
Regulation as an API Constraint, Not a PDF
Legal departments hand down regulatory documents like stone tablets. They expect engineering to just “implement” them. This thinking is fundamentally broken. A regulation, whether it’s the Tenant Data Privacy Act or RESPA, is not a legal document to an engineer. It is a new set of API constraints, a schema change, and a non-negotiable validation layer that your systems must absorb or break against.
We treat external API rate limits as a hard technical boundary. We build circuit breakers, queues, and retry logic to handle them. Yet, when the constraint is a 30-day data deletion requirement from a privacy law, the response is often a ticket in a backlog and a series of meetings. The system sees no difference. A failure to comply with a legal requirement is just another unhandled exception, except this one comes with a multi-million dollar price tag.
The Brittle Architecture of Manual Compliance
Most architectures in real estate tech are not designed for regulatory fluidity. They are monolithic structures built for speed of data acquisition from a thousand different Multiple Listing Services. The core logic assumes data, once ingested, is an asset to be held indefinitely. Privacy regulations like GDPR and CCPA directly attack this assumption. The “right to be forgotten” is a targeted DELETE query with a strict SLA that most data lakes are incapable of executing efficiently.
A typical response is to build a separate, out-of-band process. A script run by a data steward, triggered by a support ticket. This is a stopgap, not a solution. It creates a shadow infrastructure that is untested, unmonitored, and completely dependent on human intervention. This is how data gets left behind in caches, logs, and analytical derivatives. It’s a distributed systems problem being solved with a spreadsheet.
This approach forces engineers to bolt on compliance logic after the fact. You end up injecting filters and checks into code paths that were never designed for them. This is technical debt with compounding interest, paid every time a new regulation is passed or an old one is reinterpreted. The whole system becomes a minefield of conditional logic.
Shifting Left: Policy as Code
The only sane path forward is to treat policy as code. Stop interpreting legal documents and start writing rule engines. A regulation should be a configuration file in a Git repository, not a memo. Tools like Open Policy Agent (OPA) provide a declarative language, Rego, to define policy. Your application queries the policy engine with a JSON object representing the action and receives a simple allow or deny decision.
Think about a new fair housing rule that restricts ad targeting based on certain demographic data. The old way is to have engineers hunt down every ad-serving module and inject `if` statements. The new way is to update a Rego file. The application code doesn’t change. It just asks the policy engine, “Can I show this ad to this user profile?” The engine, which now contains the new rule, makes the decision.
This architecture decouples the core application logic from the ever-changing mess of regulations. You can test your policies independently. You can audit changes through commit history. Legal can, with some training, read the policy files and verify the logic without needing to read a single line of Python or Java. It forces the abstract legal language into concrete, machine-verifiable logic.
Forcing every piece of user data through a single, rigid compliance schema is like shoving a firehose through a needle. The pressure is immense, and something will eventually break. A decentralized, policy-as-code model allows for multiple, smaller validation points instead of one massive bottleneck.
A Practical Example: Data Deletion Pipeline
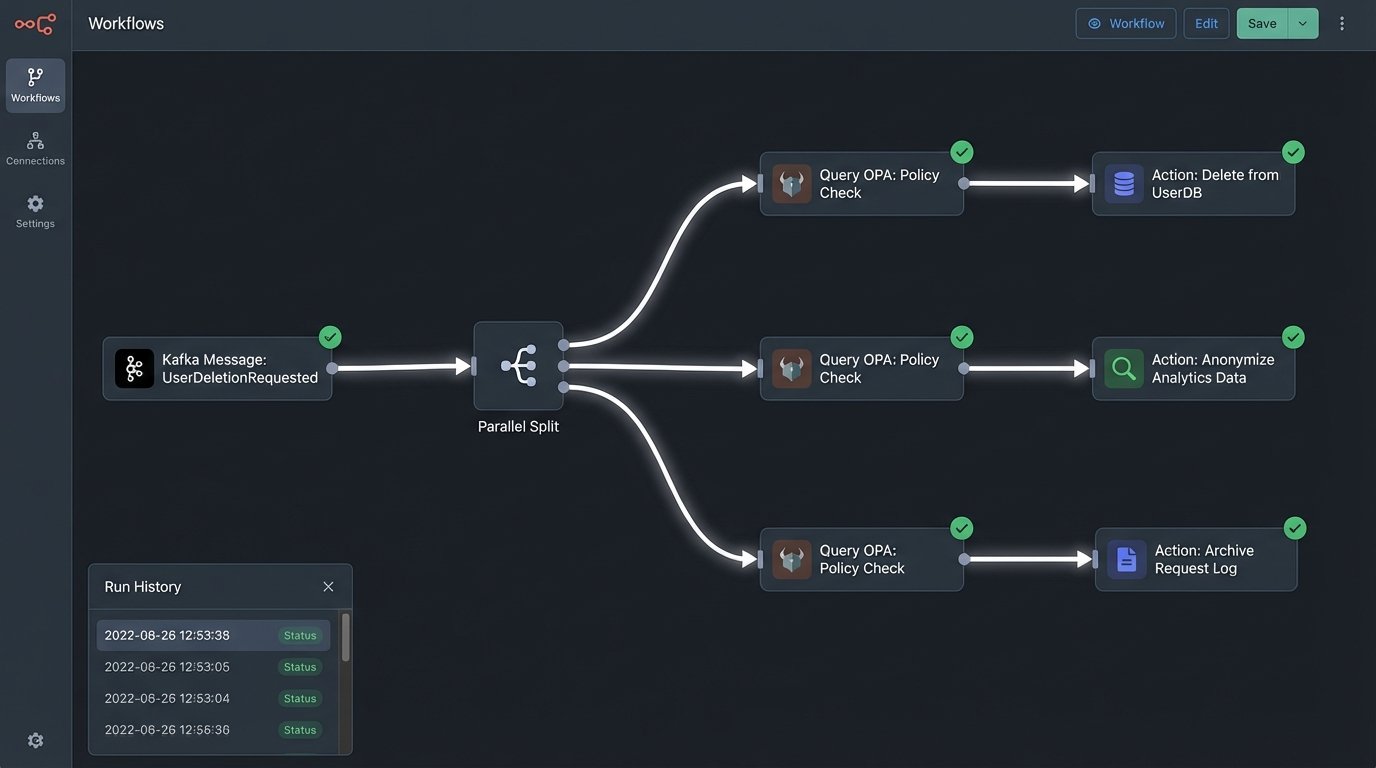
Let’s map out a “right to be forgotten” request using a policy-driven approach. The user submits a deletion request through a front-end portal. This doesn’t trigger a script. It fires an event, `UserDeletionRequested`, onto a message queue like Kafka or RabbitMQ.
A series of microservices listen for this event. Each service owns a specific data domain: the primary user database, the analytics warehouse, the document store, the logging aggregator. Each service has one job: find and purge the user’s data from its domain. Before executing the deletion, each service makes a call to the OPA engine.
The query might look something like this:
{
"input": {
"user_id": "user-12345",
"action": "delete",
"resource": "analytics_event_store",
"data_classification": "PII_level_2",
"retention_policy_override": false
}
}
The policy engine checks if this action is permissible. It might have a rule that certain financial transaction records must be kept for seven years, even if the user requests deletion. In that case, the engine would return `{“allow”: false, “reason”: “legal_hold_active”}`. The service would then move to anonymize the data instead of deleting it, logging the exception. If allowed, it returns `{“allow”: true}` and the service proceeds.
This event-driven, choreographed saga ensures every part of the system handles its piece of the deletion. A central coordinator service tracks the progress, and if any service fails, it can trigger retries or escalate for manual review. You have a distributed, auditable, and resilient system for enforcing a critical regulation.
The Looming Specter of AI Regulation
The next wave is AI regulation. New York City’s Local Law 144, which requires bias audits for automated employment decision tools, is just the start. These laws will demand more than just deleting data. They will require you to prove your models are not discriminatory. This is an order of magnitude harder.
An audit cannot be an afterthought. It has to be built into your MLOps pipeline. When you train a model that predicts tenant default risk or sets rental pricing, your pipeline must automatically perform bias analysis. This means segmenting your training data by protected classes and calculating fairness metrics like demographic parity or equal opportunity. These metrics must be versioned and stored alongside the model itself.
Your feature engineering pipeline needs to be auditable. If your model uses zip codes, you need to be able to demonstrate that the zip code is not just a proxy for race. This requires tooling for feature importance and causal inference, run automatically as part of your CI/CD pipeline for models. A regulator won’t accept “the model is a black box” as an answer.
Consider this simple check you could automate in a Python-based pipeline:
- Data Ingestion: Pull raw applicant data.
- Automated Segmentation: Group applicants by a protected class attribute, for example `ethnicity`.
- Calculate Outcome Rates: For each group, calculate the approval rate from your model’s predictions.
- Logic Check: Compare the approval rate of the minority group to the majority group. The “four-fifths rule” is a common benchmark here. If the minority approval rate is less than 80% of the majority rate, flag the model build as having a potential adverse impact.
This is not a perfect statistical analysis. It is a crude but effective automated guardrail. It prevents a clearly biased model from ever reaching production. It generates a concrete artifact that proves you are performing due diligence. When the auditor comes, you don’t give them a memo. You give them a link to a dashboard showing the bias metrics for every model you’ve ever deployed.
MLS Rules are Just Another Policy Set
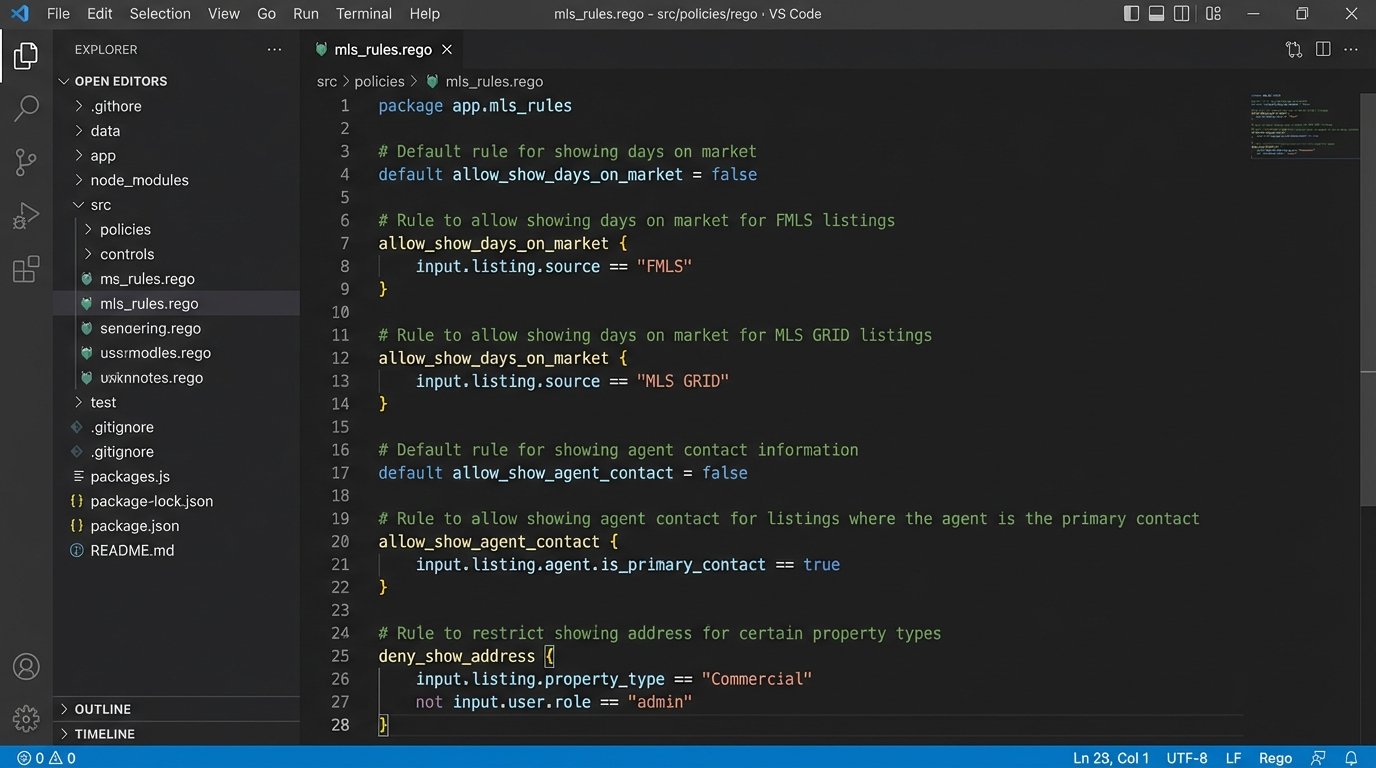
This isn’t just about government regulation. The same architectural patterns apply to the private, contractual rules set by hundreds of MLS boards. Each MLS has its own unique rules about data display, usage, and refresh rates. Hard-coding this logic for each MLS is a recipe for a maintenance nightmare. One rule change from one board forces a new code deployment.
Treating MLS rules as policy is the better approach. Create a policy file for each MLS feed. When your front-end goes to display a listing, it queries the policy engine: “Can I show the ‘days on market’ field for a listing from the FMLS feed?” The engine, having loaded the FMLS policy, provides the answer. This lets you update compliance with a simple configuration change, not a full release cycle.
This architecture is more complex to set up initially. Building out a robust policy engine and refactoring applications to query it is not a trivial task. It requires a significant upfront investment in platform engineering. But the alternative is a slow, reactive system that will eventually collapse under the weight of its own special-case logic.
The cost of non-compliance is no longer just a potential fine. It’s a direct threat to your system’s stability and your team’s velocity. Regulations are not going away. They are only going to become more numerous and more technical. Engineering teams that continue to treat compliance as someone else’s problem will be perpetually stuck in a reactive loop, patching systems instead of building them. Those that treat regulation as a systems design problem will build more resilient, auditable, and ultimately faster-moving platforms.