
Change management is a term invented to sell consulting hours. For engineers, it means one thing. How do we swap a critical piece of infrastructure without causing a production outage and getting paged at 3 AM? The goal is not a smooth transition. The goal is a survivable one. Forget the PowerPoint decks and focus on the rollback scripts. The new tool is guilty until proven innocent.
The Pre-Implementation Interrogation
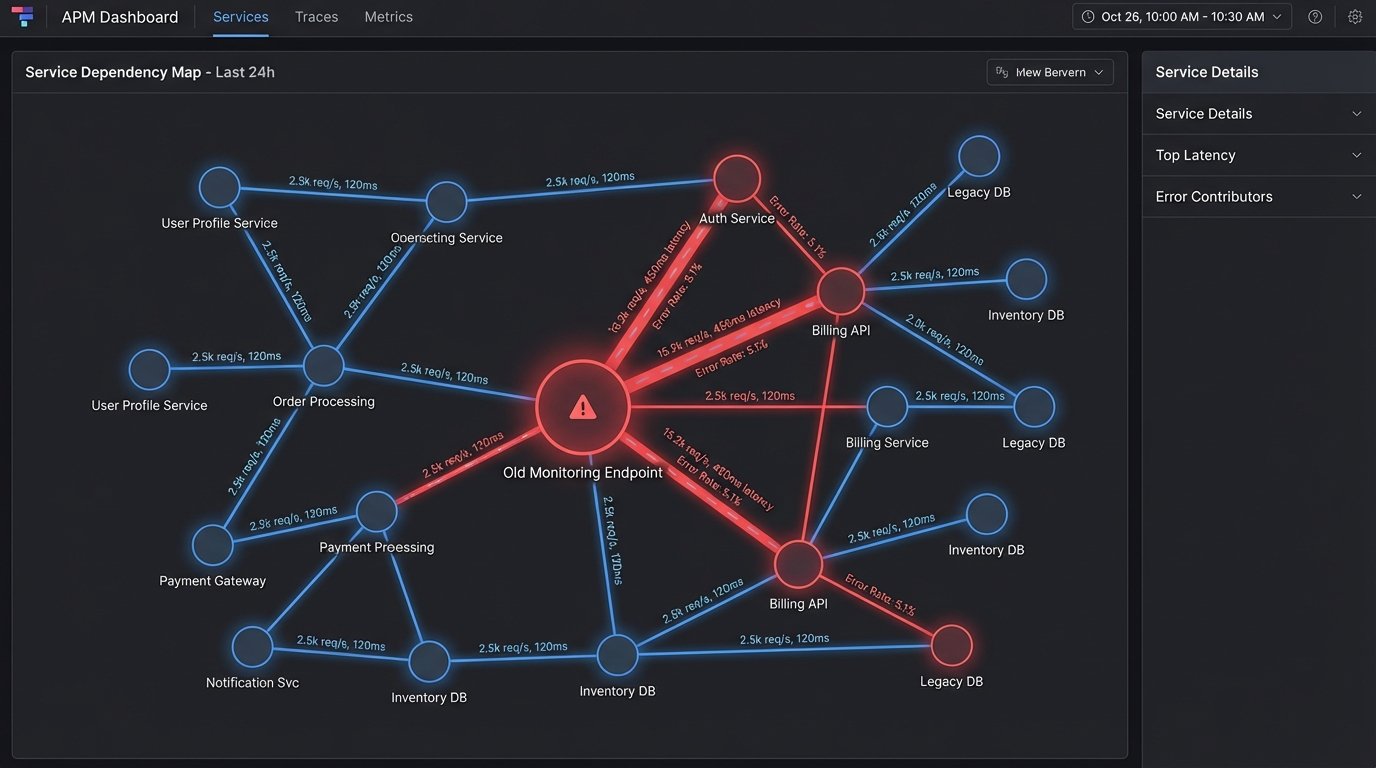
Before you write a single line of integration code, you have to dissect the current state. This is not a high-level overview. This is a forensic audit. You need to know which forgotten cron job in a dusty EC2 instance pings that old monitoring endpoint you want to deprecate. Failure to do this initial work guarantees failure in production.
Dependency Mapping is Non-Negotiable
Every team will swear they are not using the old system. They are lying. Not maliciously, but they have forgotten about the bash script their former intern wrote three years ago that still runs every hour. You must map every single inbound and outbound connection, every API call, and every data dependency tied to the tool you plan to replace. Use network flow logs, APM traces, and raw socket inspection. Trust nothing but the data packets themselves.
This is the part where you discover your core billing process relies on a side effect of the old tool’s buggy API.
Quantify the Failure Modes
The new tool will fail. Your job is to predict how. Will its API buckle under concurrent requests? Does its agent consume too much CPU on your application hosts? Does its data format differ in a subtle but catastrophic way from the old tool? Build a threat model specific to the integration points. Identify every potential point of failure and assign it a blast radius. This will inform your entire rollout strategy.
Speculation is cheap. A staging environment that mirrors production is not.
Script the Rollback Before the Rollout
This is the single most critical step. Everyone gets excited about writing the code to enable the new thing. The senior engineer writes the code to disable it in under five seconds. Your rollback plan cannot be “log into the console and click some buttons.” It must be a fully automated, single-command script. This script should handle DNS changes, feature flag toggles, service restarts, and database state reversions if necessary.
Test the rollback script more than you test the rollout script. Your on-call self will thank you.
Execution: Containment and Control
A big bang rollout of a new infrastructure tool is professional malpractice. The process must be gradual, observable, and instantly reversible. You are performing surgery on a living system. You need to control the bleeding at every step.
Isolate the Blast Radius
The first deployment of the new tool should touch the least critical part of your system. A staging environment is obvious, but even in production, you can isolate. Use a canary deployment model, targeting a small percentage of traffic or a single application pod. If the new tool has agents, deploy them to a single, non-essential node. The goal is to see it fail in a contained environment where only you notice.
You want the explosion to happen in a cardboard box, not in the data center.
Data Migration is a Trap
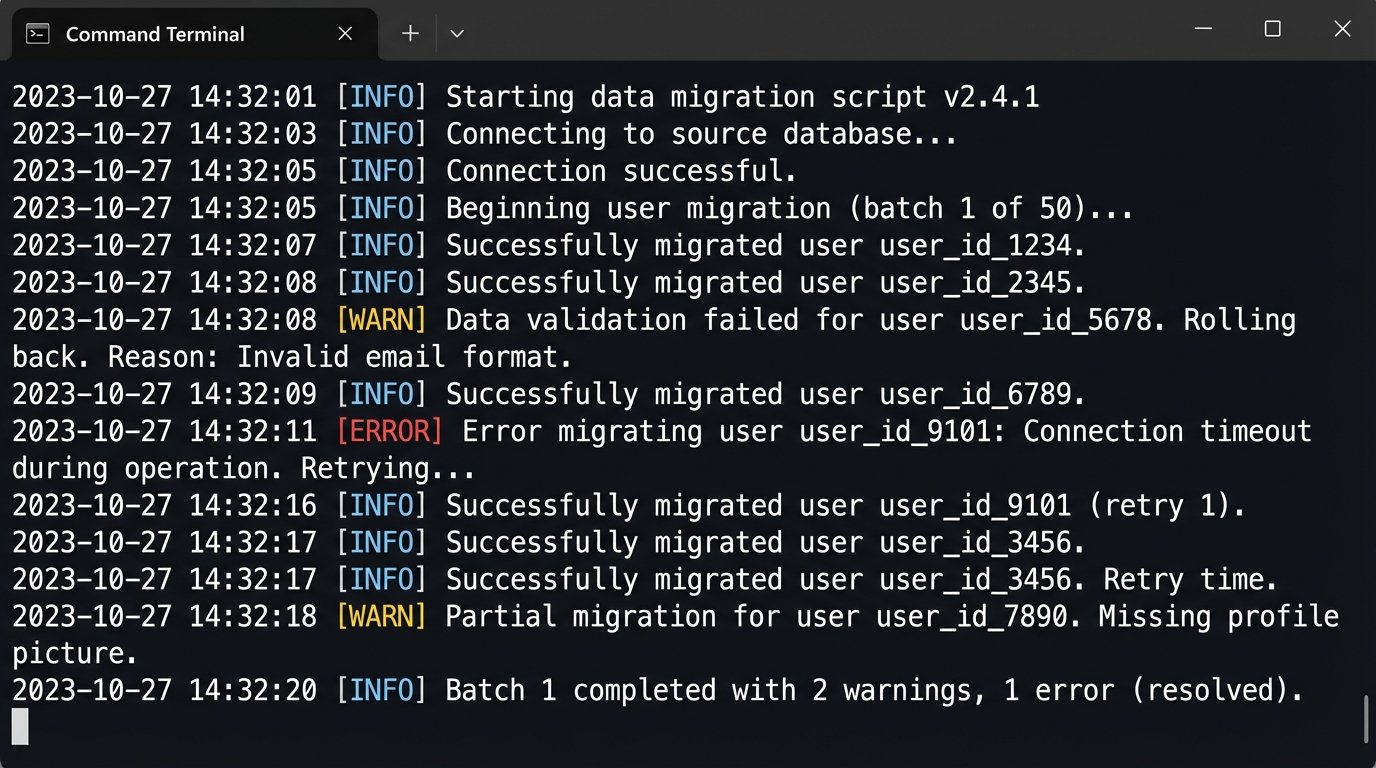
Every vendor promises a seamless data import process. It never is. The schemas will not match. The data types will be wrong. The timestamps will lose their time zone information. You will have to write your own extraction, transformation, and loading (ETL) scripts to bridge the old data format to the new one. Expect to spend 80% of your time on this data plumbing.
This part of the project feels like trying to shove a firehose through a needle. It’s a slow, high-pressure mess.
Your script needs to be idempotent and retryable. You will run it hundreds of times as you discover new edge cases in the old data. Logic-check everything. Does the record count match? Did you correctly map enumerated types? A single bad entry can corrupt the new system’s state. You must validate the data post-injection, comparing a statistically significant sample of records from the old and new systems.
# This is a conceptual example, not production code.
# Think about the logic, not the syntax.
import old_system_api
import new_system_api
import data_transformer
def migrate_user_data(user_id):
"""
Fetches, transforms, and injects data for a single user.
Includes validation checks post-injection.
"""
try:
old_data = old_system_api.get_user(user_id)
if not old_data:
print(f"User {user_id} not found in old system.")
return False
# The transformation logic is where the real pain is.
new_data = data_transformer.convert_user_schema(old_data)
# Force injection into the new system.
injection_id = new_system_api.create_user(new_data)
if not injection_id:
print(f"Failed to inject user {user_id} into new system.")
return False
# Critical validation step.
verify_data = new_system_api.get_user(injection_id)
if not data_transformer.validate_migration(old_data, verify_data):
print(f"Data validation failed for user {user_id}. Rolling back.")
new_system_api.delete_user(injection_id) # Attempt rollback
return False
print(f"Successfully migrated user {user_id}.")
return True
except Exception as e:
print(f"Error migrating user {user_id}: {e}")
# Implement more specific error handling and dead-letter queues here.
return False
Post-Implementation: Hardening and Decommission
Getting the new tool to run is not the end. It’s the beginning of a new set of operational burdens. Now you have to make it survivable, useful, and eventually, the only option.
Gut the Default Configuration
New tools, especially monitoring and security platforms, ship with configurations designed to impress people in sales demos. This means they alert on everything. The default alert rules will immediately flood your communication channels with useless noise, conditioning your team to ignore all alerts. Your first task post-installation is to disable every single default alert. Every single one.
Then, you build a new ruleset from scratch. Each new alert must be tied to a specific Service Level Objective (SLO) or a documented operational procedure. If an alert does not require a human to take a specific, predefined action, that alert should not exist.
Build an API Bridge, Not Just an Integration
Do not allow individual teams to integrate with the new tool’s raw API directly. This creates chaos. Different teams will use different authentication methods, handle pagination differently, and write brittle code based on their narrow use case. You must build a simple, internal client library or API wrapper that exposes a curated set of functions for interacting with the new tool.
This wrapper becomes your policy enforcement layer. You can inject standardized logging, metrics, and rate-limiting logic into this single choke point. It forces everyone to use the tool in a consistent, controlled manner.
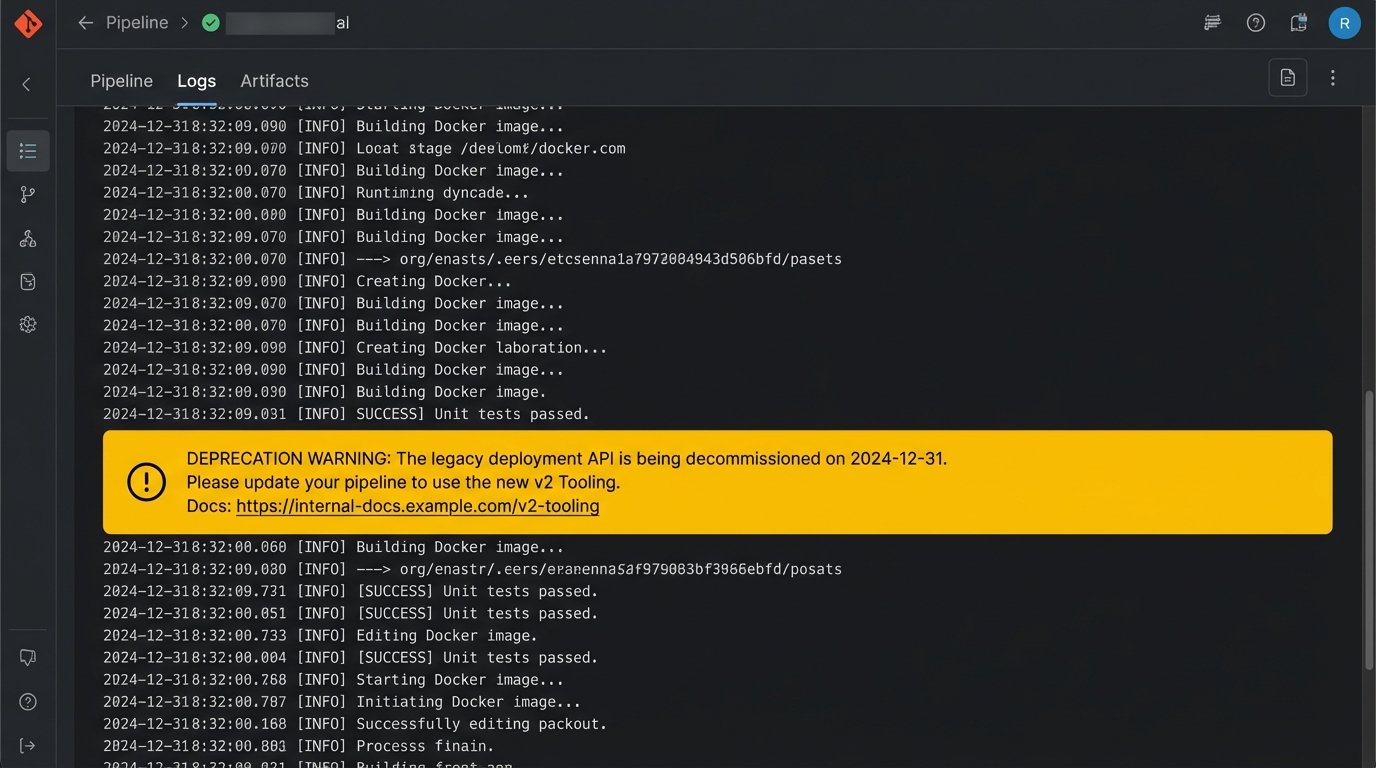
Force Adoption by Deprecating Old Workflows
Engineers will not adopt a new tool out of enthusiasm. They will adopt it when the old way of doing things becomes more painful than learning the new way. Once the new tool is stable, you must start actively dismantling the old workflows. Announce a hard decommissioning date for the old tool’s API. Modify the old CI/CD pipeline to print a warning message with a link to the new tool’s documentation.
Adoption is not a pull process. It is a push process.
Measure Success by What You Delete
The project is not finished when everyone is using the new tool. The project is finished when you can power down the old tool’s servers, delete its DNS records, and revoke its credentials from your secret manager. The final deliverable is a pull request that deletes thousands of lines of code related to the old system. That is the only success metric that matters.
The ultimate goal is to remove complexity, not just relocate it.