
The Myth of Osmosis-Driven Development
The central argument for a physical office is knowledge transfer through osmosis. The idea is that proximity breeds innovation. A junior developer overhears a senior architect debating a caching strategy and learns something. This is the story management tells themselves to justify a lease. In reality, this is a chaotic, non-deterministic way to build software. It creates knowledge silos centered on individuals who happen to sit in the right place.
Relying on physical proximity is designing a system with a single point of failure.
We’ve all inherited a project where the core logic was decided during a “quick chat” by the coffee machine. There’s no ticket, no documentation, and the two people who had the chat left the company a year ago. That’s not a collaboration strategy. It’s a liability. An engineering-led approach demands that critical information be durable, searchable, and independent of any single person’s memory or presence in a specific chair.
Forcing this discipline is what remote work does by default. It’s not a bug, it’s a feature.
Forcing Documentation by Default
Remote structures gut the ability to be lazy with communication. You cannot walk over to someone’s desk and interrupt them with a half-formed thought. You are forced to articulate a problem or a specification in writing. This creates an immediate paper trail inside a Slack thread, an email, or preferably, a project management ticket. This asynchronous-first communication pattern is the first step to building a resilient agency.
Every clarification question asked in a Jira ticket is a piece of documentation for the next engineer who hits the same wall.
This process feels slow to people conditioned to synchronous chatter. It requires you to stop, think, and write a clear request. Yet, this upfront time investment prevents hours of future pain. The tribal knowledge that lives in meeting rooms and hallway conversations is like running production on a local development environment. It functions perfectly until the machine it depends on is shut down. When your systems force written specs, you are building a distributed, fault-tolerant knowledge base. It’s less convenient in the moment and infinitely more valuable in the long run.
Tooling is the Central Nervous System, Not a Crutch
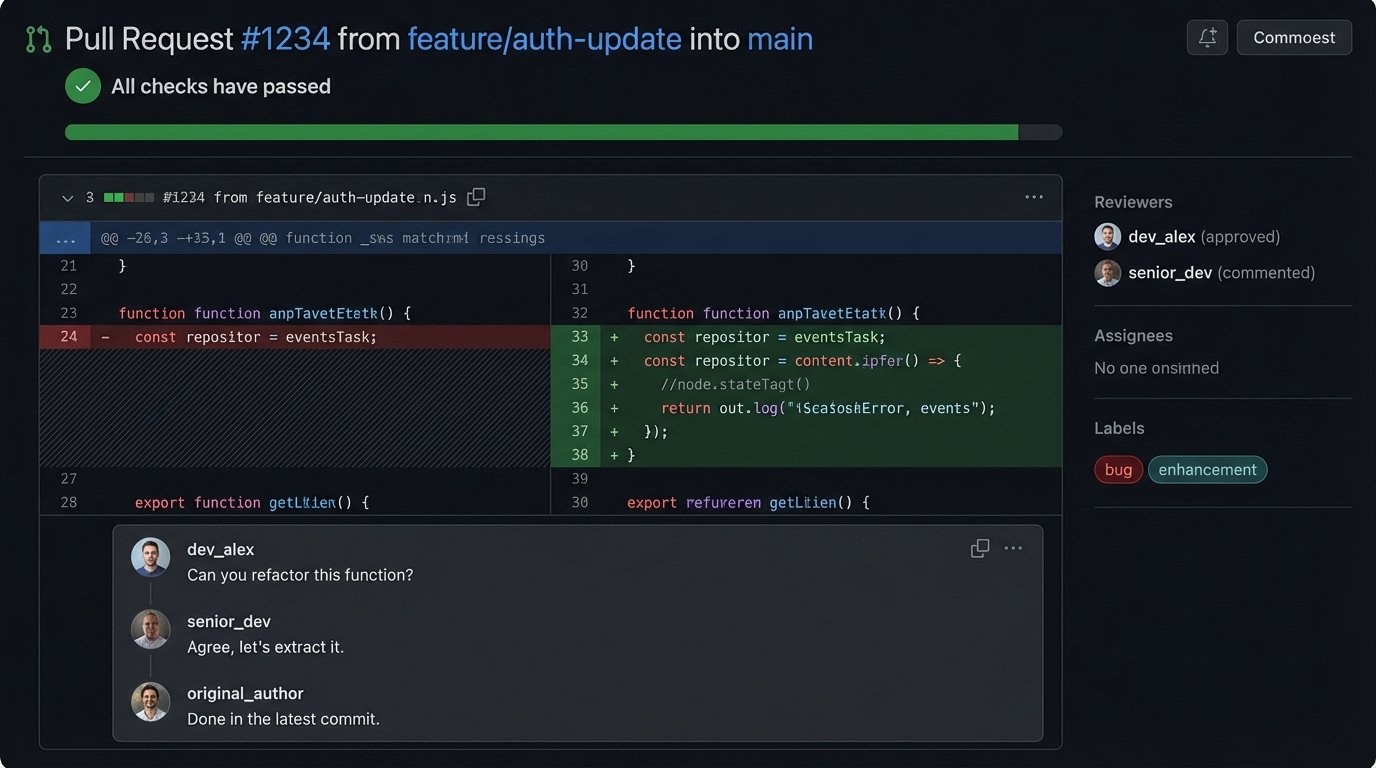
A successful remote agency isn’t built on Zoom calls. It’s built on a deeply integrated toolchain that acts as the source of truth. Git is the undeniable record of what code was changed, by whom, and when. It is the foundation. Every pull request is a conversation, a code review, and a documented decision. If a debate about implementation happens, it happens there, attached permanently to the code it affects. Nothing is lost.
The commit history is the project’s real history book.
Project management platforms like Jira or Asana are not just for managers to track progress. They are structured communication logs. A well-written ticket contains the business case, the technical requirements, the acceptance criteria, and a log of all discussion. It is the complete context for a piece of work. This prevents the classic agency failure where a developer builds exactly what they were asked for, only to find out the client wanted something else entirely. The ticket is the contract. Finally, the CI/CD pipeline is the ultimate arbiter. It is the impartial machine that logic-checks, tests, and validates every contribution. The pipeline doesn’t care about office politics. It only cares if the code works and the tests pass.
Architecting for Asynchronous Workflows
You cannot run a remote team effectively if your processes require everyone to be online at the same time. You have to actively architect systems for asynchronous handoffs. This means breaking down monolithic tasks into smaller, independent units of work that can be picked up by the next person in the chain, regardless of their time zone. This isn’t just a management technique. It’s a technical architecture pattern.
Event-driven systems are the backbone of this. Instead of a person manually telling another person that a task is complete, a system fires an event. A design approval in Figma should trigger a webhook. That webhook carries a JSON payload that hits an endpoint, which then parses the data and automatically creates a new development task in Jira, pre-populated with links to the approved assets. The human interaction is reduced to the single creative decision. The administrative overhead is automated away.
This is shoving a firehose of manual tasks through the needle of automation.
A simple webhook payload might look something like this. It’s just structured data. But this small packet of JSON can kick off an entire workflow, bridging the gap between design and development without a single meeting.
{
"event_type": "DESIGN_APPROVAL",
"timestamp": "2023-10-27T10:00:00Z",
"user": "designer@agency.com",
"project_id": "PROJ-123",
"asset_details": {
"asset_id": "figma-node-456:789",
"asset_url": "https://www.figma.com/file/...",
"version": "2.1",
"approved_for": "development"
},
"metadata": {
"jira_ticket": "PROJ-45"
}
}
This requires an upfront investment in setting up the integrations. But once it’s built, it scales. You can add more designers or developers without increasing the communication overhead proportionally.
The Fallacy of Synchronous Debugging
The other big justification for an office is collaborative problem-solving. “Let’s all get in a room and fix this bug.” This is often the most inefficient way to solve a complex problem. It usually devolves into one person driving while three others offer conflicting suggestions based on incomplete information. It’s a high-stress, low-signal activity.
Good remote engineering teams bypass this by investing heavily in observability.
When a production environment is properly instrumented with structured logging, metrics, and tracing, debugging becomes an asynchronous, data-driven investigation. An engineer can dig into Datadog, New Relic, or Sentry and see the exact request that caused the error, the stack trace, and the state of the system at that moment. They can solve the problem with evidence. This is far more effective than trying to reproduce a vague bug report based on a user’s description. Remote work forces this investment because you don’t have the crutch of grabbing the nearest senior dev. You have to build systems that tell you what’s wrong.
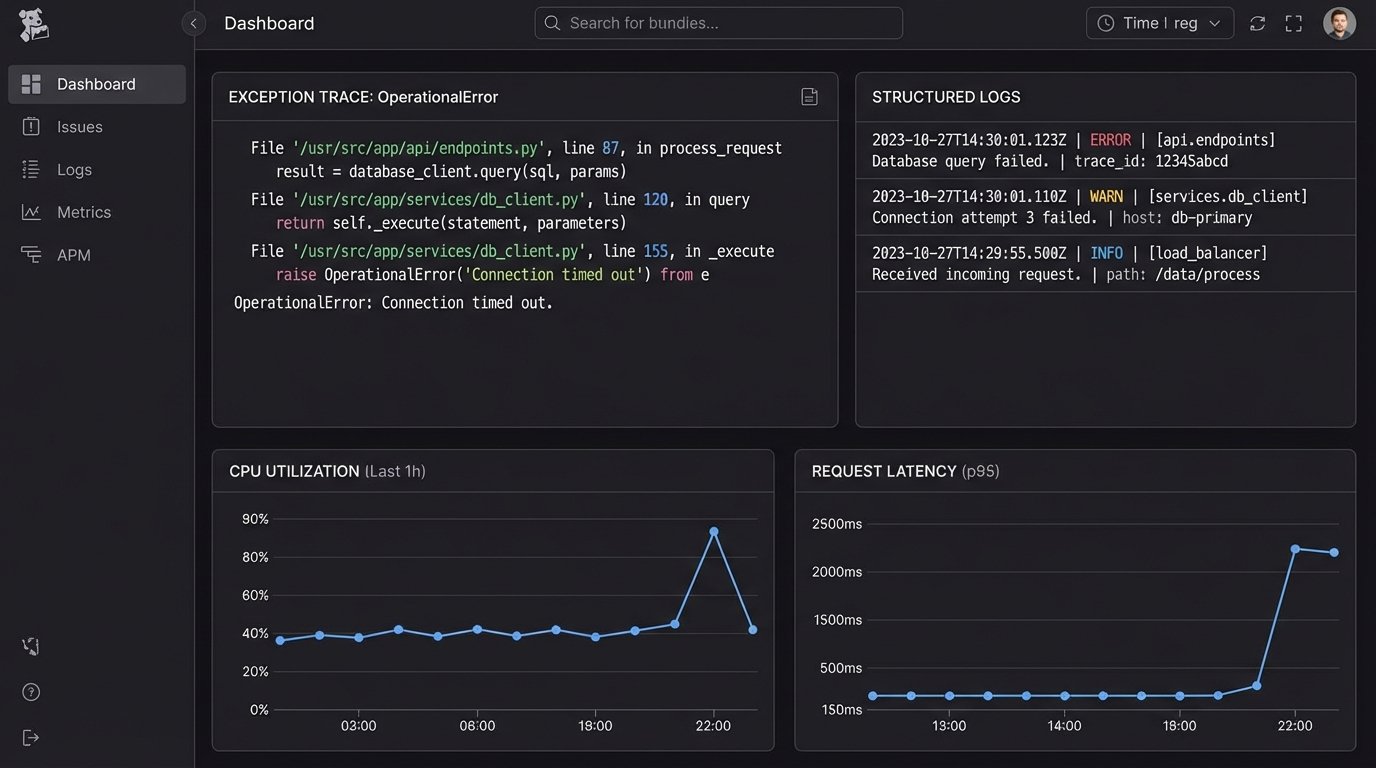
Quantifying Contribution: Moving Beyond “Presence”
An office environment often defaults to rewarding presence over output. Managers see people at their desks and assume work is happening. This “management by walking around” is a poor proxy for actual productivity. It incentivizes looking busy, not being effective. Remote work forces a shift in how contribution is measured. The focus moves to tangible, verifiable output.
The metrics that matter are pull requests merged, tickets closed, system uptime, and test coverage. These are not subjective. They are data points that can be pulled directly from your toolchain’s APIs. We can build simple dashboards that show cycle time for features, from ticket creation to production deployment. This isn’t about creating a surveillance state. It’s about identifying bottlenecks in the process itself. If pull requests are sitting for days without review, that’s not a person problem. It’s a process problem that needs to be fixed.
A small script can pull data to start this analysis. It’s not complex to check how long pull requests have been open in a repository.
import requests
import json
from datetime import datetime, timezone
# Basic example. Error handling and auth are stripped for clarity.
REPO_OWNER = 'your-org'
REPO_NAME = 'your-repo'
GITHUB_TOKEN = 'your_personal_access_token'
URL = f"https://api.github.com/repos/{REPO_OWNER}/{REPO_NAME}/pulls"
HEADERS = {'Authorization': f'token {GITHUB_TOKEN}'}
response = requests.get(URL, headers=HEADERS)
pull_requests = response.json()
now = datetime.now(timezone.utc)
for pr in pull_requests:
pr_title = pr['title']
created_at_str = pr['created_at']
created_at = datetime.fromisoformat(created_at_str.replace('Z', '+00:00'))
age = now - created_at
if age.days > 2:
print(f"STALE PR: '{pr_title}' has been open for {age.days} days.")
This simple check surfaces process failures automatically. That’s more valuable than any manager’s gut feeling about who is “working hard.”
The Inescapable Overhead
This approach is not without its costs. Onboarding a new engineer into a remote-first system is a heavy lift. It requires a meticulously documented process that can take weeks to build. You can’t just sit them next to a senior and hope for the best. The entire process, from setting up a local environment to understanding the deployment pipeline, must be written down and maintained.
It’s a front-loaded investment in operational excellence.
Spontaneous creativity sessions also change. You can’t just grab a whiteboard. Brainstorming has to be more deliberate. It requires a scheduled call, a clear agenda, and a tool like Miro to facilitate. This adds structure, which can feel restrictive, but it also ensures that the output is captured and actionable. The biggest cost is the toolchain itself. A solid stack of GitHub, Jira, Slack, an observability platform, and various automation services is a significant recurring expense. This wallet-drainer, however, is almost always cheaper than the square footage, insurance, and utilities required for a physical office.
The transition to a remote-first, systems-driven operation is not a concession. It is an upgrade. It forces an agency to replace fragile, human-dependent workflows with resilient, documented, and automated processes. You trade the chaotic ambiguity of the office for the logical rigor of a well-architected system. This is not about where your people sit. It’s about building an agency that can actually scale.