
Your CRM is a Graveyard for Dead Documents
Every real estate transaction generates a pile of documents. Purchase agreements, disclosures, addendums, inspection reports. The industry standard is to get these signed with an e-signature tool, download the flattened PDF, and upload it to a CRM or cloud storage. This isn’t a workflow. It’s a digital filing cabinet, and the data inside is effectively dead on arrival. We celebrate a PDF in a Dropbox folder as a victory, when all we’ve done is create a static, un-queryable image of critical information.
The core failure is treating the document as the source of truth. The document is a container, an artifact. The truth is the data inside it: the price, the closing date, the contingency clauses, the buyer’s name. By locking that data inside a PDF, you force manual re-entry into every other system. The agent or an assistant manually types the sales price into the CRM, the closing date into a calendar, and the commission details into an accounting platform. Each keystroke is a potential failure point.
This manual data-shuttling is a slow-motion disaster. It introduces errors that cascade through the transaction lifecycle, leading to compliance violations, incorrect commission calculations, and frantic calls to correct a closing statement. We’re putting astronauts on the moon while the real estate industry is still hand-cranking the engine. The entire process is brittle, expensive, and an insult to engineering principles.
The Illusion of Automation with Zapier and Fillable PDFs
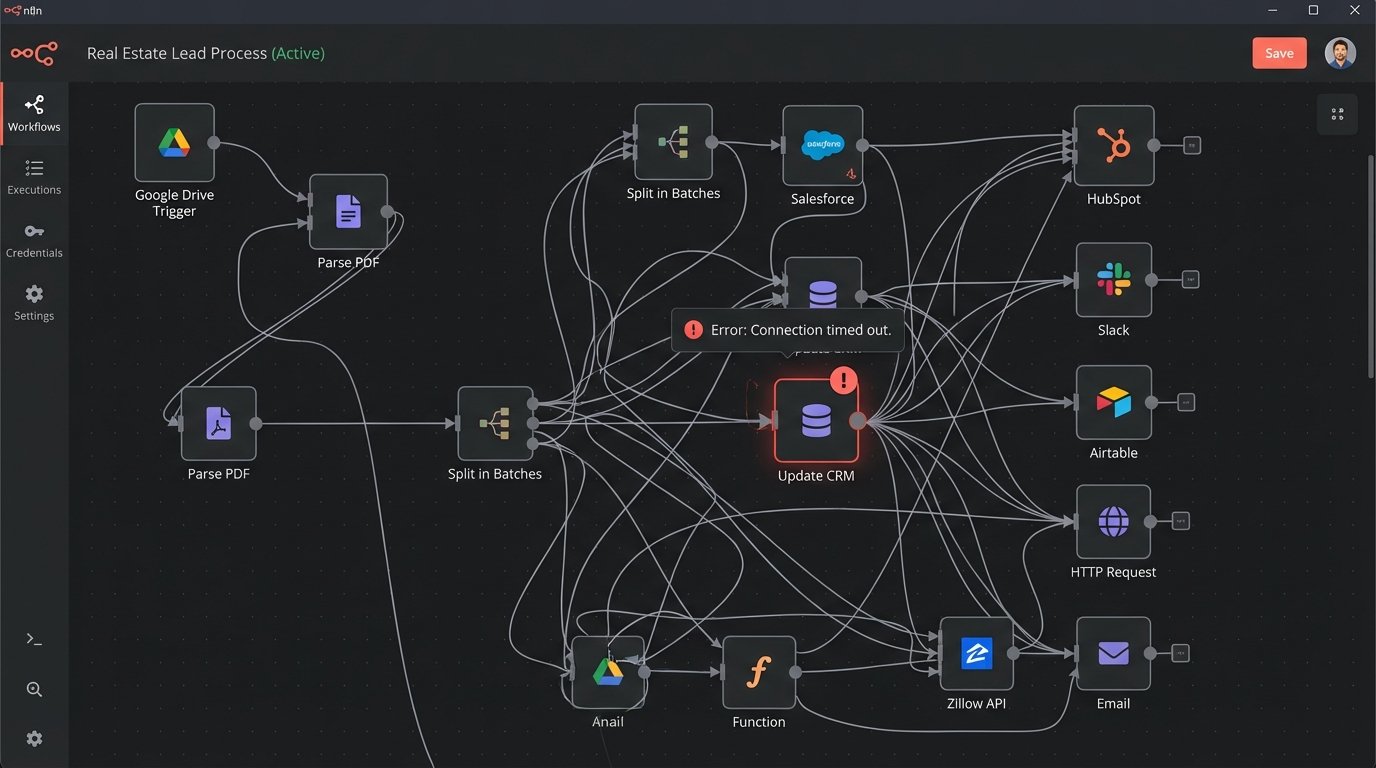
Many teams think they’ve solved this. They build a multi-step Zap that triggers when a file is added to a Google Drive folder. They use fillable PDFs and believe they’ve achieved some high level of sophistication. This is a facade. A Zapier connection that parses an email for a PDF attachment is a weak link, not a robust pipeline. It’s a consumer-grade tool being forced into a commercial-grade problem, and it breaks the moment a sender changes their email subject line.
Relying on fillable PDF fields is also a trap. You’re dependent on the creator of the document using the correct field names and types. When the local real estate board updates its standard purchase agreement and renames a field from `buyer_name` to `buyer_1_name`, your entire automation chain snaps. You won’t know it failed until a transaction is missing critical data hours or days later. This is reactive, fragile engineering.
These systems feel like progress but create a maintenance nightmare. You end up with a dozen disconnected, single-purpose automations that require constant monitoring. It’s the technical equivalent of holding a leaking pipe together with duct tape. It might hold for a week, but it’s going to flood the basement eventually.
A Shift in Architecture: Data First, Documents Second
The only sustainable path forward is to invert the model. Stop thinking about documents and start thinking about structured data. The transaction process should begin with a single, clean source of data, not a document. This could be a web form, a direct API endpoint, or an internal application. This initial data capture creates a structured object, typically JSON, that represents the entire transaction. This object becomes the immutable source of truth.
From this central JSON object, everything else is generated. The purchase agreement is dynamically populated by mapping JSON keys to template variables. The CRM record is created via an API call, pushing validated data directly into the correct fields. The calendar invite for the closing date is generated and dispatched. The document is now a disposable output, a snapshot of the true data state at a specific moment. If a correction is needed, you update the source JSON object and regenerate the artifacts. You are not editing a PDF, you are correcting the source data.
This approach transforms the workflow from a series of manual, error-prone steps into a deterministic, repeatable process. Data integrity is enforced at the point of entry, not discovered three weeks later by an auditor. It’s the difference between building a bridge with a precise blueprint versus trying to glue a pile of rocks together.
Ingesting and Validating Transaction Data
The entry point is the most critical stage. If you can control the data capture, you can control the entire system. Instead of emailing a blank PDF to a client, you send them a link to a secure web form. That form’s `onSubmit` event doesn’t email a person; it fires a POST request with a JSON payload to your processing endpoint. This bypasses the entire mess of email parsing and OCR.
The receiving endpoint, whether it’s an AWS Lambda function or a simple Node.js server, has one job: validation. Before any data is committed, it must be logic-checked. Does the closing date occur after the offer date? Is the property address a valid, deliverable address according to the USPS API? Is the sum of all financial figures mathematically sound? This is where you build the guardrails that prevent bad data from ever entering your ecosystem.
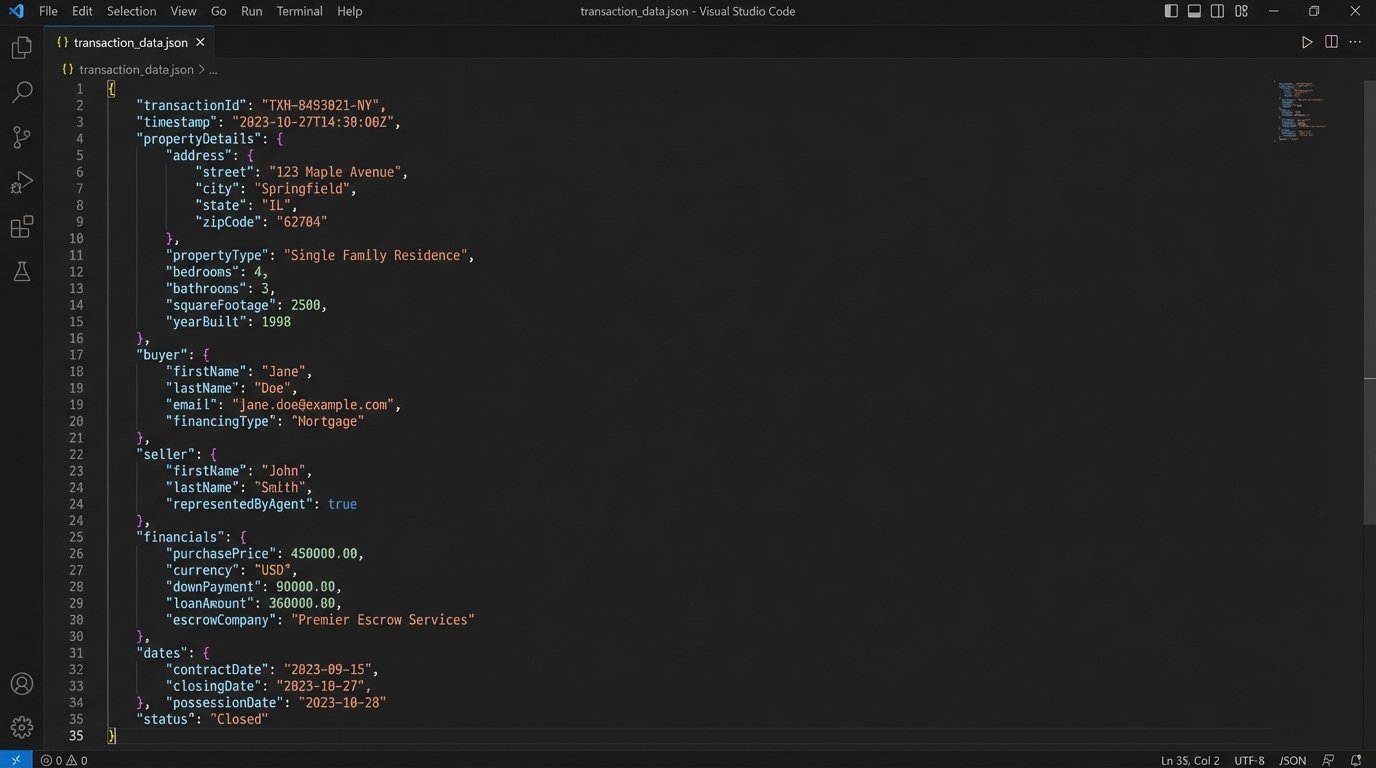
Here is a simplified look at what a transaction data object might look like. Every process downstream consumes this object. Nothing relies on scraping a PDF.
{
"transactionId": "TXN-2024-4C8B1",
"propertyDetails": {
"address": "123 Main St",
"city": "Anytown",
"state": "CA",
"zip": "90210",
"parcelId": "012-345-678"
},
"financials": {
"purchasePrice": 750000,
"earnestMoneyDeposit": 15000,
"currency": "USD"
},
"parties": {
"buyers": [
{"fullName": "John Doe", "email": "john.doe@email.com"}
],
"sellers": [
{"fullName": "Jane Smith", "email": "jane.smith@email.com"}
]
},
"dates": {
"offerDate": "2024-05-20T10:00:00Z",
"acceptanceDate": "2024-05-21T14:30:00Z",
"closingDate": "2024-06-20T17:00:00Z"
},
"status": "pending_validation"
}
This structure is clean, predictable, and machine-readable. It is the antithesis of a scanned disclosure agreement.
From Data Object to Signed Contract
Once your data object is validated, document generation becomes trivial. You need a templating system. This could be a service like Docmosis or PandaDoc, which offer APIs to merge JSON data into pre-designed templates (DOCX, PDF). Or, for more control, you can use a library like `pdf-lib` in a serverless function to construct the documents from scratch. The key is that the process is automated and repeatable. Generating an addendum with a price change is a matter of updating one key in the JSON object and re-running the generation function.
This architecture decouples the data from its presentation. The local real estate board can change the layout of its purchase agreement every year. Your process doesn’t break. You simply update the template file to match the new visual layout. The data mapping, the core logic, remains untouched because it’s bound to your internal data model, not the arbitrary field names on a document.
Trying to force unstructured data from a PDF into the structured world of a database API is like shoving a firehose through a needle. It’s a messy, high-pressure operation guaranteed to lose information. A data-first approach builds the needle and the firehose to the same specification, ensuring a clean, lossless connection every time.
The Integration Layer: Beyond Document Storage
With a trusted JSON object representing the transaction, integration with other systems becomes a straightforward API-to-API conversation. Creating a new deal in the CRM is a single `POST` request. Syncing financials to QuickBooks is another. There’s no screen scraping, no CSV import/export, and no human re-typing information from one browser tab to another. This is where true operational leverage is created.
You can build event-driven workflows. When the `status` field in the JSON object changes from `pending_inspection` to `pending_appraisal`, it can trigger a webhook that notifies the lender’s system automatically. The agent doesn’t need to manually send an email update. The system communicates state changes machine-to-machine, reducing communication latency and the potential for human error.
This is not a simple cost-saving measure. It’s a fundamental change in operational capability that allows a brokerage to handle a higher volume of transactions with greater accuracy and less overhead. It separates the top performers from the rest of the market.
The Necessary Pain of Implementation
This is not a plug-and-play solution you buy off the shelf. It requires a technical investment. You will need someone who understands API integrations, data modeling, and process architecture. Building the initial data model for a real estate transaction is a project in itself. You have to account for countless edge cases and regional variations in compliance. It is a wallet-drainer upfront.
The trade-off is control and reliability versus initial convenience. Off-the-shelf transaction management platforms offer a fraction of this capability but lock you into their ecosystem and their rigid, document-centric view of the world. Building your own data pipeline is more complex initially, but it gives you a durable competitive advantage that cannot be bought.
You can continue to pay staff to be human data-integration hubs, manually copying information between immutable PDFs and siloed software platforms. Or you can build a central nervous system for your transaction data. One path is a dead end. The other is the only viable architecture for an operation that intends to scale.