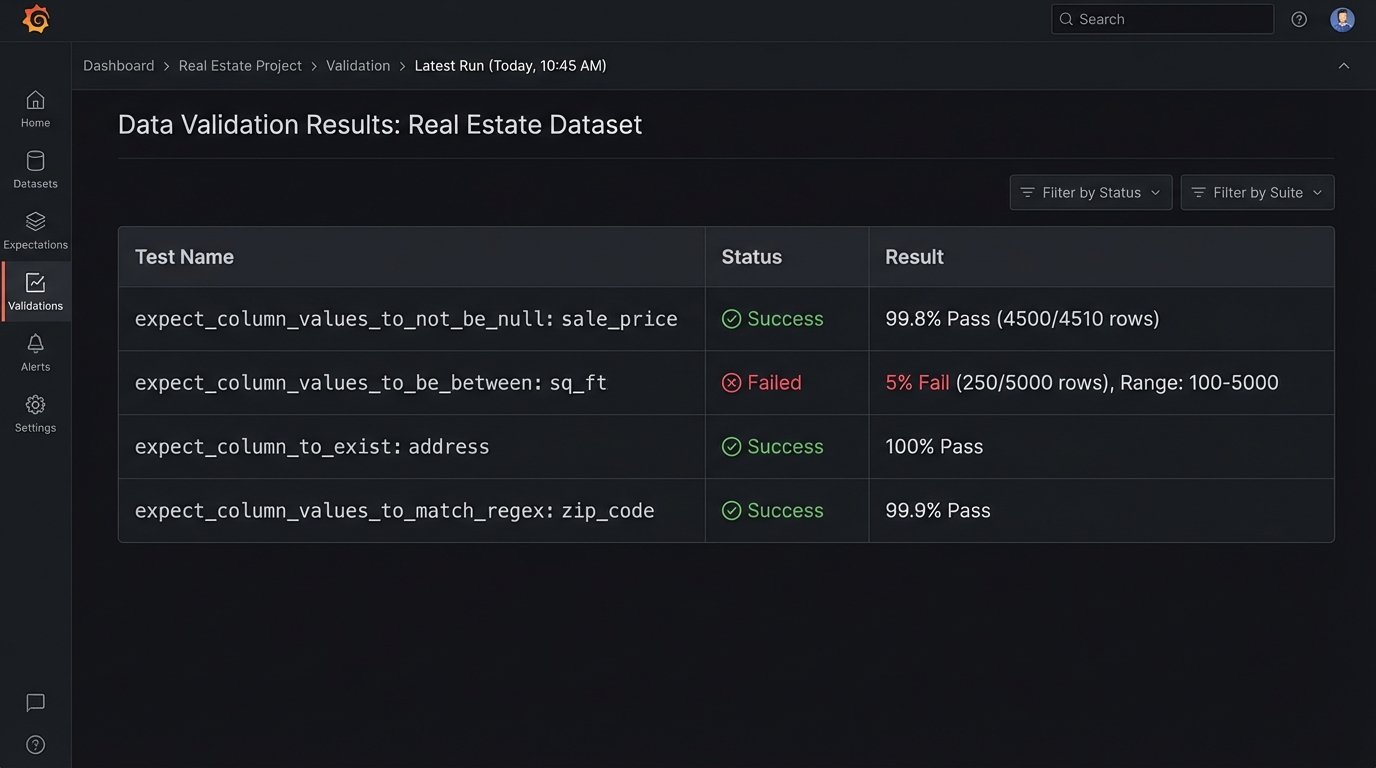
- Data Validation: Use frameworks like Great Expectations or Pandera to define assertions about your data. For every batch of data you process, you should logic-check that prices are within a reasonable range, that dates are sequential, and that categorical values are from an approved list.
- Monitoring and Alerting: The pipeline itself must be monitored. You need alerts for when a data source is late, when the volume of data changes unexpectedly, or when your data validation tests start failing.
The system’s default state should be one of skepticism. Assume every new piece of data is wrong until it has passed a battery of automated checks. This is the only way to build a foundation stable enough to support any kind of analytical model.
Forget about building a magical AI that can outsmart the market. The entire premise is flawed. The market is a complex adaptive system driven by human psychology as much as by economic fundamentals. No amount of historical data can predict a sudden shift in buyer sentiment or a global pandemic.
The real job is to build a reliable machine for seeing the present clearly. Strip away the noise, validate the inputs, and measure the critical flows of supply and demand in near real-time. If you can do that, you have built something far more valuable than a faulty crystal ball.