
Stop Chasing the Ghost of 100% Automation
Every executive pitch on deal processing automation starts the same way. A slick slide shows a clean, linear flow from intake to closing, powered by AI and promising zero human touch. This is a fantasy. In the trenches, we know the reality is a swamp of unstructured PDFs, conflicting CRM data, and third-party APIs that go down on the last day of the quarter.
The obsession with “lights-out” automation in a compliance-heavy environment is not just misguided; it’s dangerous. It creates brittle systems that fail silently or, worse, generate auditable errors at scale. The goal isn’t to remove humans. The goal is to arm them, to turn them into exception handlers instead of data-entry drones.
The Data is the Problem, Not the Workflow
We’re sold workflow engines and RPA bots as the solution. These tools are fine, but they are just hammers. They are useless if the nails are made of wet spaghetti. The root of the problem in deal processing, especially in sectors like finance or real estate, is the absolute garbage state of the input data.
You have a Purchase Agreement scanned as a crooked PDF with coffee stains. The OCR engine tries its best but interprets an “8” as a “B” in the closing date. You have a CRM where one sales rep enters “United States” and another enters “USA”. You have a counterparty information system whose API documentation was last updated three years ago and returns nulls for required fields without warning. Trying to build a fully automated compliance layer on top of this is like trying to build a cleanroom on a landfill.
The system has to be designed with the explicit assumption that the data is corrupt. This means every single piece of ingested information needs to be subjected to a battery of validation and normalization routines before it ever touches a core logic path.
Your first line of defense is a brutalist validation schema.
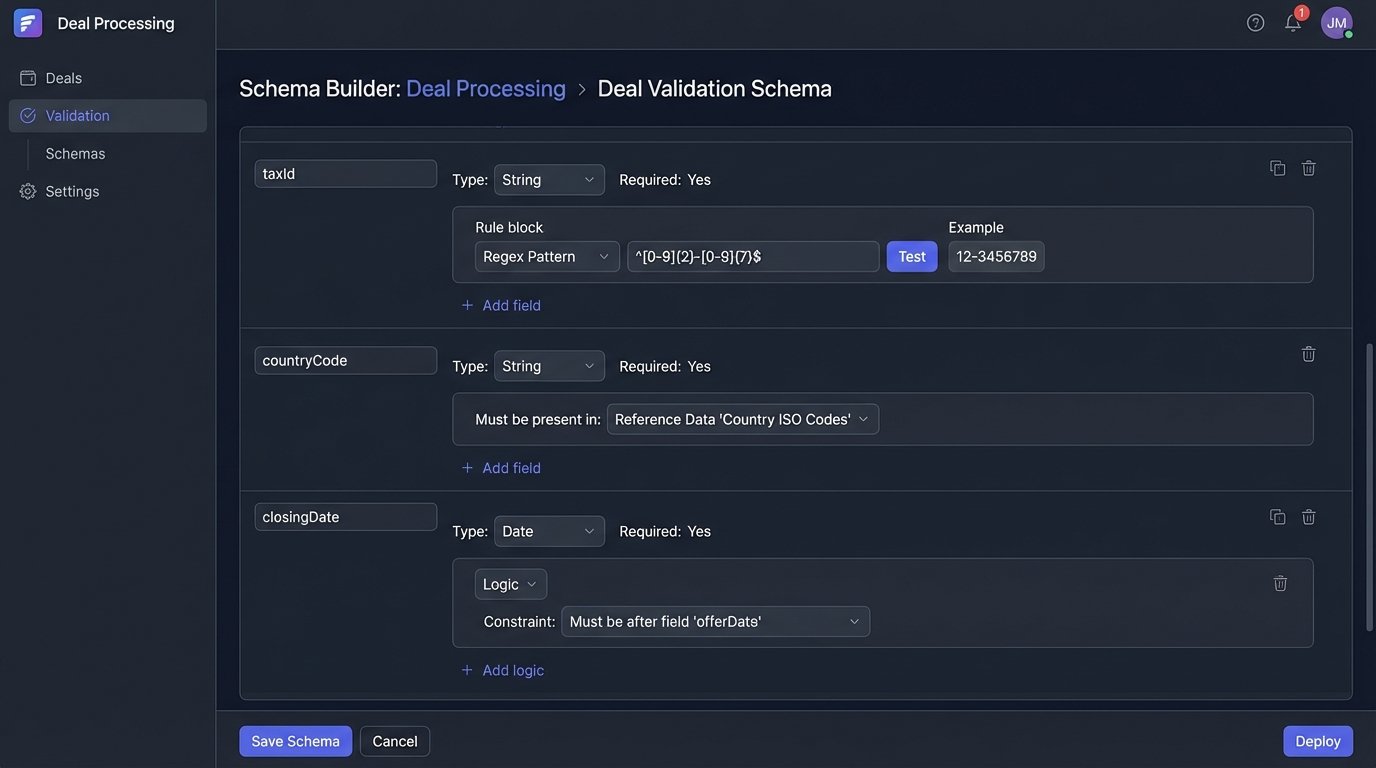
We force every incoming data object, whether from an API or an OCR process, through a rigorous schema check. This isn’t just about checking if a field is a string or an integer. It’s about pattern matching on tax IDs, logic-checking dates to ensure a closing date is after an offer date, and cross-referencing entity names against a master list to catch fat-finger errors.
RPA is a Band-Aid on a Bullet Wound
The next temptation is to throw Robotic Process Automation at the problem. “Just have a bot copy-paste the data from the PDF into the system,” they say. This approach is fundamentally flawed because it codifies the broken manual process. It doesn’t fix it; it just makes the bad process run faster, scaling the potential for error.
An RPA bot is a screen-scraper. It is tethered to the user interface. When the UI of a web portal changes by a few pixels, the bot breaks. When a modal popup appears unexpectedly, the bot breaks. This creates a maintenance nightmare, a brittle script that requires constant babysitting by an engineer who has better things to do than adjust screen coordinates.
A more durable solution bypasses the UI entirely. It means demanding API access from your vendors. If they don’t have one, it’s a massive red flag about their technical maturity. If they do, you hammer that API directly. You get structured data, predictable responses, and proper error codes. You trade the fragility of screen-scraping for the solidity of a contract-based data exchange.
Architecture for Reality: The Augmented Analyst
A realistic architecture accepts data chaos and human fallibility. It automates the high-volume, low-complexity checks and intelligently queues the exceptions for a human analyst. The system doesn’t just fail; it fails gracefully, packaging up the problematic transaction with all the context an analyst needs to make a fast, correct decision.
This “Human-in-the-Loop” (HITL) system has a few core components:
- Ingestion & Validation Layer: This is the front door. It pulls data from all sources (APIs, scanned documents via OCR, email parsers). Its only job is to sanitize, normalize, and validate. Anything that fails validation is immediately shunted to a manual review queue.
- Workflow Engine: This is the brain. It takes the clean, validated data and runs it through a state machine of compliance rules. Each rule is a discrete, testable unit of logic. Is the loan-to-value ratio within limits? Check. Is the entity on a sanctions list? Check.
- Exception Queue: When a rule fails, the workflow engine doesn’t just stop. It compiles a “case file” containing the transaction data, which rule failed, and why. It then pushes this package to a task queue for a human analyst.
- Analyst Interface: This is not the CRM. It’s a purpose-built UI that shows the analyst the case file. They see the exact data, the failed rule, and are given a clear set of actions (“Approve,” “Reject,” “Request More Information”). Their decision is the final word.
The workflow engine acts as a railway switch operator, routing standard trains automatically but signaling a human controller when a weird-looking cargo car shows up. This keeps the expert humans focused on the 5% of deals that are actually weird, instead of wasting their time on the 95% that are boilerplate.
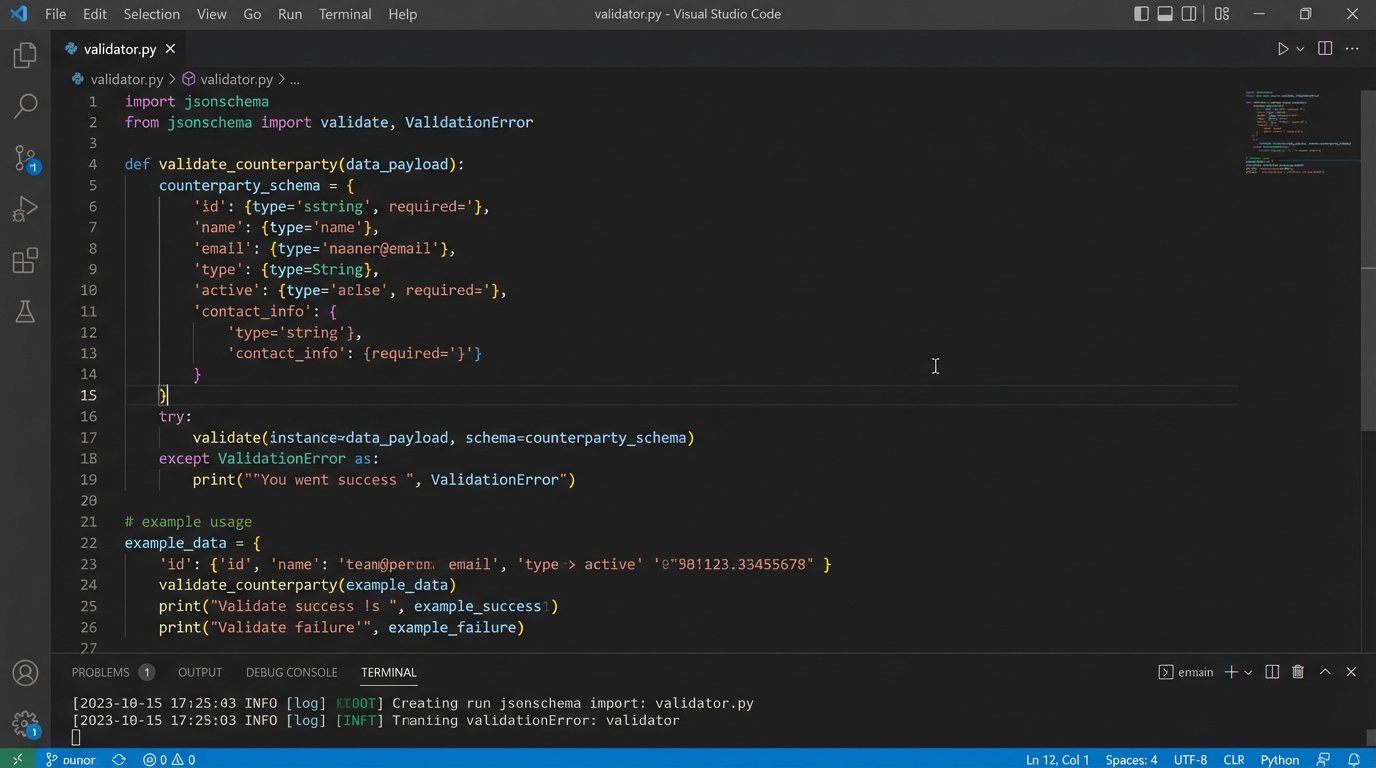
The code for a rule check inside the engine should be simple. It’s a function that receives a data object and returns a boolean. Here’s a conceptual example in Python for validating a JSON payload representing a deal component.
import jsonschema
# This schema defines the expected structure and data types for a counterparty.
# It's the contract. Any data not conforming to this is rejected immediately.
COUNTERPARTY_SCHEMA = {
"type": "object",
"properties": {
"entityName": {"type": "string", "minLength": 1},
"taxId": {"type": "string", "pattern": "^[0-9]{2}-[0-9]{7}$"},
"countryCode": {"type": "string", "pattern": "^[A-Z]{2}$"},
"sanctioned": {"type": "boolean"}
},
"required": ["entityName", "taxId", "countryCode"]
}
def validate_counterparty(data_payload):
"""
Validates a data payload against the predefined JSON schema.
This is a hard gate. No validation, no entry into the workflow.
Args:
data_payload (dict): The counterparty data to validate.
Returns:
tuple: (is_valid, error_message)
"""
try:
jsonschema.validate(instance=data_payload, schema=COUNTERPARTY_SCHEMA)
return True, None
except jsonschema.exceptions.ValidationError as err:
# We don't just fail; we capture the specific reason for the failure.
# This context is gold for the analyst in the exception queue.
return False, f"Schema validation failed: {err.message}"
# Example Usage:
valid_party = {
"entityName": "Valid Corp Inc.",
"taxId": "99-1234567",
"countryCode": "US",
"sanctioned": False
}
invalid_party = {
"entityName": "Invalid LLC",
"taxId": "INVALID-ID", # Fails the pattern check
"countryCode": "USA" # Fails the pattern check
}
is_valid, error = validate_counterparty(valid_party)
print(f"Validation for valid_party: {is_valid}, Error: {error}")
is_valid, error = validate_counterparty(invalid_party)
print(f"Validation for invalid_party: {is_valid}, Error: {error}")
This isn’t complex code. The discipline comes from applying it relentlessly at every data entry point. It’s a bouncer at the door of your system.
The Audit Log is the Product
In a regulated industry, the automation itself is not the primary product. The immutable audit log is. Auditors and regulators don’t care about your Python code or your workflow diagram. They care about a verifiable, chronological record of every decision, both automated and human.
Every time the system ingests data, it logs the source and the payload. Every time a rule is executed, it logs the rule, the input data, and the pass/fail result. Every time a human analyst makes a decision, it logs their user ID, the timestamp, the action they took, and the justification they provided. This log is the system of record.
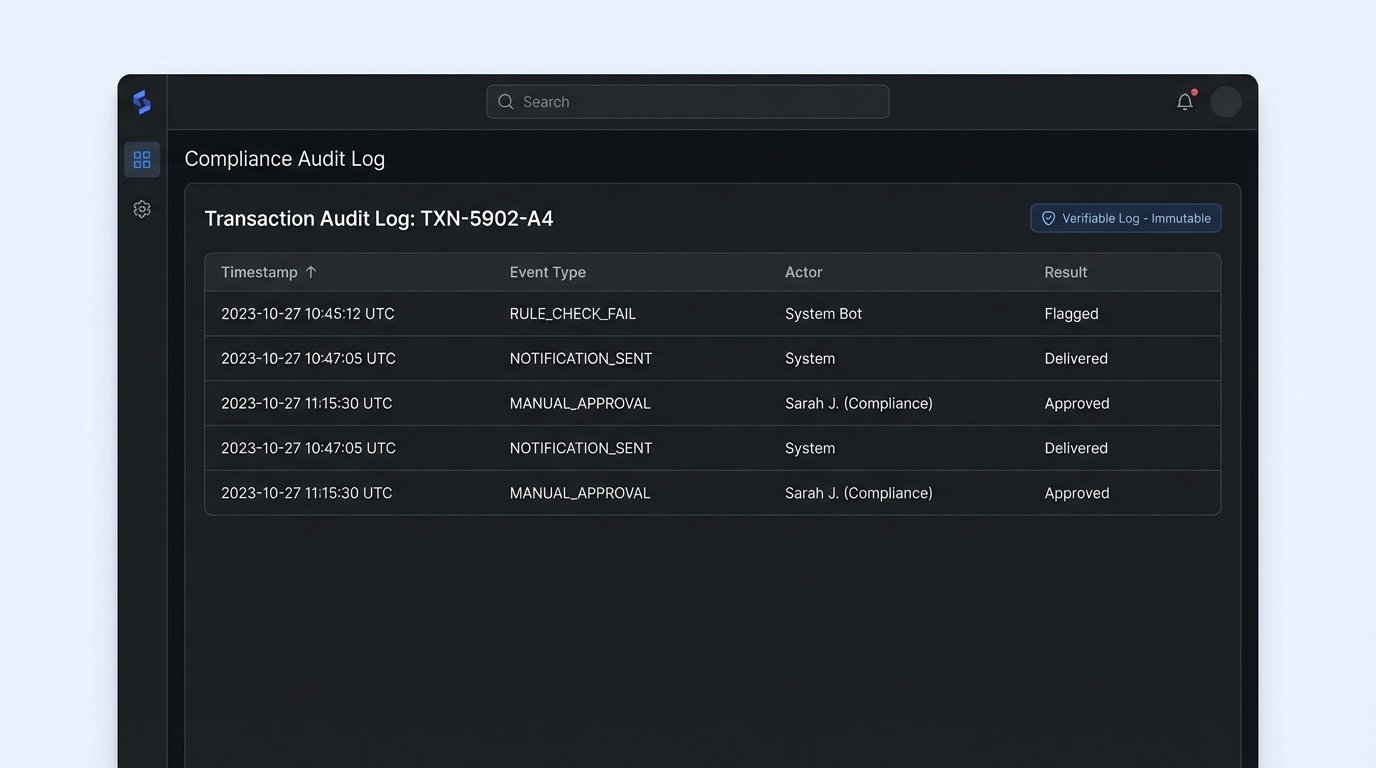
Treating your audit log as an afterthought is like building a skyscraper and then trying to shove the foundation in afterward. It must be a core design principle from day one. This log should be write-only for the application services and stored in a way that prevents tampering. Systems like Amazon QLDB or using blockchain concepts for checksumming are not overkill here; they are the correct tools for the job when provenance is non-negotiable.
The ultimate goal is to produce a system that can answer three questions for any deal, at any point in time, without ambiguity:
- What information did we have?
- What decisions did we make with it?
- Who or what made those decisions?
If your automation can’t answer those questions instantly, it isn’t creating efficiency. It’s creating auditable risk.