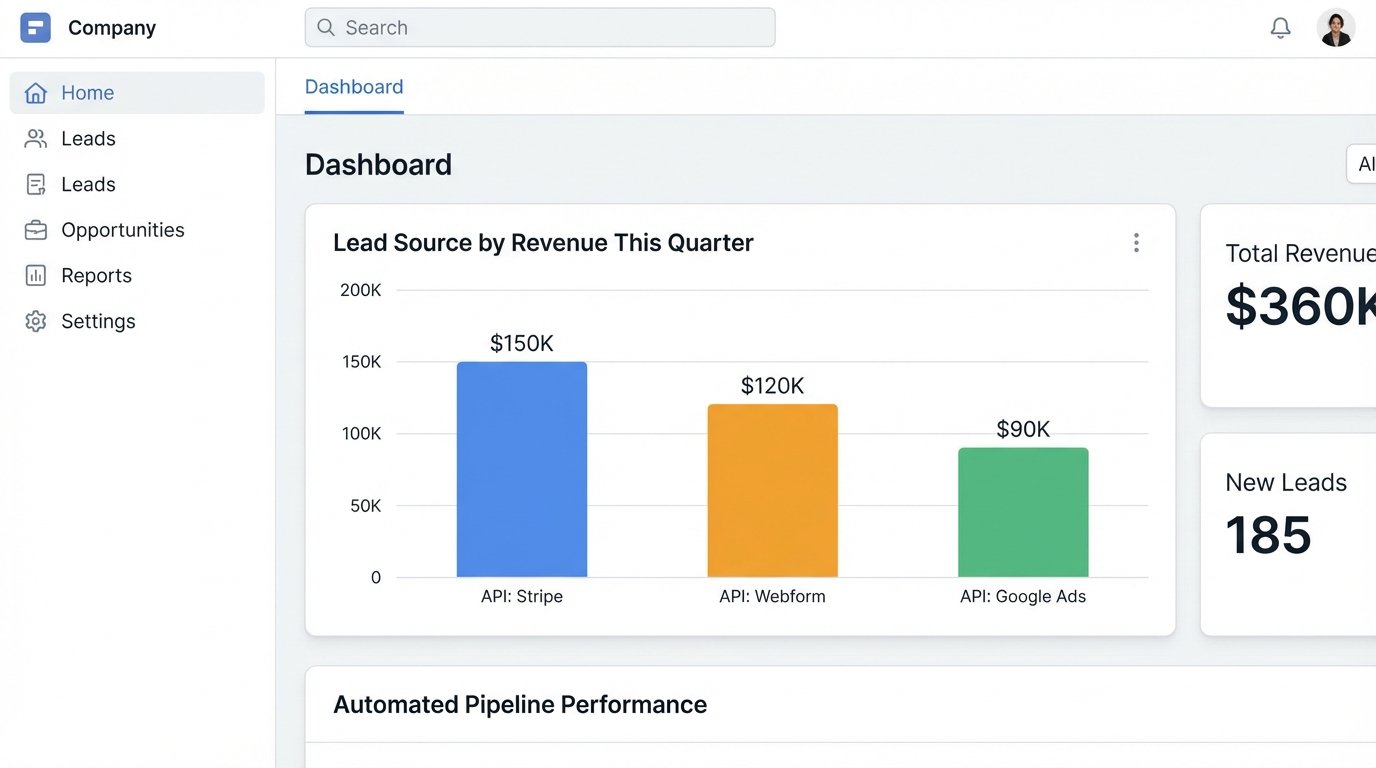
Your CRM Is a Database, Not a Diary
Let’s get one thing straight. Every time a human manually types a customer’s name, email, or deal value into a CRM, you are injecting a potential point of failure directly into the heart of your revenue operations. It’s not an “operational process.” It’s a technical liability. The argument that “we need a human touch” is a flimsy excuse for a poorly architected data pipeline.
A CRM’s primary function is to be a system of record, a state machine that reflects the ground truth of your client interactions. It fails at this the moment its accuracy depends on someone’s typing speed or memory. Data entered manually is data you cannot trust. It’s inconsistent, it’s latent, and it pollutes every report and subsequent automation you try to build on top of it.
The entire model is backward. Sales reps shouldn’t be data entry clerks. They should be closing deals, and the systems should be recording the events for them, automatically, as they happen.
The Myth of “Complex Workflows”
The most common pushback is the complexity argument. “Our sales process is unique.” “We have too many custom fields.” This thinking treats the symptom, not the disease. Your workflow isn’t complex, your data capture is undisciplined. Instead of hammering data into the CRM post-facto, you need to capture it at the source and pipe it in cleanly.
The source is never the sales rep’s keyboard. The source is the web form they filled out, the Stripe payment they made, the Calendly meeting they booked, or the DocuSign contract they signed. Each of these events generates a structured data payload, usually a JSON object, that is a thousand times more reliable than manual entry.
This isn’t about buying another expensive platform. It’s an architectural shift. You stop treating the CRM as the starting point and start treating it as the destination.
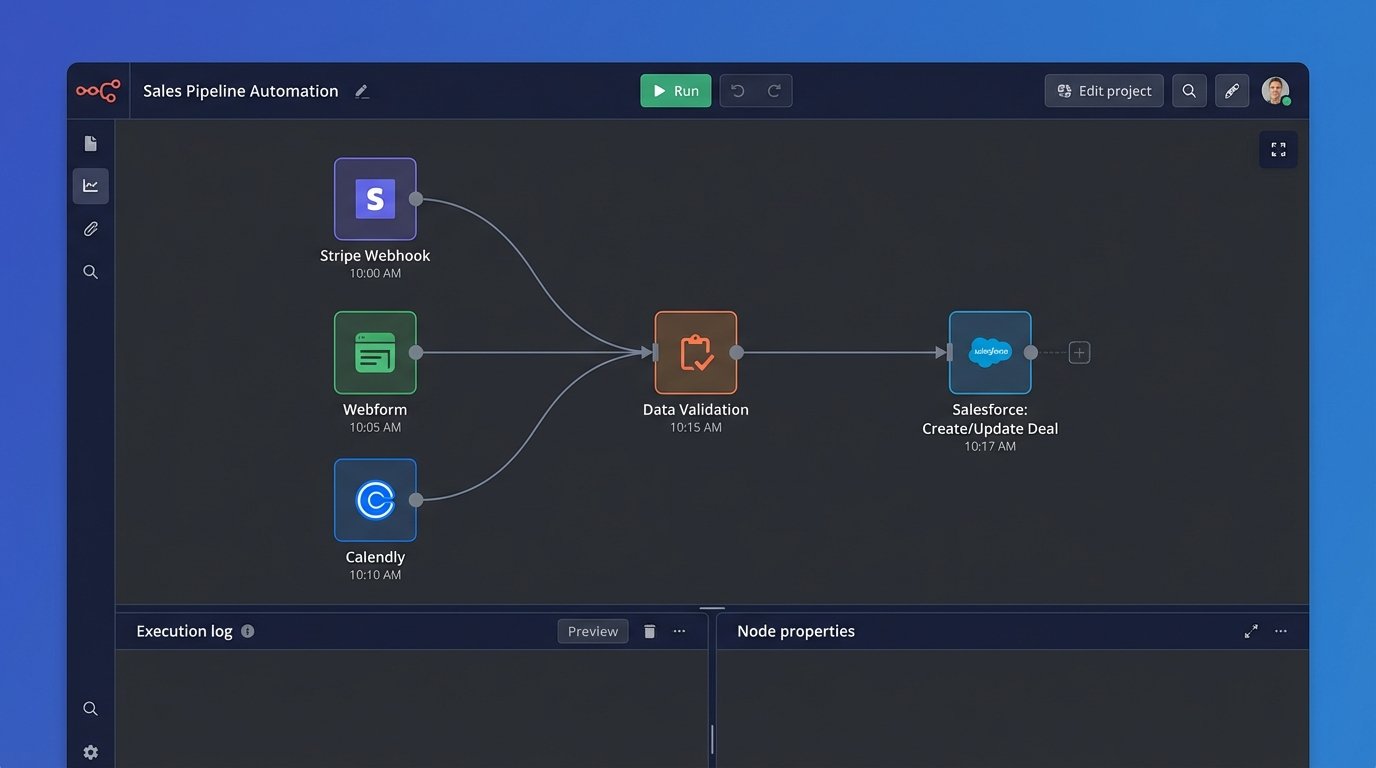
Building the Pipeline: Webhooks and Middleware
The foundation of a zero-entry CRM is the webhook. It’s the digital nervous system for your business events. When a customer pays an invoice, Stripe doesn’t send you an email. It fires a `charge.succeeded` webhook containing every piece of data you need. Your job is to catch it.
Here’s a typical payload from a contact form submission. This is your ground truth.
{
"submission_id": "a4b1c2d3-e4f5-g6h7-i8j9-k1l2m3n4o5p6",
"timestamp": "2023-10-27T10:00:00Z",
"form_name": "Enterprise Contact",
"data": {
"first_name": "Alex",
"last_name": "Chen",
"company_email": "alex.chen@techcorp.io",
"company_name": "TechCorp Global",
"deal_size_estimate": 50000,
"utm_source": "google",
"utm_medium": "cpc"
}
}
This payload doesn’t go directly into your CRM. That’s a rookie mistake. Sending raw data straight in is like connecting a firehose to a garden sprinkler. You’ll flood the system with malformed data and blow past API rate limits. The payload first hits a middleware orchestrator, a tool like n8n, Make, or a custom Python script running on a serverless function.
This is where the real work happens. The middleware is the bouncer. It checks the guest list. Does the email exist? Is the company name valid? Should this create a new contact or update an existing one? Your business logic lives here, not scattered across a dozen different apps.
Idempotency: The Rule You Cannot Break
Your automation logic must be idempotent. This is non-negotiable. It means that if you accidentally run the same automation on the same data five times, the end result in the CRM is identical to running it once. Without this, you get five duplicate contacts, five duplicate deals, and a data hygiene dumpster fire.
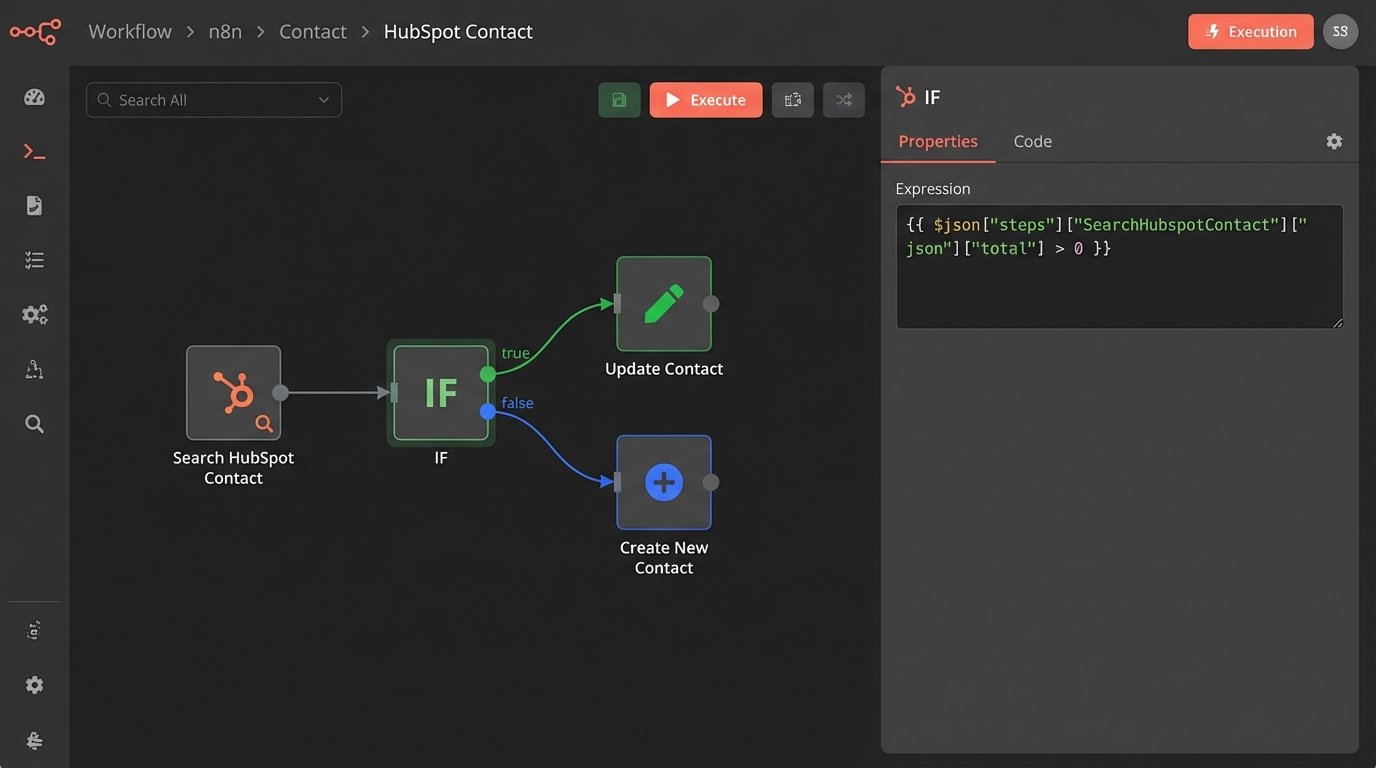
Implementing this means every “create” operation must first be a “search” operation. Before creating a new contact for `alex.chen@techcorp.io`, your script must first query the CRM for that email address. If a record exists, you switch to an “update” operation. If not, you proceed to “create.”
In a tool like n8n, the expression to handle this logic is straightforward. You check the output of a “Search Records” node before deciding which path to take.
{{ $json["steps"]["SearchHubspotContact"]["json"]["total"] > 0 ? "update" : "create" }}
This simple check is the difference between a reliable system and one that creates chaos. Every single endpoint interaction needs this kind of logic-check. It’s tedious to build, but it’s the only way to build a system that doesn’t require constant human cleanup.
Deconstructing the Edge Cases
What about data that doesn’t come from a neat API? A list from a trade show? A forwarded email with a lead? These are exceptions, and they must be treated as such. The goal is to force unstructured data into a structured format as early as possible.
- List Uploads: Don’t upload a CSV directly into the CRM. Upload it to a Google Sheet that triggers an automation. The middleware then processes each row, applying the same validation and search-before-create logic as a webhook.
- Email Parsing: Use an email parsing tool to extract key-value pairs from inbound emails and convert them into a JSON object. This manufactured JSON then follows the exact same path through your middleware as any other webhook. You are standardizing the non-standard.
The trade-off here is the initial setup cost. Building these parsers and validation rules is a front-loaded effort. It’s a wallet-drainer in the short term, requiring significant development hours. But the alternative is paying for that same effort, spread out forever, in the form of manual data cleanup, inaccurate reporting, and failed campaigns based on bad data.
You either pay the iron price up front or you pay the nickel-and-dime tax for eternity.
The Real Bottom Line
Moving away from manual data entry is not about saving a few minutes of a sales rep’s day. It’s a fundamental change that turns your CRM from a passive, often-inaccurate notebook into an active, automated engine for your business.
The data becomes faster. It becomes cleaner. It becomes trustworthy. Your reports start reflecting reality in near real-time. Your automated email sequences trigger based on actual events, not when someone gets around to updating a contact stage. You stop guessing and start operating on validated information.
So, stop “optimizing” your manual entry process. There is nothing to optimize.
Gut it. Automate the ingestion. Force discipline at the point of data creation. Your P&L will thank you for it.